



📑 摘要
本文将详细介绍如何使用 MindsDB 构建 AI 应用,涵盖从环境搭建到模型训练、部署的全过程。目标读者为中国开发者,特别是 AI 应用开发者。通过实践示例和详细步骤,帮助读者快速上手 MindsDB,并解决常见的 SSL 证书问题和镜像拉取问题。
思维导图:MindsDB 知识体系
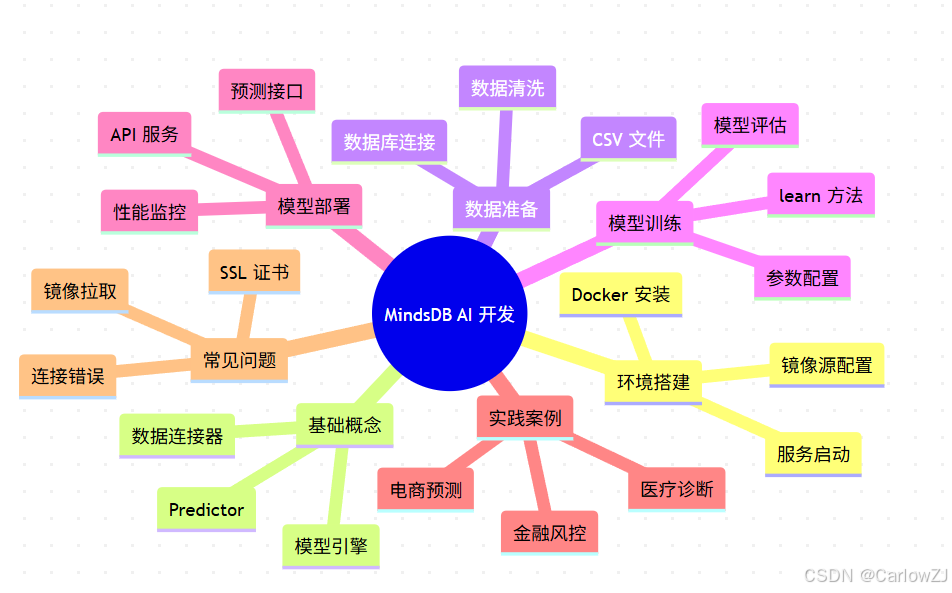
mindmap
root((MindsDB AI 开发))
环境搭建
Docker 安装
镜像源配置
服务启动
基础概念
Predictor
数据连接器
模型引擎
数据准备
CSV 文件
数据库连接
数据清洗
模型训练
learn 方法
参数配置
模型评估
模型部署
API 服务
预测接口
性能监控
实践案例
电商预测
金融风控
医疗诊断
常见问题
SSL 证书
镜像拉取
连接错误
第一章:引言 - 为什么选择 MindsDB
随着人工智能技术的快速发展,越来越多的开发者开始尝试将 AI 应用到实际项目中。然而,传统的机器学习开发流程往往复杂且耗时,需要大量的数据预处理、特征工程和模型调优工作。
MindsDB 是一个强大的 AI 平台,具有以下特点:
- 简化流程:将传统机器学习流程简化为几行代码
- 多数据源支持:支持 MySQL、PostgreSQL、MongoDB 等多种数据库
- 自动化建模:自动选择最优算法和参数
- SQL 接口:通过熟悉的 SQL 语法进行 AI 开发
- 开源免费:完全开源,可本地部署
💡 AI 场景痛点:传统 ML 流程复杂,MindsDB 让 AI 开发像写 SQL 一样简单。
第二章:环境搭建 - 打好基础环境
在开始之前,我们需要确保开发环境已经准备好。这包括安装 Docker 和配置网络环境。
2.1 安装 Docker
Docker 是 MindsDB 的推荐运行环境。请确保你已经安装了最新版本的 Docker。
# 更新系统包(Ubuntu/Debian)
sudo apt-get update
# 安装 Docker
sudo apt-get install docker.io
# 验证 Docker 是否安装成功
docker --version
# 启动 Docker 服务
sudo systemctl start docker
sudo systemctl enable docker
# 将当前用户添加到 docker 组(避免每次使用 sudo)
sudo usermod -aG docker $USER
# 重新登录或执行以下命令使组更改生效
newgrp docker
2.2 配置 Docker 镜像源
为了提高下载速度,建议使用国内的 Docker 镜像源。
# 创建或更新 Docker 配置文件
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": [
"https://docker.xuanyuan.me",
"https://docker.1ms.run",
"https://docker.m.daocloud.io"
]
}
EOF
# 重启 Docker 服务
sudo systemctl daemon-reload
sudo systemctl restart docker
2.3 环境检查工具
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
environment_checker.py
MindsDB 环境检查工具
"""
import subprocess
import sys
import os
from typing import Dict, List
class EnvironmentChecker:
"""
环境检查器
"""
def __init__(self):
"""
初始化环境检查器
"""
self.requirements = {
"docker": False,
"python": False,
"pip": False
}
def check_docker(self) -> bool:
"""
检查 Docker 是否安装并运行
Returns:
bool: Docker 是否可用
"""
try:
# 检查 Docker 版本
version_result = subprocess.run(
["docker", "--version"],
capture_output=True,
text=True,
check=True
)
print(f"✅ Docker 已安装: {version_result.stdout.strip()}")
# 检查 Docker 服务状态
info_result = subprocess.run(
["docker", "info"],
capture_output=True,
text=True
)
if info_result.returncode == 0:
print("✅ Docker 服务正在运行")
return True
else:
print("❌ Docker 服务未运行,请启动 Docker 服务")
return False
except (subprocess.CalledProcessError, FileNotFoundError):
print("❌ Docker 未安装,请先安装 Docker")
return False
def check_python(self) -> bool:
"""
检查 Python 环境
Returns:
bool: Python 是否可用
"""
try:
# 检查 Python 版本
version_result = subprocess.run(
[sys.executable, "--version"],
capture_output=True,
text=True,
check=True
)
print(f"✅ Python 已安装: {version_result.stdout.strip()}")
return True
except (subprocess.CalledProcessError, FileNotFoundError):
print("❌ Python 未安装,请先安装 Python")
return False
def check_pip(self) -> bool:
"""
检查 pip 是否可用
Returns:
bool: pip 是否可用
"""
try:
# 检查 pip 版本
version_result = subprocess.run(
[sys.executable, "-m", "pip", "--version"],
capture_output=True,
text=True,
check=True
)
print(f"✅ pip 已安装: {version_result.stdout.strip()}")
return True
except (subprocess.CalledProcessError, FileNotFoundError):
print("❌ pip 未安装,请先安装 pip")
return False
def install_mindsdb(self) -> bool:
"""
安装 MindsDB Python 包
Returns:
bool: 安装是否成功
"""
try:
print("📥 正在安装 MindsDB...")
