






大家好,在今天这个数据复杂性日益增长和高维信息丰富的时代,传统数据库在高效处理和提取复杂数据集方面已显得捉襟见肘。向量数据库,作为一项应运而生的技术创新,成功解决了数据领域在不断扩展过程中所面临的挑战。
1.向量数据库概述
向量数据库因其高效存储、索引和搜索高维数据点(即向量)的独特能力,在多个领域逐渐凸显其重要性。这些数据库专门设计来处理以多维空间中的向量形式表示的数据条目。向量可以涵盖各种信息,包括数值特征、文本或图像的嵌入,甚至是分子结构等复杂数据。
为了更直观地理解向量数据库,下面用一个2D网格来形象化其工作方式。在这个网格中,一个轴代表动物的颜色(棕色、黑色、白色),另一个轴代表动物的大小(小、中、大)。
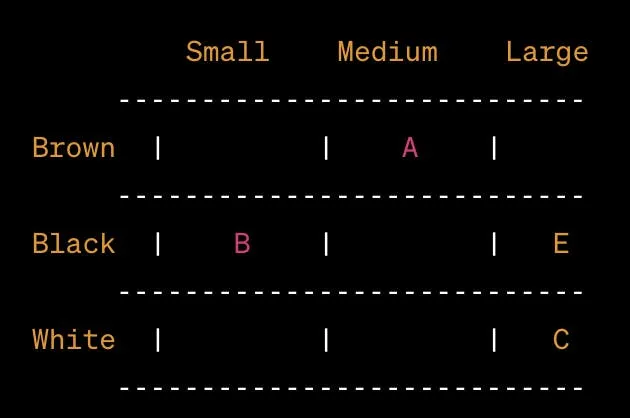
在这个表示中:
-
图像A:棕色,中等大小
-
图像B:黑色,小尺寸
-
图像C:白色,大尺寸
-
图像E:黑色,大尺寸
可以想象,每张图片都是根据其颜色和大小属性在网格上对应的一个点。这个简化的网格模型揭示了向量数据库的可视化表示方式。实际的向量空间拥有更多的维度,并采用更为复杂的搜索和检索技术。
2.向量存储机制
向量数据库通过向量嵌入技术存储数据,将各类对象(如商品、文档或数据点)映射为多维空间中的向量。每个对象都对应一个向量,该向量捕捉了对象的多样特征或属性。设计这些向量的目的是,相似对象在向量空间中彼此靠近,而不相似的对象则相隔较远。
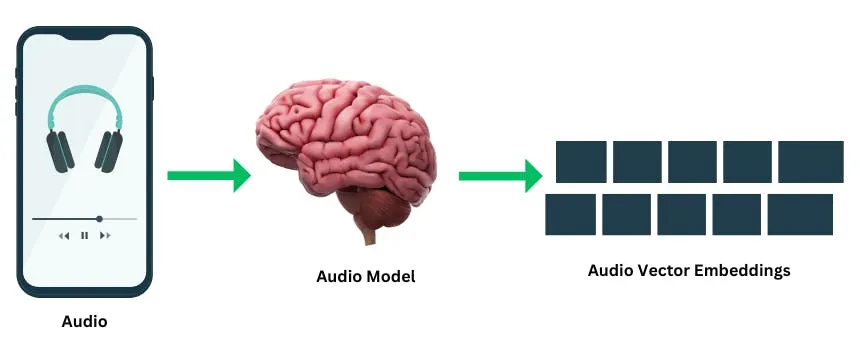
可以将向量嵌入比作一种特殊的编码,描述了对象的关键特征。例如,如果要表示不同类型的动物,并希望相似的动物具有相似的编码,那么猫和狗可能拥有相近的编码,因为它们共同特征,比如有四条腿和毛等。相反,鱼和鸟等差异较大的动物则会有较大的编码差异。
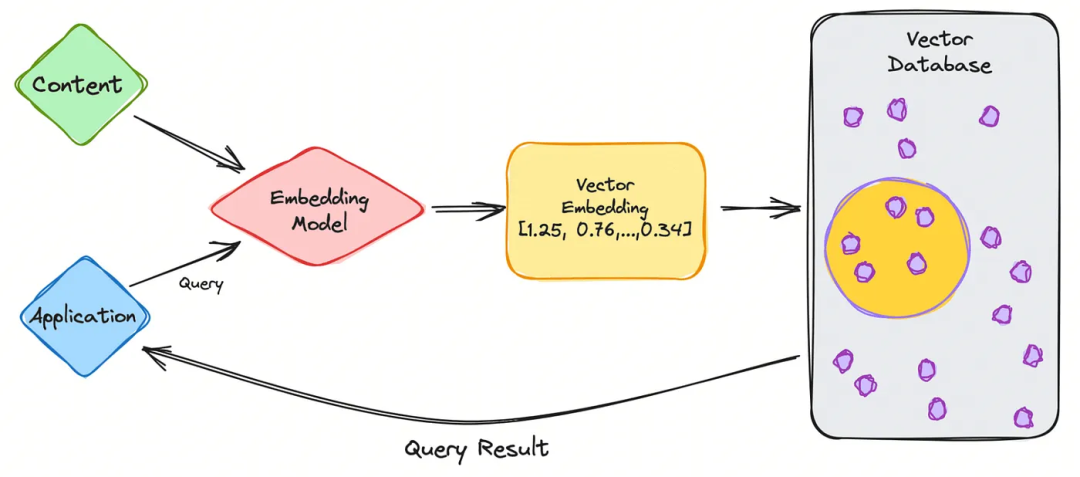
在向量数据库中,这些嵌入被用来存储和组织对象。当用户想要寻找与特定查询相似的对象时,数据库会分析这些嵌入,计算查询嵌入与其他对象嵌入之间的距离,从而迅速定位与查询最为相似的对象。
以音乐流媒体应用为例,歌曲可以通过捕捉音乐特征(如节奏、流派、使用的乐器)的嵌入被表示为向量。当用户搜索与他们最喜欢的曲目相似的歌曲时,应用的向量数据库会通过比较这些嵌入来推荐高度匹配用户口味的歌曲。
总之,向量嵌入是一种将复杂对象转化为数值向量的方法,能够捕捉对象的特征。向量数据库利用这些嵌入,根据它们在多维空间中的位置,能够高效地搜索和检索出相似或相关的对象。
3.工作流程
a.用户查询:
-
向ChatGPT应用程序输入问题或请求。
b.嵌入创建:
-
应用程序将输入转换为一个紧凑的数值形式,即向量嵌入。
-
这个向量嵌入数学化地捕捉了用户查询的核心含义。
c.数据库比较:
-
将生成的向量嵌入与数据库中存储的向量嵌入进行比较。
-
通过计算相似性,系统能够识别出与查询内容最相关的嵌入。
d.输出生成:
-
数据库据此生成一个响应,该响应由与查询含义高度匹配的嵌入组成。
e.用户响应:
-
系统将包含与这些嵌入相关联的相关信息的响应发送回给用户。
f.后续查询:
-
当用户发起新的查询时,嵌入模型会创建新的向量嵌入。
-
