






摘要
本文系统梳理LLaMA-Factory大模型微调框架中的数据准备与处理全流程,涵盖数据格式规范、预处理、增强、验证、管理、常见问题与最佳实践。通过丰富的思维导图、流程图、甘特图、饼图、时序图等可视化手段,结合详实的Python代码和实战经验,助力中国AI开发者高效打造高质量训练数据集。
目录
1. 知识体系思维导图
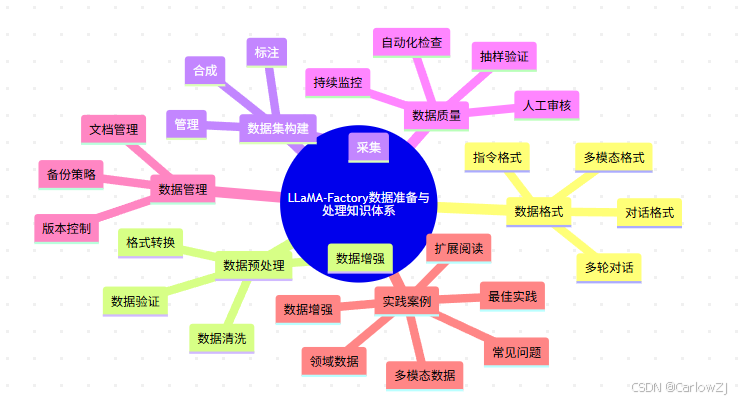
mindmap
root((LLaMA-Factory数据准备与处理知识体系))
数据格式
对话格式
指令格式
多轮对话
多模态格式
数据预处理
数据清洗
格式转换
数据增强
数据验证
数据集构建
采集
标注
合成
管理
数据质量
自动化检查
人工审核
抽样验证
持续监控
数据管理
版本控制
备份策略
文档管理
实践案例
领域数据
多模态数据
数据增强
常见问题
最佳实践
扩展阅读
2. 数据格式与分布
2.1 常用数据格式分布
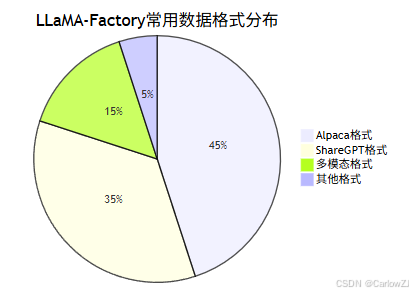
重点:
- 推荐优先采用标准对话格式,便于兼容主流大模型。
- 多模态任务需关注图片、音频等数据的格式与标注。
2.2 典型数据格式示例
# Alpaca指令格式示例
{
"instruction": "请用一句话介绍LLaMA-Factory。",
"input": "",
"output": "LLaMA-Factory是一个高效的大模型微调框架。"
}
# ShareGPT对话格式示例
{
"conversations": [
{"from": "human", "value": "你好,请介绍一下自己。"},
{"from": "assistant", "value": "你好!我是一个AI助手,由LLaMA-Factory微调训练而成。"}
]
}
# 多模态格式示例
{
"conversations": [
{"from": "human", "value": "请描述这张图片。", "images": ["1.jpg"]},
{"from": "assistant", "value": "这是一张风景图片。"}
]
}
3. 数据准备与处理全流程
3.1 全流程业务图
3.2 实施计划甘特图
3.3 交互时序图
4. 数据预处理与增强实践
4.1 数据清洗与格式转换
# 数据清洗与格式转换示例
import json
def clean_and_convert(input_path, output_path):
"""清洗原始数据并转换为标准格式"""
with open(input_path, 'r', encoding='utf-8') as f:
raw_data = json.load(f)
cleaned = []
for item in raw_data:
# 只保留有用字段,去除无效内容
if 'instruction' in item and 'output' in item:
cleaned.append({
'instruction': item['instruction'].strip(),
'input': item.get('input', '').strip(),
'output': item['output'].strip()
})
with open(output_path, 'w', encoding='utf-8') as f:
json.dump(cleaned, f, ensure_ascii=False, indent=2)
# 用法示例
clean_and_convert('data/raw.json', 'data/cleaned.json')
4.2 数据增强技术
# 简单的数据增强:同义句替换
import random
def synonym_augment(text):
synonyms = {
'高效': ['高性能', '高效能'],
'微调': ['调优', '优化'],
'框架': ['平台', '系统']
}
for word, syns in synonyms.items():
if word in text and random.random() < 0.5:
text = text.replace(word, random.choice(syns))
return text
# 用法示例
print(synonym_augment('LLaMA-Factory是一个高效的大模型微调框架。'))
4.3 多模态数据处理
# 多模态数据校验示例
import os
def check_multimodal_data(data, image_dir):
for i, item in enumerate(data):
for turn in item.get('conversations', []):
if 'images' in turn:
for img in turn['images']:
img_path = os.path.join(image_dir, img)
if not os.path.exists(img_path):
print(f"第{i}条数据缺少图片文件: {img_path}")
# 用法示例
# check_multimodal_data(data, 'data/mllm_demo_data')
5. 数据验证与质量控制
5.1 自动化验证脚本
# 数据字段完整性验证
import json
def validate_fields(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
data = json.load(f)
for i, item in enumerate(data):
if 'instruction' not in item or 'output' not in item:
print(f"第{i}条数据缺少instruction或output字段")
# 用法示例
validate_fields('data/cleaned.json')
5.2 数据抽样与人工审核
# 随机抽样人工审核
import json
import random
def sample_for_review(file_path, sample_size=5):
with open(file_path, 'r', encoding='utf-8') as f:
data = json.load(f)
samples = random.sample(data, min(sample_size, len(data)))
for i, item in enumerate(samples):
print(f"样本{i+1}: {item}")
# 用法示例
sample_for_review('data/cleaned.json')
6. 数据集管理与版本控制
6.1 版本控制与备份
- 建议使用Git等工具管理数据集变更,配合定期备份,保障数据安全。
- 关键数据集应多地存储,防止单点故障。
6.2 文档与流程管理
- 每个数据集应配备详细说明文档,记录来源、处理流程、字段定义等。
- 重要变更需有变更日志,便于溯源和回滚。
7. 实战案例与常见问题
7.1 行业实践案例
- 医疗领域:通过数据清洗和增强,提升医疗问答模型的准确率。
- 多模态应用:图片+文本联合标注,助力文旅、教育等场景。
- 领域知识注入:采集行业对话,构建专属知识库。
7.2 常见问题与解决方案
Q1:数据格式报错怎么办?
- 检查字段是否齐全,建议用自动化脚本批量校验。
Q2:数据分布不均衡如何处理?
- 采用重采样、类别权重调整或数据增强。
Q3:多模态数据缺失?
- 检查图片/音频文件路径,确保与标注一致。
8. 最佳实践与扩展阅读
8.1 实施建议
- 数据优先:高质量数据决定模型上限。
- 自动化+人工:结合自动化校验与人工审核,提升数据可靠性。
- 持续管理:数据集全生命周期管理,保障可追溯性。
- 文档完善:每个数据集都应有详细说明和变更记录。
8.2 扩展阅读
9. 参考资料
- 《LLaMA-Factory数据准备与处理》
- 《LLaMA-Factory数据集格式详解》
- Hugging Face Datasets官方文档
- 数据增强与清洗相关论文
- 领域数据集构建实践
总结
高质量的数据是大模型微调成功的基石。通过本文的全流程梳理与实战案例,读者可系统掌握LLaMA-Factory数据准备与处理的关键技术,助力AI应用高效落地。欢迎留言交流,共同进步!



















 1152
1152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