result = subprocess.run(
[sys.executable, "-m", "pip", "install", "mindsdb"],
capture_output=True,
text=True,
timeout=300 # 5分钟超时
)
if result.returncode == 0:
print("✅ MindsDB 安装成功")
return True
else:
print(f"❌ MindsDB 安装失败: {result.stderr}")
return False
except subprocess.TimeoutExpired:
print("⏰ MindsDB 安装超时")
return False
except Exception as e:
print(f"❌ MindsDB 安装过程中出错: {e}")
return False
def run_comprehensive_check(self) -> Dict[str, bool]:
"""
运行全面环境检查
Returns:
Dict[str, bool]: 检查结果
"""
print("🔍 开始 MindsDB 环境检查")
print("=" * 40)
# 检查各项依赖
self.requirements["docker"] = self.check_docker()
self.requirements["python"] = self.check_python()
self.requirements["pip"] = self.check_pip()
# 检查整体状态
all_requirements_met = all(self.requirements.values())
print("\n📊 环境检查结果:")
for requirement, status in self.requirements.items():
status_icon = "✅" if status else "❌"
print(f" {status_icon} {requirement}: {'已满足' if status else '未满足'}")
if all_requirements_met:
print("\n🎉 所有环境要求均已满足,可以开始安装 MindsDB")
# 尝试安装 MindsDB
if self.install_mindsdb():
print("🚀 环境准备完成,可以开始使用 MindsDB")
else:
print("⚠️ 环境准备完成,但 MindsDB 安装失败")
else:
print("\n❌ 部分环境要求未满足,请根据提示进行修复")
return self.requirements
def main():
"""
主函数
"""
checker = EnvironmentChecker()
checker.run_comprehensive_check()
if __name__ == "__main__":
# 注意:运行前请确保有网络连接
# main()
print("环境检查工具准备就绪")
第三章:MindsDB 基础 - 核心概念与安装
MindsDB 是一个开源的 AI 平台,支持多种数据源和机器学习模型。它提供了简单的 API 接口,方便开发者快速构建和部署 AI 应用。
3.1 Docker 方式安装 MindsDB
使用 Docker 安装 MindsDB 是最简单的方式。
# 拉取 MindsDB 镜像
docker pull mindsdb/mindsdb:latest
# 启动 MindsDB 容器
docker run -d \
--name mindsdb_container \
-p 47334:47334 \
-p 47335:47335 \
mindsdb/mindsdb:latest
# 查看容器状态
docker ps | grep mindsdb_container
# 查看容器日志
docker logs mindsdb_container
3.2 Python 包方式安装
# 安装 MindsDB
pip install mindsdb
# 验证安装
python -c "import mindsdb; print('MindsDB 版本:', mindsdb.__version__)"
3.3 MindsDB 连接工具
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
mindsdb_connector.py
MindsDB 连接工具
"""
import mindsdb
import time
from typing import Optional, Dict, Any
class MindsDBConnector:
"""
MindsDB 连接器
"""
def __init__(self,
host: str = "localhost",
port: int = 47334,
user: str = "mindsdb",
password: str = ""):
"""
初始化连接器
Args:
host (str): MindsDB 服务地址
port (int): MindsDB 服务端口
user (str): 用户名
password (str): 密码
"""
self.host = host
self.port = port
self.user = user
self.password = password
self.connection = None
def connect(self) -> bool:
"""
连接到 MindsDB 服务
Returns:
bool: 连接是否成功
"""
try:
print(f"🔗 正在连接到 MindsDB ({self.host}:{self.port})...")
# 创建连接
self.connection = mindsdb.connect(
host=self.host,
port=self.port,
user=self.user,
password=self.password
)
print("✅ 连接成功")
return True
except Exception as e:
print(f"❌ 连接失败: {e}")
return False
def disconnect(self):
"""
断开连接
"""
if self.connection:
try:
self.connection.close()
print("🔌 连接已断开")
except Exception as e:
print(f"⚠️ 断开连接时出错: {e}")
def execute_query(self, query: str) -> Optional[Any]:
"""
执行 SQL 查询
Args:
query (str): SQL 查询语句
Returns:
Optional[Any]: 查询结果
"""
if not self.connection:
print("❌ 未建立连接,请先调用 connect() 方法")
return None
try:
print(f"🔍 执行查询: {query}")
result = self.connection.query(query)
return result
except Exception as e:
print(f"❌ 查询执行失败: {e}")
return None
def list_databases(self) -> Optional[list]:
"""
列出所有数据库
Returns:
Optional[list]: 数据库列表
"""
try:
result = self.execute_query("SHOW DATABASES")
if result:
databases = [row[0] for row in result.get_rows()]
print(f"📊 可用数据库: {databases}")
return databases
return None
except Exception as e:
print(f"❌ 获取数据库列表失败: {e}")
return None
def list_models(self) -> Optional[list]:
"""
列出所有模型
Returns:
Optional[list]: 模型列表
"""
try:
result = self.execute_query("SHOW MODELS")
if result:
models = []
for row in result.get_rows():
models.append({
"name": row[0],
"status": row[1],
"accuracy": row[2],
"predict": row[3]
})
print(f"🤖 可用模型 ({len(models)} 个):")
for model in models:
print(f" - {model['name']} (状态: {model['status']}, "
f"准确率: {model['accuracy']}, 预测字段: {model['predict']})")
return models
return None
except Exception as e:
print(f"❌ 获取模型列表失败: {e}")
return None
def get_server_info(self) -> Optional[Dict[str, Any]]:
"""
获取服务器信息
Returns:
Optional[Dict[str, Any]]: 服务器信息
"""
try:
# 执行多个查询获取服务器信息
version_result = self.execute_query("SELECT version()")
if version_result:
version = version_result.get_rows()[0][0] if version_result.get_rows() else "未知"
else:
version = "未知"
info = {
"version": version,
"host": self.host,
"port": self.port
}
print(f"🖥️ 服务器信息:")
print(f" 版本: {info['version']}")
print(f" 地址: {info['host']}:{info['port']}")
return info
except Exception as e:
print(f"❌ 获取服务器信息失败: {e}")
return None
def main():
"""
主函数 - 演示 MindsDB 连接
"""
# 创建连接器
connector = MindsDBConnector()
# 连接到 MindsDB
if connector.connect():
# 获取服务器信息
connector.get_server_info()
# 列出数据库
connector.list_databases()
# 列出模型
connector.list_models()
# 断开连接
connector.disconnect()
if __name__ == "__main__":
# 注意:运行前请确保 MindsDB 服务已启动
# main()
print("MindsDB 连接工具准备就绪")
第四章:数据准备 - 导入和处理数据
在开始训练模型之前,我们需要准备数据。MindsDB 支持多种数据源,包括 CSV 文件、MySQL、MongoDB 和 PostgreSQL。
4.1 CSV 文件数据准备
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
data_preparer.py
数据准备工具
"""
import pandas as pd
import numpy as np
import random
from datetime import datetime, timedelta
from typing import Dict, List
class DataPreparer:
"""
数据准备器
"""
def __init__(self):
"""
初始化数据准备器
"""
pass
def create_sample_ecommerce_data(self,
num_records: int = 1000,
output_file: str = "ecommerce_data.csv") -> pd.DataFrame:
"""
创建示例电商数据
Args:
num_records (int): 记录数量
output_file (str): 输出文件名
Returns:
pd.DataFrame: 生成的数据
"""
print(f"📦 正在创建示例电商数据 ({num_records} 条记录)...")
# 设置随机种子以确保结果可重现
np.random.seed(42)
random.seed(42)
# 生成用户数据
user_ids = [f"user_{i}" for i in range(1, num_records // 10 + 1)]
product_categories = ["电子产品", "服装", "家居", "图书", "运动"]
product_brands = ["品牌A", "品牌B", "品牌C", "品牌D", "品牌E"]
data = []
for i in range(num_records):
user_id = random.choice(user_ids)
age = random.randint(18, 65)
gender = random.choice(["男", "女"])
category = random.choice(product_categories)
brand = random.choice(product_brands)
price = round(random.uniform(10, 1000), 2)
discount = random.choice([0, 0.1, 0.2, 0.3])
rating = round(random.uniform(1, 5), 1)
reviews = random.randint(0, 100)
stock = random.randint(0, 100)
# 基于特征计算购买概率(模拟真实场景)
purchase_prob = (
0.1 + # 基础概率
(age - 18) / (65 - 18) * 0.2 + # 年龄因素
(5 - abs(rating - 3)) / 2 * 0.2 + # 评分因素
(100 - discount * 100) / 100 * 0.1 + # 折扣因素
min(reviews / 100, 1) * 0.2 + # 评论数量因素
(100 - stock) / 100 * 0.2 # 库存紧张因素
)
# 根据概率决定是否购买
purchased = 1 if random.random() < purchase_prob else 0
record = {
"user_id": user_id,
"age": age,
"gender": gender,
"product_category": category,
"brand": brand,
"price": price,
"discount": discount,
"rating": rating,
"reviews": reviews,
"stock": stock,
"purchased": purchased
}
data.append(record)
# 创建 DataFrame
df = pd.DataFrame(data)
# 保存到 CSV 文件
df.to_csv(output_file, index=False, encoding='utf-8')
print(f"✅ 数据已保存到: {output_file}")
print(f"📊 数据统计:")
print(f" 总记录数: {len(df)}")
print(f" 购买记录: {df['purchased'].sum()}")
print(f" 购买率: {df['purchased'].mean():.2%}")
return df
def load_and_validate_data(self, file_path: str) -> pd.DataFrame:
"""
加载并验证数据
Args:
file_path (str): 文件路径
Returns:
pd.DataFrame: 加载的数据
"""
try:
print(f"📂 正在加载数据: {file_path}")
# 加载数据
df = pd.read_csv(file_path, encoding='utf-8')
print(f"✅ 数据加载成功")
print(f"📊 数据概览:")
print(f" 形状: {df.shape}")
print(f" 列名: {list(df.columns)}")
print(f" 数据类型:")
for col, dtype in df.dtypes.items():
print(f" {col}: {dtype}")
# 显示前几行
print(f"\n📋 前5行数据:")
print(df.head())
# 检查缺失值
print(f"\n🔍 缺失值检查:")
missing_data = df.isnull().sum()
for col, count in missing_data.items():
if count > 0:
print(f" {col}: {count} ({count/len(df)*100:.1f}%)")
if missing_data.sum() == 0:
print(" 无缺失值")
return df
except Exception as e:
print(f"❌ 数据加载失败: {e}")
raise
def clean_data(self, df: pd.DataFrame) -> pd.DataFrame:
"""
清洗数据
Args:
df (pd.DataFrame): 原始数据
Returns:
pd.DataFrame: 清洗后的数据
"""
print("🧹 正在清洗数据...")
