



 本文探讨了OLAP和OLTP系统在企业数据处理中的角色,OLAP用于复杂分析,支持多维数据分析,而OLTP专注于实时事务处理。两者在数据规模、模型、查询类型和性能需求上存在显著差异,企业通常结合两者以满足运营和决策分析需求。
本文探讨了OLAP和OLTP系统在企业数据处理中的角色,OLAP用于复杂分析,支持多维数据分析,而OLTP专注于实时事务处理。两者在数据规模、模型、查询类型和性能需求上存在显著差异,企业通常结合两者以满足运营和决策分析需求。
大家好,如今企业会从各种来源生成大量数据:客户互动、销售交易、社交媒体等等。要从这些数据中提取有意义的信息,需要能够有效处理、存储和分析数据的系统。
OLAP(联机分析处理)和OLTP(联机事务处理)系统在数据处理中都发挥着举足轻重的作用。OLAP系统使企业能够执行复杂的数据分析并推动业务决策。另一方面,OLTP系统可确保日常运营顺利进行,它们在处理实时交易过程的同时,还能保持数据的一致性。
接下来进一步了解OLAP和OLTP系统,并了解它们之间的主要区别。
OLAP和OLTP系统概述
OLAP(联机分析处理)是一类数据处理系统,旨在便于复杂的分析查询,并从大量历史数据中提供有价值的见解。OLAP系统对于商业智能、数据仓库和决策支持系统等应用至关重要。它们使企业能够分析趋势、发现模式,并根据历史数据做出战略决策。这些系统利用OLAP立方体,这是一个基本组件,可以进行多维数据分析(稍后本文将会介绍OLAP立方体)。
OLTP(联机事务处理)是指为实时事务操作和日常运营任务量身定制的一类数据处理系统。OLTP数据库具有ACID(原子性、一致性、隔离性、持久性)特性,可保证可靠、一致的事务处理。OLTP系统通常用于需要快速并发处理小型、快速和实时事务的应用程序。由于OLTP系统能确保数据始终保持最新和一致,因此非常适合电子商务、银行和金融交易等应用。
OLAP与OLTP的区别
现在已经对OLAP和OLTP系统有了一定的了解,接下来将了解它们之间的区别。
1.系统规模和数据量
OLAP系统通常比OLTP系统要大得多。OLAP系统处理大量的历史数据,通常需要大量的存储容量和计算资源。与OLAP系统相比,OLTP系统处理的数据集相对较小,重点是实时处理和快速响应时间。
2.数据模型
OLAP数据库使用非规范化的数据结构来优化查询性能。通过存储预先聚合的冗余数据,这些系统可以高效地处理复杂的分析查询,无需进行大量的连接操作。非规范化的结构加快了数据检索速度,但可能会增加存储需求。
OLAP系统支持多维数据分析,通常使用星型或雪花型模式实现,其中数据按维度和度量进行组织。所有OLAP系统的基础都是OLAP立方体,它有助于进行多维数据分析。
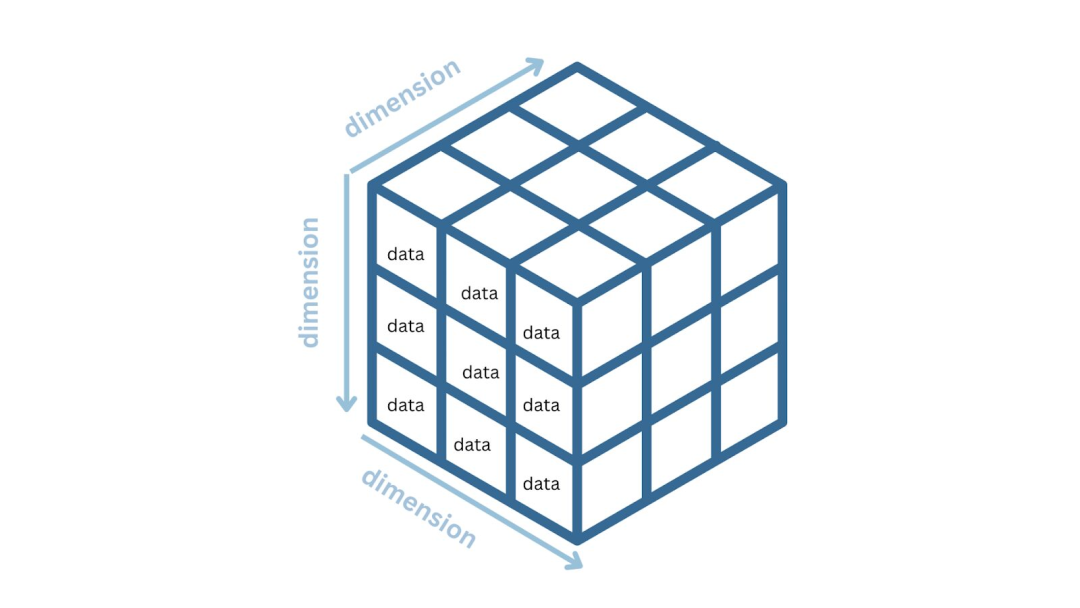
用于多维数据分析的OLAP立方体
