






摘要
AI与数据科学是当前最热门的技术领域。本文基于 Awesome AI & Data Science 资源,系统梳理主流工具、知识体系、开发流程与实践案例,结合生态全景、代码、思维导图、饼图、最佳实践和常见问题,助力中国开发者高效入门与进阶。
目录
- AI与数据科学发展与生态全景
- AI与数据科学知识体系详解
- 主流工具与库全景
- 数据获取与处理方法
- 实战案例:文本分类与数据可视化全流程
- 关键流程、架构图与数据分布
- 代码规范与最佳实践
- 常见问题与注意事项
- 扩展阅读与学习资源
- 总结与未来展望
- 参考资料
1. AI与数据科学发展与生态全景
1.1 发展历程
- 统计学 → 机器学习 → 深度学习 → 生成式AI
- 传统算法、神经网络、Transformer、大模型
1.2 生态全景
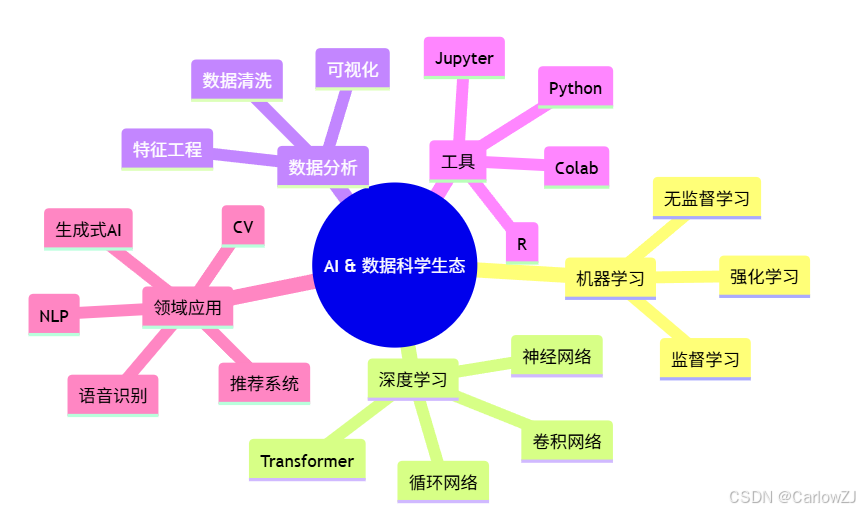
mindmap
root((AI & 数据科学生态))
机器学习
监督学习
无监督学习
强化学习
深度学习
神经网络
卷积网络
循环网络
Transformer
数据分析
数据清洗
特征工程
可视化
工具
Python
R
Jupyter
Colab
领域应用
NLP
CV
推荐系统
语音识别
生成式AI
1.3 社区与趋势
- GitHub、优快云、知乎、Kaggle、AIHub
- 大模型、AutoML、MLOps、AIGC、数据安全
2. AI与数据科学知识体系详解
2.1 机器学习基础
- 监督学习:分类、回归、支持向量机、决策树、集成方法
- 无监督学习:聚类、降维、关联规则
- 强化学习:Q-learning、策略梯度
2.2 深度学习
- 神经网络基础:感知机、反向传播
- 卷积神经网络(CNN):图像识别、目标检测
- 循环神经网络(RNN/LSTM/GRU):序列建模、NLP
- Transformer与大模型:BERT、GPT、LLM
2.3 数据分析与可视化
- 数据清洗、缺失值处理、异常检测
- 特征工程、特征选择、降维
- 可视化:折线图、柱状图、饼图、热力图、交互式仪表盘
2.4 MLOps与工程化
- 数据集管理、实验追踪、模型部署、自动化训练
- 工具:MLflow、DVC、Kubeflow、Airflow
Mermaid 知识体系思维导图
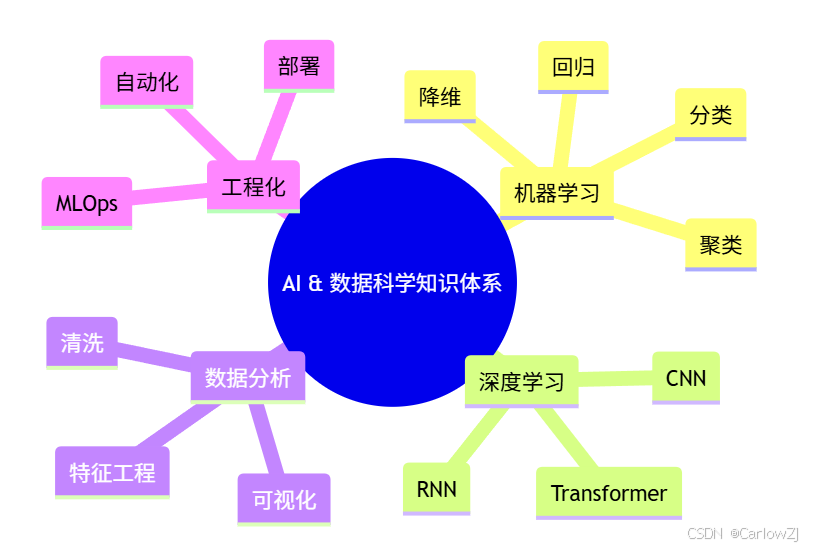
mindmap
root((AI & 数据科学知识体系))
机器学习
分类
回归
聚类
降维
深度学习
CNN
RNN
Transformer
数据分析
清洗
特征工程
可视化
工程化
MLOps
部署
自动化
3. 主流工具与库全景
3.1 Python 生态
- Numpy:数值计算基础
- Pandas:数据分析与处理
- Scikit-learn:机器学习算法