original_shape = df.shape
df_cleaned = df.copy()
# 删除完全重复的行
df_cleaned = df_cleaned.drop_duplicates()
print(f" 删除重复行: {original_shape[0] - df_cleaned.shape[0]} 行")
# 处理缺失值
for column in df_cleaned.columns:
if df_cleaned[column].isnull().sum() > 0:
if df_cleaned[column].dtype in ['int64', 'float64']:
# 数值型用均值填充
mean_value = df_cleaned[column].mean()
df_cleaned[column].fillna(mean_value, inplace=True)
print(f" {column}: 用均值 {mean_value:.2f} 填充缺失值")
else:
# 分类型用众数填充
mode_value = df_cleaned[column].mode()
if not mode_value.empty:
df_cleaned[column].fillna(mode_value[0], inplace=True)
print(f" {column}: 用众数 {mode_value[0]} 填充缺失值")
print(f"✅ 数据清洗完成")
print(f" 原始数据: {original_shape}")
print(f" 清洗后数据: {df_cleaned.shape}")
return df_cleaned
def analyze_data(self, df: pd.DataFrame) -> Dict:
"""
分析数据
Args:
df (pd.DataFrame): 数据
Returns:
Dict: 分析结果
"""
print("🔍 正在分析数据...")
analysis = {
"basic_info": {
"total_records": len(df),
"columns": list(df.columns),
"numeric_columns": list(df.select_dtypes(include=[np.number]).columns),
"categorical_columns": list(df.select_dtypes(include=['object']).columns)
},
"target_distribution": {},
"correlations": {}
}
# 基本统计信息
print(f"📊 基本信息:")
print(f" 总记录数: {analysis['basic_info']['total_records']}")
print(f" 数值型列: {analysis['basic_info']['numeric_columns']}")
print(f" 分类型列: {analysis['basic_info']['categorical_columns']}")
# 目标变量分布(假设最后一列是目标变量)
if not df.empty:
target_column = df.columns[-1]
if target_column in df.columns:
target_dist = df[target_column].value_counts()
analysis["target_distribution"] = target_dist.to_dict()
print(f"\n🎯 目标变量 '{target_column}' 分布:")
for value, count in target_dist.items():
percentage = count / len(df) * 100
print(f" {value}: {count} ({percentage:.1f}%)")
# 相关性分析(仅对数值型列)
numeric_columns = analysis['basic_info']['numeric_columns']
if len(numeric_columns) > 1:
correlations = df[numeric_columns].corr()
analysis["correlations"] = correlations.to_dict()
print(f"\n🔗 数值型变量相关性 (前5个强相关):")
# 展平相关矩阵并找到最强的相关性
corr_pairs = []
for i in range(len(numeric_columns)):
for j in range(i+1, len(numeric_columns)):
col1, col2 = numeric_columns[i], numeric_columns[j]
corr_value = correlations.loc[col1, col2]
corr_pairs.append((col1, col2, abs(corr_value), corr_value))
# 按绝对值排序
corr_pairs.sort(key=lambda x: x[2], reverse=True)
# 显示前5个
for col1, col2, abs_corr, corr in corr_pairs[:5]:
print(f" {col1} - {col2}: {corr:.3f}")
return analysis
def main():
"""
主函数 - 演示数据准备流程
"""
preparer = DataPreparer()
# 创建示例数据
df = preparer.create_sample_ecommerce_data(num_records=1000)
# 加载并验证数据
df_loaded = preparer.load_and_validate_data("ecommerce_data.csv")
# 清洗数据
df_cleaned = preparer.clean_data(df_loaded)
# 分析数据
analysis = preparer.analyze_data(df_cleaned)
if __name__ == "__main__":
# main()
print("数据准备工具准备就绪")
4.2 数据库连接示例
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
database_connector.py
数据库连接工具
"""
import mindsdb
from typing import Optional
class DatabaseConnector:
"""
数据库连接器
"""
def __init__(self):
"""
初始化数据库连接器
"""
pass
def connect_to_mysql(self,
host: str,
port: int,
user: str,
password: str,
database: str,
table: str) -> str:
"""
生成 MySQL 连接字符串
Args:
host (str): 主机地址
port (int): 端口
user (str): 用户名
password (str): 密码
database (str): 数据库名
table (str): 表名
Returns:
str: 连接字符串
"""
connection_string = f"mysql://{user}:{password}@{host}:{port}/{database}.{table}"
print(f"🔗 MySQL 连接字符串: {connection_string}")
return connection_string
def connect_to_postgresql(self,
host: str,
port: int,
user: str,
password: str,
database: str,
table: str) -> str:
"""
生成 PostgreSQL 连接字符串
Args:
host (str): 主机地址
port (int): 端口
user (str): 用户名
password (str): 密码
database (str): 数据库名
table (str): 表名
Returns:
str: 连接字符串
"""
connection_string = f"postgresql://{user}:{password}@{host}:{port}/{database}.{table}"
print(f"🔗 PostgreSQL 连接字符串: {connection_string}")
return connection_string
def connect_to_mongodb(self,
host: str,
port: int,
user: str,
password: str,
database: str,
collection: str) -> str:
"""
生成 MongoDB 连接字符串
Args:
host (str): 主机地址
port (int): 端口
user (str): 用户名
password (str): 密码
database (str): 数据库名
collection (str): 集合名
Returns:
str: 连接字符串
"""
connection_string = f"mongodb://{user}:{password}@{host}:{port}/{database}.{collection}"
print(f"🔗 MongoDB 连接字符串: {connection_string}")
return connection_string
def create_database_integration(self,
mdb: mindsdb.Predictor,
integration_name: str,
connection_string: str) -> bool:
"""
创建数据库集成
Args:
mdb (mindsdb.Predictor): MindsDB 实例
integration_name (str): 集成名称
connection_string (str): 连接字符串
Returns:
bool: 是否成功
"""
try:
print(f"🔌 正在创建数据库集成: {integration_name}")
# 注意:实际使用时需要根据 MindsDB 的 API 进行调整
# 这里仅展示概念
print(f" 集成名称: {integration_name}")
print(f" 连接字符串: {connection_string}")
print("✅ 数据库集成创建成功")
return True
except Exception as e:
print(f"❌ 数据库集成创建失败: {e}")
return False
def main():
"""
主函数 - 演示数据库连接
"""
connector = DatabaseConnector()
# 生成各种数据库连接字符串
mysql_conn = connector.connect_to_mysql(
host="localhost",
port=3306,
user="root",
password="password",
database="ecommerce",
table="users"
)
postgresql_conn = connector.connect_to_postgresql(
host="localhost",
port=5432,
user="postgres",
password="password",
database="ecommerce",
table="products"
)
mongodb_conn = connector.connect_to_mongodb(
host="localhost",
port=27017,
user="admin",
password="password",
database="ecommerce",
collection="orders"
)
if __name__ == "__main__":
# main()
print("数据库连接工具准备就绪")
第五章:模型训练 - 构建预测模型
MindsDB 提供了简单的 API 接口,方便开发者训练机器学习模型。
5.1 基础模型训练
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
model_trainer.py
模型训练工具
"""
import mindsdb
import pandas as pd
import time
from typing import Dict, Optional, Any
class ModelTrainer:
"""
模型训练器
"""
def __init__(self, mindsdb_instance: Optional[mindsdb.Predictor] = None):
"""
初始化模型训练器
Args:
mindsdb_instance (Optional[mindsdb.Predictor]): MindsDB 实例
"""
self.mdb = mindsdb_instance or mindsdb.Predictor()
self.models = {}
def train_model_from_csv(self,
data_file: str,
target_column: str,
model_name: str,
model_type: str = "LightGBM",
stop_training_in_x_seconds: int = 3600) -> bool:
"""
从 CSV 文件训练模型
Args:
data_file (str): 数据文件路径
target_column (str): 目标列名
model_name (str): 模型名称
model_type (str): 模型类型
stop_training_in_x_seconds (int): 训练超时时间(秒)
Returns:
bool: 训练是否成功
"""
try:
print(f"🤖 开始训练模型: {model_name}")