这些新嵌入用于在数据库中检索相似的向量嵌入,从而与原始查询建立新的联系。
4.相似性度量
向量数据库采用多种数学技术来衡量向量之间的相似度,其中一种常见方法是余弦相似性。
以在搜索引擎中搜索“世界上最好的板球运动员”为例,搜索结果的生成过程包含多个步骤,其中余弦相似性是一个关键环节。
在这一过程中,搜索查询的向量表示与数据库中所有运动员档案的向量表示通过余弦相似性进行比较。两个向量的相似度越高,其余弦相似性得分就越高。
说明: 以上仅为示例。实际上,搜索引擎使用的算法远比简单的向量相似性复杂。它们还会综合考虑用户的地理位置、搜索历史、信息源的权威性等多种因素,以提供更为相关和个性化的搜索结果。
5.应用领域
-
高效的相似性搜索:
向量数据库擅长执行相似性搜索,能够快速找到与查询向量最匹配的向量。这在推荐系统(如寻找相似产品或内容)、图像与视频检索、面部识别以及信息检索等多个应用场景中发挥着重要作用。
-
高维处理:
高维数据的处理一直是传统关系数据库的软肋,因为随着维度的增加,数据点间的距离变得难以界定。向量数据库则专门设计来高效处理这类数据,适用于自然语言处理、计算机视觉和基因组学等高维数据处理密集型领域。
-
机器学习与AI:
向量数据库常用于存储机器学习模型生成的嵌入向量,这些向量能够捕捉数据的核心特征,并用于聚类、分类和异常检测等任务。
-
实时应用优化:
许多向量数据库都针对实时或近实时查询进行了优化,适用于需要快速响应的应用场景,如电商推荐系统、欺诈检测以及物联网传感器数据监控。
-
个性化体验与用户画像:
向量数据库通过深入理解用户偏好,为流媒体服务、社交媒体和在线市场等平台提供个性化体验。
-
空间与地理数据:
向量数据库能有效处理地理信息数据,对地理信息系统(GIS)、位置服务和导航应用至关重要。
-
医疗保健和生命科学:
在医疗领域,向量数据库用于存储和分析遗传序列、蛋白质结构等分子数据,推动药物发现、疾病诊断和个性化医疗的发展。
-
数据融合与集成:
向量数据库能够整合不同来源和类型的数据,为多模态数据分析提供更全面的视角,如结合文本、图像和数值数据。
-
多语言搜索:
向量数据库支持创建多语言的搜索引擎,通过将文本文档在共同空间中向量化,实现不同语言间的相似性搜索。
-
图数据表示:
向量数据库在社交网络分析、推荐系统和欺诈检测等领域中,能够高效地表示和处理图数据。
6.向量数据库在数据时代的战略地位
在现代应用中,随着高维数据量的激增,向量数据库扮演着重要的角色,并且正面临日益增长的市场需求。随着各行各业越来越多地采用机器学习、人工智能和数据分析等技术,高效地存储、搜索和分析复杂数据的需求变得极为迫切。
向量数据库赋予企业强大的相似性搜索能力,支持个性化推荐和精准内容检索,从而能显著提升用户体验并优化决策过程。
向量数据库的应用横跨电子商务、内容平台、医疗保健乃至自动驾驶车辆等多个领域,其需求主要来自于向量数据库处理多样化数据类型和提供实时精确结果的能力。
面对数据复杂性和体量的不断增长,向量数据库以其可扩展性、处理速度和分析准确性,成为挖掘有价值洞见、推动各行业创新的重要工具。


















 2149
2149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