- Matplotlib:基础可视化
- Seaborn:统计可视化
- Jupyter:交互式开发
3.2 深度学习框架
- TensorFlow:Google 开源,支持分布式训练
- PyTorch:Facebook 开源,动态图机制
- Keras:高级神经网络 API
- ONNX:模型互操作
3.3 NLP与CV
3.4 AutoML与MLOps
3.5 其它工具
4. 数据获取与处理方法
4.1 数据集来源
- 开源数据集:Kaggle、UCI、OpenML、天池、AIHub
- API 抓取:requests、BeautifulSoup、Selenium
- 数据合成与增强:SMOTE、数据扩增
4.2 数据清洗与预处理
- 缺失值填充、异常值检测、重复值处理
- 特征编码(LabelEncoder、OneHotEncoder)
- 标准化、归一化、降维(PCA、t-SNE)
4.3 数据可视化
- Matplotlib/Seaborn/Plotly 绘制折线图、柱状图、饼图、热力图
- Mermaid 饼图、流程图、思维导图
5. 实战案例:文本分类与数据可视化全流程
5.1 需求描述
- 用 Scikit-learn 实现新闻文本分类,分析类别分布,绘制饼图
5.2 数据加载与探索
from sklearn.datasets import fetch_20newsgroups
categories = ['sci.space', 'rec.sport.baseball']
data = fetch_20newsgroups(subset='train', categories=categories)
print('类别数:', len(set(data.target)))
print('样本数:', len(data.data))
5.3 特征提取与建模
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(data.data)
y = data.target
clf = MultinomialNB()
clf.fit(X, y)
pred = clf.predict(X)
print('准确率:', accuracy_score(y, pred))
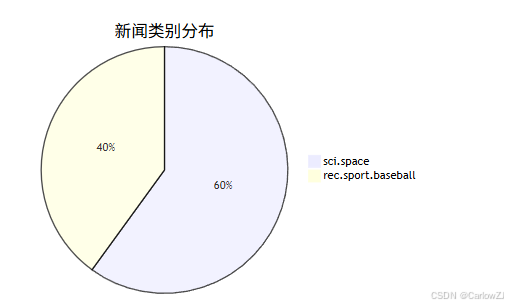
5.4 类别分布可视化
import matplotlib.pyplot as plt
import numpy as np
labels = [data.target_names[i] for i in np.unique(y)]
counts = [sum(y == i) for i in np.unique(y)]
plt.figure(figsize=(6,6))
plt.pie(counts, labels=labels, autopct='%1.1f%%')