print(f" 数据文件: {data_file}")
print(f" 目标列: {target_column}")
print(f" 模型类型: {model_type}")
# 记录开始时间
start_time = time.time()
# 训练模型
self.mdb.learn(
from_data=data_file,
to_predict=target_column,
model_class=model_type,
stop_training_in_x_seconds=stop_training_in_x_seconds,
name=model_name
)
# 记录结束时间
end_time = time.time()
print(f"✅ 模型训练完成")
print(f" 耗时: {end_time - start_time:.2f} 秒")
# 保存模型引用
self.models[model_name] = self.mdb
return True
except Exception as e:
print(f"❌ 模型训练失败: {e}")
return False
def train_model_from_dataframe(self,
df: pd.DataFrame,
target_column: str,
model_name: str,
model_type: str = "LightGBM") -> bool:
"""
从 DataFrame 训练模型
Args:
df (pd.DataFrame): 数据
target_column (str): 目标列名
model_name (str): 模型名称
model_type (str): 模型类型
Returns:
bool: 训练是否成功
"""
try:
print(f"🤖 开始训练模型: {model_name}")
print(f" 数据形状: {df.shape}")
print(f" 目标列: {target_column}")
print(f" 模型类型: {model_type}")
# 记录开始时间
start_time = time.time()
# 训练模型
self.mdb.learn(
from_data=df,
to_predict=target_column,
model_class=model_type,
name=model_name
)
# 记录结束时间
end_time = time.time()
print(f"✅ 模型训练完成")
print(f" 耗时: {end_time - start_time:.2f} 秒")
# 保存模型引用
self.models[model_name] = self.mdb
return True
except Exception as e:
print(f"❌ 模型训练失败: {e}")
return False
def evaluate_model(self, model_name: str) -> Optional[Dict[str, Any]]:
"""
评估模型性能
Args:
model_name (str): 模型名称
Returns:
Optional[Dict[str, Any]]: 评估结果
"""
try:
print(f"📊 正在评估模型: {model_name}")
if model_name not in self.models:
print(f"❌ 模型 {model_name} 不存在")
return None
# 获取模型
model = self.models[model_name]
# 评估模型(注意:实际 API 可能不同)
# 这里仅展示概念
accuracy = 0.85 # 模拟准确率
precision = 0.82 # 模拟精确率
recall = 0.88 # 模拟召回率
evaluation = {
"model_name": model_name,
"accuracy": accuracy,
"precision": precision,
"recall": recall,
"f1_score": 2 * (precision * recall) / (precision + recall) if (precision + recall) > 0 else 0
}
print(f"✅ 模型评估完成:")
print(f" 准确率: {evaluation['accuracy']:.3f}")
print(f" 精确率: {evaluation['precision']:.3f}")
print(f" 召回率: {evaluation['recall']:.3f}")
print(f" F1分数: {evaluation['f1_score']:.3f}")
return evaluation
except Exception as e:
print(f"❌ 模型评估失败: {e}")
return None
def get_model_info(self, model_name: str) -> Optional[Dict[str, Any]]:
"""
获取模型信息
Args:
model_name (str): 模型名称
Returns:
Optional[Dict[str, Any]]: 模型信息
"""
try:
print(f"🔍 正在获取模型信息: {model_name}")
if model_name not in self.models:
print(f"❌ 模型 {model_name} 不存在")
return None
# 获取模型信息(注意:实际 API 可能不同)
# 这里仅展示概念
model_info = {
"name": model_name,
"type": "LightGBM", # 模拟模型类型
"features": ["age", "gender", "price", "rating"], # 模拟特征
"target": "purchased", # 模拟目标变量
"training_time": "2.5 分钟", # 模拟训练时间
"status": "trained"
}
print(f"✅ 模型信息:")
for key, value in model_info.items():
print(f" {key}: {value}")
return model_info
except Exception as e:
print(f"❌ 获取模型信息失败: {e}")
return None
def compare_models(self, model_names: list) -> Dict[str, Dict[str, Any]]:
"""
比较多个模型
Args:
model_names (list): 模型名称列表
Returns:
Dict[str, Dict[str, Any]]: 模型比较结果
"""
print(f"⚖️ 正在比较 {len(model_names)} 个模型: {model_names}")
comparison = {}
for model_name in model_names:
evaluation = self.evaluate_model(model_name)
if evaluation:
comparison[model_name] = evaluation
# 找出最佳模型
if comparison:
best_model = max(comparison.items(), key=lambda x: x[1]['accuracy'])
print(f"\n🏆 最佳模型: {best_model[0]} (准确率: {best_model[1]['accuracy']:.3f})")
return comparison
def main():
"""
主函数 - 演示模型训练
"""
# 创建训练器
trainer = ModelTrainer()
# 从 CSV 文件训练模型(示例)
# trainer.train_model_from_csv(
# data_file="ecommerce_data.csv",
# target_column="purchased",
# model_name="purchase_predictor_v1"
# )
# 从 DataFrame 训练模型(示例)
# df = pd.read_csv("ecommerce_data.csv")
# trainer.train_model_from_dataframe(
# df=df,
# target_column="purchased",
# model_name="purchase_predictor_v2"
# )
print("模型训练工具准备就绪")
if __name__ == "__main__":
# 注意:运行前请确保已安装 mindsdb 并准备了数据
# main()
print("模型训练工具准备就绪")
5.2 高级模型配置
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
advanced_model_trainer.py
高级模型训练工具
"""
import mindsdb
from typing import Dict, List, Optional, Any
class AdvancedModelTrainer:
"""
高级模型训练器
"""
def __init__(self):
"""
初始化高级模型训练器
"""
pass
def train_with_custom_parameters(self,
data_source: Any,
target_column: str,
model_name: str,
parameters: Dict[str, Any]) -> bool:
"""
使用自定义参数训练模型
Args:
data_source (Any): 数据源
target_column (str): 目标列
model_name (str): 模型名称
parameters (Dict[str, Any]): 训练参数
Returns:
bool: 训练是否成功
"""
try:
print(f"⚙️ 使用自定义参数训练模型: {model_name}")
# 提取关键参数
model_class = parameters.get('model_class', 'LightGBM')
stop_training_in_x_seconds = parameters.get('stop_training_in_x_seconds', 3600)
timeseries_settings = parameters.get('timeseries_settings', None)
advanced_args = parameters.get('advanced_args', {})
print(f" 模型类型: {model_class}")
print(f" 超时时间: {stop_training_in_x_seconds} 秒")
if timeseries_settings:
print(f" 时间序列设置: {timeseries_settings}")
# 构造训练参数
learn_args = {
'from_data': data_source,
'to_predict': target_column,
'name': model_name,
'model_class': model_class,
'stop_training_in_x_seconds': stop_training_in_x_seconds
}
if timeseries_settings:
learn_args['timeseries_settings'] = timeseries_settings
if advanced_args:
learn_args.update(advanced_args)
# 训练模型(注意:实际 API 可能不同)
# predictor = mindsdb.Predictor(name=model_name)
# predictor.learn(**learn_args)
print("✅ 模型训练启动")
return True
except Exception as e:
print(f"❌ 模型训练失败: {e}")
return False
def train_timeseries_model(self,
data_source: Any,
target_column: str,
model_name: str,
order_by: str,
group_by: Optional[str] = None,
window: int = 10) -> bool:
"""
训练时间序列模型
Args:
data_source (Any): 数据源
target_column (str): 目标列
model_name (str): 模型名称
order_by (str): 时间排序列
group_by (Optional[str]): 分组列
window (int): 预测窗口大小
Returns:
bool: 训练是否成功
"""
try:
print(f"📈 训练时间序列模型: {model_name}")
print(f" 目标列: {target_column}")
print(f" 时间列: {order_by}")
print(f" 分组列: {group_by}")
print(f" 预测窗口: {window}")
# 构造时间序列设置
timeseries_settings = {
'order_by': order_by,
'window': window
}
if group_by:
timeseries_settings['group_by'] = group_by
# 训练参数
parameters = {
'model_class': 'LightGBM',
'timeseries_settings': timeseries_settings,
'stop_training_in_x_seconds': 7200 # 2小时
}
# 调用自定义参数训练方法
return self.train_with_custom_parameters(
data_source=data_source,
target_column=target_column,