OLAP立方体是一种多维数据结构,可将数据组织成多个维度和量度。
-
每个维度代表一个特定类别或属性,例如时间、地理位置、产品或客户。
-
度量是对这些维度进行分析的数值或指标。这些数据通常包括销售收入、利润、销售数量或任何其他相关的KPI(关键绩效指标)。
立方体的多维结构使用户能够从各种角度探索数据,包括钻取、切片、切块和汇总等操作,以便以不同层次和粒度查看数据。
例如,考虑一个包含电子商务公司销售数据的OLAP立方体。该立方体的维度可能包括:
-
时间(月份、季度、年份)
-
地理位置(国家、地区等)
-
产品类别(电子产品、时尚、家用电器等)
一些衡量指标包括销售收入、销售数量和利润。OLAP立方体可让用户通过选择特定的维度(例如查看特定时间段内特定地区的销售收入,或比较不同产品类别的销售情况),从而分析销售绩效。
OLTP数据库采用规范化的数据结构,以尽量减少数据冗余并确保数据完整性。规范化将数据划分为独立的相关表,减少了数据异常的风险,提高了存储效率。
3.查询类型和响应时间
OLAP系统经过优化,能够处理涉及聚合、排序、分组和计算等复杂分析查询。这些查询通常涵盖大量历史数据,并需要大量的计算资源。由于其分析性质,OLAP查询可能需要较长的执行时间。
OLTP系统旨在处理大量的小型、快速和并发的事务性查询。这些查询主要涉及单个记录的插入、更新和删除。OLTP系统侧重于实时数据处理,并确保事务操作的快速响应时间。
4.性能需求
OLAP系统旨在支持复杂的分析查询和多维数据分析。OLTP系统应具有快速的响应时间。它们应该能够支持大量并发事务,同时保持数据的完整性,并减少数据不一致。
最后,本文以表格的形式总结一下OLAP和OLTP系统在迄今为止讨论过的不同功能上的差异:
| 特征 | OLAP | OLTP |
|---|---|---|
| 数据量 | 大容量历史数据 | 小容量实时事务数据 |
| 系统规模 | 远大于OLTP系统 | 远小于OLTP系统 |
| 数据模型 | 为提高性能而去规范化 | 为提高完整性和减少冗余而规范化 |
| 查询类型 | 复杂的分析查询 | 简单的查询 |
| 响应时间 | 执行时间可能更长 | 响应时间更快 |
| 性能需求 | 对数据进行多维分析,对涉及聚合的复杂查询进行优化,以加快检索速度 | 以较低的延迟快速处理实时并发事务 |
总结
简而言之:OLAP系统有助于深入分析大量的历史数据,而OLTP系统则可确保实时操作的快速和可靠。然而在实践中,企业通常会在其数据处理生态系统中同时部署OLAP和OLTP的组合。这种混合方法使他们能够高效地管理操作数据,同时从历史数据中获取有价值的见解。


















 565
565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