plt.title('新闻类别分布')
plt.show()
5.5 Mermaid 饼图
5.6 Mermaid 流程图
6. 关键流程、架构图与数据分布
6.1 AI 项目架构图
6.2 数据分析全流程思维导图
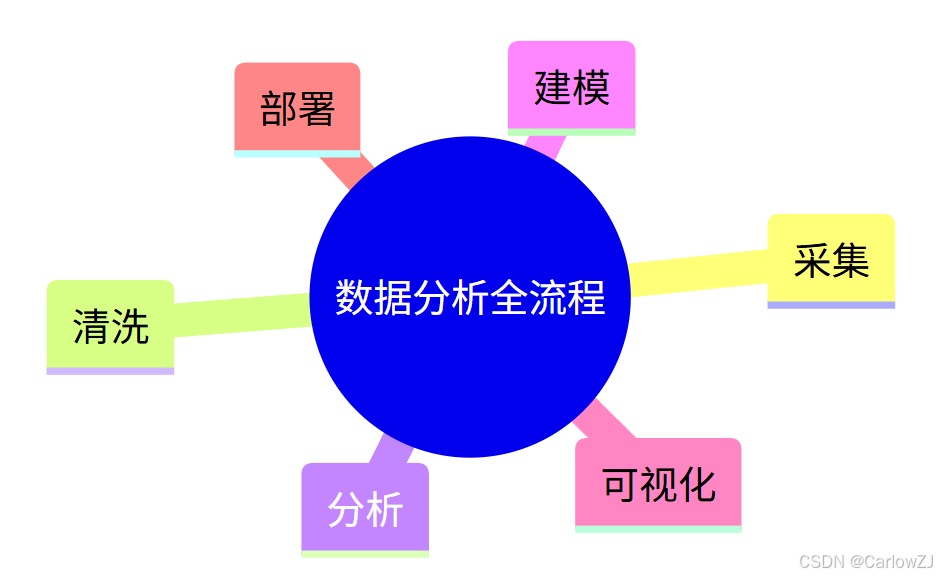
mindmap
root((数据分析全流程))
采集
清洗
分析
建模
可视化
部署
6.3 Mermaid 饼图
7. 代码规范与最佳实践
7.1 代码风格与结构
- 遵循 PEP8/Google/阿里巴巴等主流规范
- 变量、函数、类命名清晰,注释齐全
- 合理拆分模块,避免大文件
7.2 错误处理与日志
- try/except 捕获异常,输出友好提示
- 日志记录关键步骤,便于排查
7.3 依赖管理与环境隔离
- 使用 requirements.txt/conda/pipenv/poetry 管理依赖
- 固定依赖版本,保证可复现
7.4 自动化测试与持续集成
- 编写单元测试,集成 CI 工具
- 代码提交前自动格式化与检查
7.5 性能优化与安全
- 数据处理用 Numpy/Pandas 向量化操作
- 注意数据隐私与合规
8. 常见问题与注意事项
Q1:如何选择合适的 AI 框架?
- 根据项目需求、团队经验、社区活跃度选择。
Q2:如何保证数据质量?
- 数据清洗、异常值处理、特征工程。
Q3:如何提升模型效果?
- 尝试不同算法、调参、交叉验证。
Q4:如何高效学习 AI 生态?
- 结合官方文档、开源项目、优快云/知乎等中文社区
Q5:如何应对依赖冲突?
- 使用虚拟环境,定期清理无用包
Q6:如何提升团队协作效率?
- 规范代码、自动化流程、知识共享
9. 扩展阅读与学习资源
- Awesome Data Science
- Awesome Deep Learning
- Awesome Machine Learning
- Awesome MLOps
- Awesome NLP
- Awesome Computer Vision
- 优快云 AI 专栏
- 知乎:AI学习路线
- Kaggle 竞赛与数据集
- AIHub 数据集
10. 总结与未来展望
AI 与数据科学为开发者提供了无限可能。善用 Awesome 资源,结合最佳实践,能大幅提升开发效率和项目质量。未来,随着大模型、AutoML、MLOps、AIGC 等新技术的发展,AI 生态将持续扩展,成为开发者创新与成长的重要平台。
实践建议:
- 先掌握主流库与工具,逐步深入
- 多做项目实战,积累经验
- 关注社区动态,持续学习
- 善用自动化工具,提升效率



















 624
624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