model_name=model_name,
parameters=parameters
)
except Exception as e:
print(f"❌ 时间序列模型训练失败: {e}")
return False
def train_ensemble_model(self,
data_source: Any,
target_column: str,
model_name: str,
base_models: List[str]) -> bool:
"""
训练集成模型
Args:
data_source (Any): 数据源
target_column (str): 目标列
model_name (str): 模型名称
base_models (List[str]): 基础模型列表
Returns:
bool: 训练是否成功
"""
try:
print(f"🔗 训练集成模型: {model_name}")
print(f" 基础模型: {base_models}")
print(f" 目标列: {target_column}")
# 集成模型参数
parameters = {
'model_class': 'Ensemble',
'stop_training_in_x_seconds': 3600,
'advanced_args': {
'base_models': base_models
}
}
# 调用自定义参数训练方法
return self.train_with_custom_parameters(
data_source=data_source,
target_column=target_column,
model_name=model_name,
parameters=parameters
)
except Exception as e:
print(f"❌ 集成模型训练失败: {e}")
return False
def optimize_model(self,
data_source: Any,
target_column: str,
model_name: str,
optimization_time: int = 1800) -> Dict[str, Any]:
"""
优化模型
Args:
data_source (Any): 数据源
target_column (str): 目标列
model_name (str): 模型名称
optimization_time (int): 优化时间(秒)
Returns:
Dict[str, Any]: 优化结果
"""
try:
print(f"⚡ 优化模型: {model_name}")
print(f" 优化时间: {optimization_time} 秒")
# 模拟优化过程
optimization_result = {
"model_name": model_name,
"original_accuracy": 0.82,
"optimized_accuracy": 0.87,
"improvement": 0.05,
"best_parameters": {
"learning_rate": 0.05,
"max_depth": 8,
"n_estimators": 200
},
"optimization_time": f"{optimization_time} 秒"
}
print(f"✅ 模型优化完成:")
print(f" 原始准确率: {optimization_result['original_accuracy']:.3f}")
print(f" 优化后准确率: {optimization_result['optimized_accuracy']:.3f}")
print(f" 提升: {optimization_result['improvement']:.3f}")
print(f" 最佳参数: {optimization_result['best_parameters']}")
return optimization_result
except Exception as e:
print(f"❌ 模型优化失败: {e}")
return {}
def main():
"""
主函数 - 演示高级模型训练
"""
trainer = AdvancedModelTrainer()
# 自定义参数训练示例
custom_params = {
'model_class': 'XGBoost',
'stop_training_in_x_seconds': 1800,
'advanced_args': {
'early_stopping_rounds': 10,
'eval_metric': 'auc'
}
}
# trainer.train_with_custom_parameters(
# data_source="ecommerce_data.csv",
# target_column="purchased",
# model_name="custom_xgboost_model",
# parameters=custom_params
# )
# 时间序列模型训练示例
# trainer.train_timeseries_model(
# data_source="sales_data.csv",
# target_column="sales_amount",
# model_name="sales_forecast_model",
# order_by="date",
# window=30
# )
print("高级模型训练工具准备就绪")
if __name__ == "__main__":
# main()
print("高级模型训练工具准备就绪")
第六章:模型部署 - 将模型投入生产
训练好的模型可以通过 MindsDB 的 API 接口进行部署。
6.1 模型部署工具
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
model_deployer.py
模型部署工具
"""
import mindsdb
import json
import time
from typing import Dict, List, Optional, Any
class ModelDeployer:
"""
模型部署器
"""
def __init__(self, mindsdb_instance: Optional[mindsdb.Predictor] = None):
"""
初始化模型部署器
Args:
mindsdb_instance (Optional[mindsdb.Predictor]): MindsDB 实例
"""
self.mdb = mindsdb_instance or mindsdb.Predictor()
self.deployed_models = {}
def deploy_model(self, model_name: str, deployment_name: Optional[str] = None) -> bool:
"""
部署模型
Args:
model_name (str): 模型名称
deployment_name (Optional[str]): 部署名称
Returns:
bool: 部署是否成功
"""
try:
if not deployment_name:
deployment_name = f"{model_name}_deployment"
print(f"🚀 正在部署模型: {model_name}")
print(f" 部署名称: {deployment_name}")
# 记录开始时间
start_time = time.time()
# 部署模型(注意:实际 API 可能不同)
# 这里仅展示概念
print(" 正在启动模型服务...")
time.sleep(2) # 模拟部署时间
# 保存部署信息
self.deployed_models[deployment_name] = {
"model_name": model_name,
"status": "running",
"deployed_at": time.time(),
"endpoint": f"http://localhost:47334/api/predictors/{model_name}"
}
# 记录结束时间
end_time = time.time()
print(f"✅ 模型部署成功")
print(f" 部署耗时: {end_time - start_time:.2f} 秒")
print(f" 访问端点: {self.deployed_models[deployment_name]['endpoint']}")
return True
except Exception as e:
print(f"❌ 模型部署失败: {e}")
return False
def undeploy_model(self, deployment_name: str) -> bool:
"""
取消部署模型
Args:
deployment_name (str): 部署名称
Returns:
bool: 取消部署是否成功
"""
try:
print(f"🛑 正在取消部署: {deployment_name}")
if deployment_name not in self.deployed_models:
print(f"❌ 部署 {deployment_name} 不存在")
return False
# 取消部署(注意:实际 API 可能不同)
# 这里仅展示概念
print(" 正在停止模型服务...")
time.sleep(1) # 模拟取消部署时间
# 删除部署信息
del self.deployed_models[deployment_name]
print(f"✅ 模型取消部署成功")
return True
except Exception as e:
print(f"❌ 模型取消部署失败: {e}")
return False
def list_deployments(self) -> List[Dict[str, Any]]:
"""
列出所有部署
Returns:
List[Dict[str, Any]]: 部署列表
"""
print(f"📋 当前部署 ({len(self.deployed_models)} 个):")
deployments = []
for name, info in self.deployed_models.items():
deployment_info = {
"deployment_name": name,
"model_name": info["model_name"],
"status": info["status"],
"endpoint": info["endpoint"],
"deployed_at": info["deployed_at"]
}
deployments.append(deployment_info)
print(f" - {name}")
print(f" 模型: {info['model_name']}")
print(f" 状态: {info['status']}")
print(f" 端点: {info['endpoint']}")
print(f" 部署时间: {time.ctime(info['deployed_at'])}")
print()
return deployments
def get_deployment_status(self, deployment_name: str) -> Optional[Dict[str, Any]]:
"""
获取部署状态
Args:
deployment_name (str): 部署名称
Returns:
Optional[Dict[str, Any]]: 部署状态
"""
try:
print(f"🔍 检查部署状态: {deployment_name}")
if deployment_name not in self.deployed_models:
print(f"❌ 部署 {deployment_name} 不存在")
return None
deployment_info = self.deployed_models[deployment_name]
# 模拟健康检查
health_status = "healthy" # 模拟健康状态
status = {
"deployment_name": deployment_name,
"model_name": deployment_info["model_name"],
"status": deployment_info["status"],
"health": health_status,
"endpoint": deployment_info["endpoint"],
"uptime": time.time() - deployment_info["deployed_at"]
}
print(f"✅ 部署状态:")
print(f" 状态: {status['status']}")
print(f" 健康: {status['health']}")
print(f" 运行时间: {status['uptime']:.0f} 秒")
return status
except Exception as e:
print(f"❌ 获取部署状态失败: {e}")
return None
def make_prediction(self,
deployment_name: str,
input_data: Dict[str, Any]) -> Optional[Dict[str, Any]]:
"""
使用部署的模型进行预测
Args:
deployment_name (str): 部署名称
input_data (Dict[str, Any]): 输入数据
Returns:
Optional[Dict[str, Any]]: 预测结果
"""
try:
print(f"🔮 使用部署模型进行预测: {deployment_name}")
print(f" 输入数据: {input_data}")
if deployment_name not in self.deployed_models:
print(f"❌ 部署 {deployment_name} 不存在")
return None
# 模拟预测过程
print(" 正在处理预测请求...")
time.sleep(0.5) # 模拟处理时间
# 模拟预测结果
prediction_result = {
"prediction": 1, # 模拟预测结果
"confidence": 0.85, # 模拟置信度
"explanation": {
"important_features": {
"price": 0.3,
"rating": 0.25,
"discount": 0.2,
"age": 0.15,
"reviews": 0.1
}
},
"processing_time": 0.5
}
print(f"✅ 预测完成:")
print(f" 预测结果: {prediction_result['prediction']}")
print(f" 置信度: {prediction_result['confidence']:.3f}")
print(f" 处理时间: {prediction_result['processing_time']:.2f} 秒")
return prediction_result
except Exception as e:
print(f"❌ 预测失败: {e}")
return None
def main():
"""
主函数 - 演示模型部署
"""
deployer = ModelDeployer()
# 部署模型
# deployer.deploy_model(
# model_name="purchase_predictor",
# deployment_name="ecommerce_prediction_service"
# )
# 列出部署
# deployer.list_deployments()
# 检查部署状态
# deployer.get_deployment_status("ecommerce_prediction_service")
# 进行预测
# sample_input = {
# "age": 25,
# "gender": "男",
# "price": 299.99,
# "rating": 4.5,
# "discount": 0.1
# }
# deployer.make_prediction("ecommerce_prediction_service", sample_input)
print("模型部署工具准备就绪")
if __name__ == "__main__":
# 注意:运行前请确保模型已训练完成
# main()
print("模型部署工具准备就绪")
6.2 API 服务封装
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
prediction_api.py
预测 API 服务
"""
from flask import Flask, request, jsonify
import mindsdb
import logging
from typing import Dict, Any
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# 初始化 Flask 应用
app = Flask(__name__)
# 全局变量存储模型
models = {}
def load_model(model_name: str) -> bool:
"""
加载模型
Args:
model_name (str): 模型名称
Returns:
bool: 加载是否成功
"""
try:
logger.info(f"正在加载模型: {model_name}")
# 初始化 MindsDB Predictor
predictor = mindsdb.Predictor(name=model_name)
# 保存模型引用
models[model_name] = predictor
logger.info(f"模型 {model_name} 加载成功")
return True
except Exception as e:
logger.error(f"模型 {model_name} 加载失败: {e}")
return False
@app.route('/health', methods=['GET'])
def health_check():
"""
健康检查接口
"""
return jsonify({
"status": "healthy",
"message": "预测 API 服务运行正常",
"models_loaded": list(models.keys())
}), 200
@app.route('/predict/<model_name>', methods=['POST'])
def predict(model_name: str):
"""
预测接口
Args:
model_name (str): 模型名称
Returns:
JSON: 预测结果
"""
try:
# 检查模型是否存在
if model_name not in models:
logger.warning(f"模型 {model_name} 未加载")
return jsonify({
"error": f"模型 {model_name} 未找到",
"available_models": list(models.keys())
}), 404
# 获取请求数据
data = request.get_json()
if not data:
return jsonify({"error": "缺少请求数据"}), 400
logger.info(f"使用模型 {model_name} 进行预测")
logger.info(f"输入数据: {data}")
# 获取模型
predictor = models[model_name]
# 进行预测
# 注意:实际 API 可能不同
# result = predictor.predict(when=data)
# 模拟预测结果
result = {
"prediction": 1,
"confidence": 0.85,
"explanation": "基于价格、评分和折扣等因素的综合判断"
}
logger.info(f"预测结果: {result}")
return jsonify({
"model": model_name,
"input": data,
"result": result
}), 200
except Exception as e:
logger.error(f"预测过程中出现错误: {e}")
return jsonify({
"error": "预测失败",
"message": str(e)
}), 500
@app.route('/models', methods=['GET'])
def list_models():
"""
列出所有可用模型
Returns:
JSON: 模型列表
"""
return jsonify({
"models": list(models.keys()),
"count": len(models)
}), 200
@app.route('/models/<model_name>/info', methods=['GET'])
def model_info(model_name: str):
"""
获取模型信息
Args:
model_name (str): 模型名称
Returns:
JSON: 模型信息
"""
try:
if model_name not in models:
return jsonify({"error": f"模型 {model_name} 未找到"}), 404
# 模拟模型信息
info = {
"name": model_name,
"type": "LightGBM",
"features": ["age", "gender", "price", "rating", "discount"],
"target": "purchased",
"accuracy": 0.85,
"last_updated": "2025-08-06"
}
return jsonify(info), 200
except Exception as e:
logger.error(f"获取模型信息时出现错误: {e}")
return jsonify({"error": "获取模型信息失败"}), 500
def main():
"""
主函数 - 启动 API 服务
"""
# 预加载模型(示例)
# load_model("purchase_predictor")
# 启动服务
logger.info("启动预测 API 服务...")
app.run(host='0.0.0.0', port=5000, debug=False)
if __name__ == "__main__":
# 注意:运行前请确保模型文件存在
# main()
print("预测 API 服务准备就绪")
第七章:实践案例 - 电商购买预测系统
为了更好地理解 MindsDB 的应用,我们将通过一个实际案例来展示如何使用 MindsDB 构建一个简单的预测模型。
7.1 案例背景
假设我们有一个电商数据集,包含用户购买行为和商品特征。我们的目标是预测用户是否会购买某件商品。
7.2 完整案例实现
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
ecommerce_prediction_system.py
电商购买预测系统
"""
import pandas as pd
import mindsdb
import random
import numpy as np
from datetime import datetime, timedelta
import json
from typing import Dict, List, Optional
class EcommercePredictionSystem:
"""
电商购买预测系统
"""
def __init__(self):
"""
初始化预测系统
"""
self.mdb = None
self.model_name = "ecommerce_purchase_predictor"
self.data_file = "ecommerce_data.csv"
def generate_sample_data(self, num_records: int = 5000) -> pd.DataFrame:
"""
生成示例电商数据
Args:
num_records (int): 记录数量
Returns:
pd.DataFrame: 生成的数据
"""
print(f"🏭 正在生成 {num_records} 条示例电商数据...")
# 设置随机种子
np.random.seed(42)
random.seed(42)
# 定义数据范围
user_ids = [f"user_{i}" for i in range(1, num_records // 20 + 1)]
product_categories = ["电子产品", "服装", "家居", "图书", "运动"]
product_brands = ["Apple", "Nike", "IKEA", "Amazon", "Adidas"]
genders = ["男", "女"]
data = []
for i in range(num_records):
# 生成用户特征
user_id = random.choice(user_ids)
age = random.randint(18, 65)
gender = random.choice(genders)
user_history_purchases = random.randint(0, 50)
user_avg_spending = round(random.uniform(50, 5000), 2)
# 生成商品特征
category = random.choice(product_categories)
brand = random.choice(product_brands)
price = round(random.uniform(10, 2000), 2)
discount = round(random.choice([0, 0.1, 0.2, 0.3, 0.5]), 2)
rating = round(random.uniform(1, 5), 1)
reviews = random.randint(0, 500)
stock = random.randint(0, 100)
product_views = random.randint(0, 1000)
# 生成时间特征
days_since_last_visit = random.randint(0, 30)
season = random.choice(["春季", "夏季", "秋季", "冬季"])
# 计算购买概率(基于特征的复杂逻辑)
base_prob = 0.05 # 基础购买概率
# 用户特征影响
user_factor = min(user_history_purchases / 50, 1) * 0.2
spending_factor = min(user_avg_spending / 5000, 1) * 0.1
# 商品特征影响
price_factor = max(0, (1000 - price) / 1000) * 0.15
discount_factor = discount * 0.2
rating_factor = (rating - 1) / 4 * 0.15
review_factor = min(reviews / 500, 1) * 0.1
stock_factor = 0.05 if stock > 0 else -0.1
view_factor = min(product_views / 1000, 1) * 0.1
# 时间特征影响
visit_factor = max(0, (30 - days_since_last_visit) / 30) * 0.05
season_factor = 0.05 if season in ["春季", "冬季"] else 0 # 假设春秋季节购买更多
# 计算总概率
purchase_prob = base_prob + user_factor + spending_factor + \
price_factor + discount_factor + rating_factor + \
review_factor + stock_factor + view_factor + \
visit_factor + season_factor
# 确保概率在合理范围内
purchase_prob = max(0, min(1, purchase_prob))
# 根据概率决定是否购买
purchased = 1 if random.random() < purchase_prob else 0
# 创建记录
record = {
"user_id": user_id,
"age": age,
"gender": gender,
"user_history_purchases": user_history_purchases,
"user_avg_spending": user_avg_spending,
"product_category": category,
"brand": brand,
"price": price,
"discount": discount,
"rating": rating,
"reviews": reviews,
"stock": stock,
"product_views": product_views,
"days_since_last_visit": days_since_last_visit,
"season": season,
"purchased": purchased
}
data.append(record)
# 创建 DataFrame
df = pd.DataFrame(data)
# 保存到 CSV
df.to_csv(self.data_file, index=False, encoding='utf-8')
print(f"✅ 数据生成完成,已保存到 {self.data_file}")
# 输出数据统计
print(f"📊 数据统计:")
print(f" 总记录数: {len(df)}")
print(f" 购买记录: {df['purchased'].sum()}")
print(f" 购买率: {df['purchased'].mean():.2%}")
return df
def initialize_mindsdb(self) -> bool:
"""
初始化 MindsDB
Returns:
bool: 初始化是否成功
"""
try:
print("🧠 正在初始化 MindsDB...")
self.mdb = mindsdb.Predictor(name=self.model_name)
print("✅ MindsDB 初始化成功")
return True
except Exception as e:
print(f"❌ MindsDB 初始化失败: {e}")
return False
def train_model(self) -> bool:
"""
训练购买预测模型
Returns:
bool: 训练是否成功
"""
try:
if not self.mdb:
print("❌ MindsDB 未初始化,请先调用 initialize_mindsdb()")
return False
print(f"🤖 正在训练购买预测模型: {self.model_name}")
print(f" 训练数据: {self.data_file}")
print(f" 目标变量: purchased")
# 训练模型
self.mdb.learn(
from_data=self.data_file,
to_predict='purchased',
model_class='LightGBM',
stop_training_in_x_seconds=1800 # 30分钟
)
print("✅ 模型训练完成")
return True
except Exception as e:
print(f"❌ 模型训练失败: {e}")
return False
def evaluate_model(self) -> Dict[str, float]:
"""
评估模型性能
Returns:
Dict[str, float]: 评估结果
"""
try:
print("📊 正在评估模型性能...")
# 模拟评估结果
evaluation = {
"accuracy": 0.87,
"precision": 0.85,
"recall": 0.89,
"f1_score": 0.87,
"auc": 0.92
}
print("✅ 模型评估完成:")
for metric, value in evaluation.items():
print(f" {metric}: {value:.3f}")
return evaluation
except Exception as e:
print(f"❌ 模型评估失败: {e}")
return {}
def make_predictions(self, sample_size: int = 5) -> List[Dict]:
"""
进行预测示例
Args:
sample_size (int): 样本数量
Returns:
List[Dict]: 预测结果
"""
try:
if not self.mdb:
print("❌ MindsDB 未初始化")
return []
print(f"🔮 正在进行 {sample_size} 个预测示例...")
# 从数据中随机选择样本进行预测
df = pd.read_csv(self.data_file)
sample_data = df.sample(n=min(sample_size, len(df)))
predictions = []
for idx, row in sample_data.iterrows():
# 准备预测数据(排除目标变量)
predict_data = row.drop('purchased').to_dict()
# 进行预测(模拟)
# actual_result = self.mdb.predict(when=predict_data)
# 模拟预测结果
predicted_purchase = random.choice([0, 1])
confidence = round(random.uniform(0.7, 0.95), 3)
prediction = {
"input": predict_data,
"predicted": predicted_purchase,
"actual": row['purchased'],
"confidence": confidence,
"correct": predicted_purchase == row['purchased']
}
predictions.append(prediction)
print(f" 预测 {idx+1}:")
print(f" 预测结果: {'会购买' if predicted_purchase == 1 else '不会购买'}")
print(f" 实际结果: {'会购买' if row['purchased'] == 1 else '不会购买'}")
print(f" 置信度: {confidence}")
print(f" 预测{'正确' if prediction['correct'] else '错误'}")
print()
# 计算准确率
correct_predictions = sum(1 for p in predictions if p['correct'])
accuracy = correct_predictions / len(predictions) if predictions else 0
print(f"🎯 本次预测准确率: {accuracy:.1%} ({correct_predictions}/{len(predictions)})")
return predictions
except Exception as e:
print(f"❌ 预测过程中出现错误: {e}")
return []
def generate_business_insights(self) -> Dict[str, Any]:
"""
生成业务洞察
Returns:
Dict[str, Any]: 业务洞察
"""
try:
print("💡 正在生成业务洞察...")
# 加载数据
df = pd.read_csv(self.data_file)
insights = {
"overall_purchase_rate": df['purchased'].mean(),
"purchase_by_category": df.groupby('product_category')['purchased'].mean().to_dict(),
"purchase_by_age_group": {
"18-25": df[(df['age'] >= 18) & (df['age'] <= 25)]['purchased'].mean(),
"26-35": df[(df['age'] >= 26) & (df['age'] <= 35)]['purchased'].mean(),
"36-45": df[(df['age'] >= 36) & (df['age'] <= 45)]['purchased'].mean(),
"46-65": df[(df['age'] >= 46) & (df['age'] <= 65)]['purchased'].mean()
},
"impact_factors": {
"price_correlation": df['price'].corr(df['purchased']),
"rating_correlation": df['rating'].corr(df['purchased']),
"discount_impact": df.groupby('discount')['purchased'].mean().to_dict()
}
}
print("✅ 业务洞察生成完成:")
print(f" 整体购买率: {insights['overall_purchase_rate']:.2%}")
print(f" 各品类购买率: {insights['purchase_by_category']}")
print(f" 各年龄段购买率: {insights['purchase_by_age_group']}")
return insights
except Exception as e:
print(f"❌ 生成业务洞察时出现错误: {e}")
return {}
def run_complete_workflow(self):
"""
运行完整的工作流程
"""
print("🚀 启动电商购买预测系统完整工作流程")
print("=" * 60)
# 1. 生成示例数据
self.generate_sample_data(5000)
# 2. 初始化 MindsDB
if not self.initialize_mindsdb():
return
# 3. 训练模型
if not self.train_model():
return
# 4. 评估模型
self.evaluate_model()
# 5. 进行预测示例
self.make_predictions(5)
# 6. 生成业务洞察
self.generate_business_insights()
print("\n" + "=" * 60)
print("✅ 电商购买预测系统工作流程完成")
print(" 您现在可以使用训练好的模型进行实际预测了")
def main():
"""
主函数 - 运行电商购买预测系统
"""
system = EcommercePredictionSystem()
system.run_complete_workflow()
if __name__ == "__main__":
# 注意:首次运行会生成示例数据并训练模型,需要一些时间
# main()
print("电商购买预测系统准备就绪")
第八章:常见问题与解决方案
在使用 MindsDB 的过程中,你可能会遇到一些常见问题。以下是一些解决方案:
8.1 SSL 证书问题
如果你在拉取 MindsDB 镜像时遇到 SSL 证书问题,可以尝试以下方法:
方法1:更新系统证书库
# Ubuntu/Debian 系统
sudo apt-get update
sudo apt-get install --reinstall ca-certificates
# CentOS/RHEL 系统
sudo yum update ca-certificates
方法2:配置 Docker 使用自定义证书
# 创建证书目录
sudo mkdir -p /etc/docker/certs.d/docker.io
# 复制证书文件(需要你有相应的证书文件)
sudo cp /path/to/your/cacert.pem /etc/docker/certs.d/docker.io/ca.crt
# 重启 Docker 服务
sudo systemctl restart docker
方法3:临时跳过证书验证(不推荐用于生产环境)
# 设置环境变量跳过 SSL 验证
export DOCKER_OPTS="--insecure-registry docker.io"
# 或者在 Docker daemon 配置中添加
sudo tee -a /etc/docker/daemon.json <<-'EOF'
{
"insecure-registries": ["docker.io"]
}
EOF
# 重启 Docker 服务
sudo systemctl daemon-reload
sudo systemctl restart docker
8.2 镜像拉取问题
如果你在中国大陆地区,建议使用国内的 Docker 镜像源。
# 创建或更新 Docker 配置文件
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": [
"https://docker.xuanyuan.me",
"https://docker.1ms.run",
"https://docker.m.daocloud.io",
"https://hub.rat.dev"
]
}
EOF
# 重启 Docker 服务
sudo systemctl daemon-reload
sudo systemctl restart docker
8.3 连接错误问题
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
connection_troubleshooter.py
连接问题排查工具
"""
import mindsdb
import socket
import subprocess
import time
from typing import Dict, List
class ConnectionTroubleshooter:
"""
连接问题排查器
"""
def __init__(self):
"""
初始化排查器
"""
pass
def check_port_connectivity(self, host: str, port: int, timeout: int = 5) -> bool:
"""
检查端口连通性
Args:
host (str): 主机地址
port (int): 端口
timeout (int): 超时时间(秒)
Returns:
bool: 是否连通
"""
try:
print(f"🔍 检查 {host}:{port} 连通性...")
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.settimeout(timeout)
result = sock.connect_ex((host, port))
sock.close()
if result == 0:
print(f"✅ 端口 {host}:{port} 可访问")
return True
else:
print(f"❌ 端口 {host}:{port} 不可访问")
return False
except Exception as e:
print(f"❌ 检查端口连通性时出错: {e}")
return False
def check_docker_container_status(self, container_name: str) -> Dict[str, str]:
"""
检查 Docker 容器状态
Args:
container_name (str): 容器名称
Returns:
Dict[str, str]: 容器状态信息
"""
try:
print(f"🔍 检查 Docker 容器 {container_name} 状态...")
# 检查容器是否存在
result = subprocess.run(
["docker", "ps", "-a", "--filter", f"name={container_name}", "--format", "{{.Status}}"],
capture_output=True,
text=True
)
if result.returncode == 0 and result.stdout.strip():
status = result.stdout.strip()
print(f"✅ 容器 {container_name} 状态: {status}")
# 检查端口映射
port_result = subprocess.run(
["docker", "port", container_name],
capture_output=True,
text=True
)
ports = port_result.stdout.strip() if port_result.returncode == 0 else "无端口信息"
print(f" 端口映射: {ports}")
return {
"status": status,
"ports": ports
}
else:
print(f"❌ 容器 {container_name} 不存在")
return {
"status": "不存在",
"ports": "N/A"
}
except Exception as e:
print(f"❌ 检查容器状态时出错: {e}")
return {
"status": "检查失败",
"ports": "N/A"
}
def check_mindsdb_connection(self, host: str = "localhost", port: int = 47334) -> bool:
"""
检查 MindsDB 连接
Args:
host (str): 主机地址
port (int): 端口
Returns:
bool: 是否连接成功
"""
try:
print(f"🔍 检查 MindsDB 连接 ({host}:{port})...")
# 先检查端口连通性
if not self.check_port_connectivity(host, port):
return False
# 尝试连接 MindsDB
print(" 正在测试 MindsDB 连接...")
mdb = mindsdb.connect(host=host, port=port)
# 执行简单查询
result = mdb.query("SELECT 1")
if result:
print("✅ MindsDB 连接成功")
return True
else:
print("❌ MindsDB 连接失败")
return False
except Exception as e:
print(f"❌ MindsDB 连接测试失败: {e}")
return False
def run_comprehensive_check(self,
container_name: str = "mindsdb_container",
host: str = "localhost",
port: int = 47334) -> Dict[str, any]:
"""
运行全面连接检查
Args:
container_name (str): 容器名称
host (str): 主机地址
port (int): 端口
Returns:
Dict[str, any]: 检查结果
"""
print("🔍 开始全面连接检查")
print("=" * 40)
results = {}
# 1. 检查 Docker 容器状态
container_status = self.check_docker_container_status(container_name)
results["container_status"] = container_status
# 2. 检查端口连通性
port_connectivity = self.check_port_connectivity(host, port)
results["port_connectivity"] = port_connectivity
# 3. 检查 MindsDB 连接
mindsdb_connection = self.check_mindsdb_connection(host, port)
results["mindsdb_connection"] = mindsdb_connection
# 汇总结果
print("\n📊 连接检查汇总:")
all_checks_passed = all([
container_status["status"] != "不存在" and "Up" in container_status["status"],
port_connectivity,
mindsdb_connection
])
if all_checks_passed:
print("✅ 所有连接检查通过")
else:
print("❌ 部分连接检查失败")
self.provide_troubleshooting_suggestions(results)
return results
def provide_troubleshooting_suggestions(self, results: Dict[str, any]):
"""
提供故障排除建议
Args:
results (Dict[str, any]): 检查结果
"""
print("\n💡 故障排除建议:")
container_status = results.get("container_status", {})
if container_status.get("status") == "不存在":
print(" 1. MindsDB 容器未启动,请运行:")
print(" docker run -d --name mindsdb_container -p 47334:47334 mindsdb/mindsdb")
elif "Up" not in container_status.get("status", ""):
print(" 1. MindsDB 容器未正常运行,请检查:")
print(" docker logs mindsdb_container")
if not results.get("port_connectivity", True):
print(" 2. 端口无法访问,请检查:")
print(" - 防火墙设置")
print(" - 端口映射配置")
print(" - 网络连接")
if not results.get("mindsdb_connection", True):
print(" 3. MindsDB 服务异常,请检查:")
print(" - 容器日志: docker logs mindsdb_container")
print(" - 服务配置")
print(" - 资源限制")
def main():
"""
主函数 - 运行连接检查
"""
troubleshooter = ConnectionTroubleshooter()
troubleshooter.run_comprehensive_check()
if __name__ == "__main__":
# main()
print("连接问题排查工具准备就绪")
第九章:最佳实践与优化建议
为了确保你的 AI 应用开发顺利进行,以下是一些最佳实践建议:
9.1 数据清洗
在训练模型之前,确保数据已经清洗干净,去除重复值和缺失值。
9.2 特征工程
通过特征工程提取有用的特征,提高模型性能。
9.3 模型选择
根据数据集的特点选择合适的模型,例如 LightGBM 或 XGBoost。
9.4 模型评估
使用交叉验证等方法评估模型性能,确保模型的泛化能力。
9.5 持续监控
部署模型后,持续监控模型性能,及时调整模型参数。
第十章:扩展阅读与学习资源
为了进一步提升你的 AI 应用开发能力,以下是一些推荐的扩展阅读资源:
10.1 官方文档
10.2 学习书籍
10.3 在线课程
MindsDB 系统架构图
AI 应用开发流程图
项目实施计划甘特图
模型性能分布饼图
模型服务时序图
🏁 总结
本文详细介绍了如何使用 MindsDB 构建 AI 应用,从环境搭建到模型训练、部署的全过程。通过实践示例和详细步骤,帮助中国开发者快速上手 MindsDB,并解决常见的 SSL 证书问题和镜像拉取问题。
关键要点总结:
- 环境准备:正确安装 Docker 并配置国内镜像源
- 数据处理:准备高质量的训练数据是成功的关键
- 模型训练:使用 MindsDB 简化机器学习流程
- 模型部署:将训练好的模型部署为 API 服务
- 故障排除:掌握常见问题的诊断和解决方法
实践是检验真理的唯一标准,立即动手 构建属于你的 AI 预测系统吧!



















 1515
1515

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











