



摘要
本文系统梳理LLaMA-Factory大语言模型微调框架的架构、核心功能、数据准备、模型微调、多模态训练、分布式与性能优化、安全与部署、评估与监控、实践案例、常见问题与最佳实践。通过丰富的架构图、流程图、思维导图、甘特图、饼图、时序图等可视化手段,结合详实的Python代码和实战经验,助力中国AI开发者高效落地大模型应用。
目录
1. 系统架构总览
1.1 架构思维导图
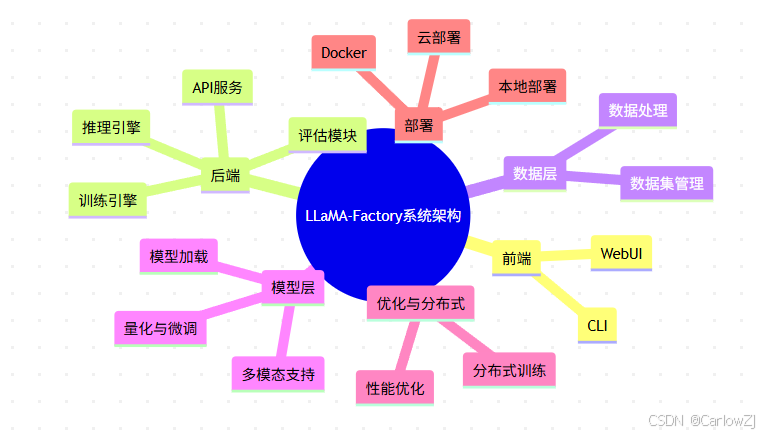
mindmap
root((LLaMA-Factory系统架构))
前端
WebUI
CLI
后端
API服务
训练引擎
推理引擎
评估模块
数据层
数据处理
数据集管理
模型层
模型加载
量化与微调
多模态支持
优化与分布式
性能优化
分布式训练
部署
Docker
云部署
本地部署
1.2 系统组件关系图
1.3 端到端业务流程
2. 数据准备与管理
2.1 数据格式与分布
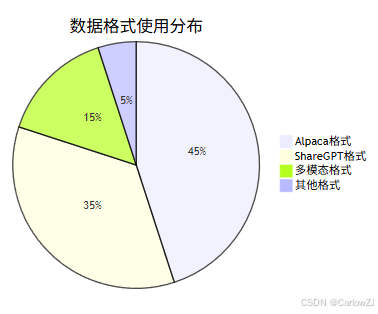
重点:
- 推荐优先采用标准对话格式,便于兼容主流大模型。
- 多模态任务需关注图片、音频等数据的格式与标注。
2.2 数据处理全流程
2.3 Python数据校验示例
# 数据格式校验示例,确保每条数据包含必要字段
import json
def validate_data(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
data = json.load(f)
for i, item in enumerate(data):
if 'conversations' not in item:
print(f"第{i}条数据缺少conversations字段")
else:
for turn in item['conversations']:
if 'from' not in turn or 'value' not in turn:
print(f"第{i}条对话轮次缺少from或value字段")
# 用法示例
validate_data('data/alpaca_zh_demo.json')
3. 模型微调全流程
3.1 微调业务流程图
3.2 Python微调主流程
# LLaMA-Factory微调主流程示例
import subprocess
def train_llama_factory(config_path):
"""调用llamafactory-cli进行模型微调"""
try:
result = subprocess.run([
'llamafactory-cli', 'train', config_path
], check=True, capture_output=True, text=True)
print(result.stdout)
except subprocess.CalledProcessError as e:
print("训练失败:", e.stderr)
# 用法示例
train_llama_factory('examples/train_lora/llama3_lora_sft.yaml')
3.3 典型配置片段
# 以LoRA微调为例的配置片段
model_name_or_path: llama3-8b
adapter_type: lora
learning_rate: 1e-4
per_device_train_batch_size: 4
dataset: alpaca_zh_demo
output_dir: output/llama3_lora_sft
4. 多模态训练实践
4.1 多模态架构图
mindmap
root((LLaMA-Factory知识体系))
多模态训练
文本-图像
文本-音频
4.2 多模态训练流程
from llamafactory import create_model_and_tokenizer
from datasets import load_dataset
from PIL import Image
import torch
from torchvision import transforms
# 加载多模态数据集
raw_dataset = load_dataset('coco_caption', split='train')
# 图像预处理
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor()
])
# 加载模型
model, tokenizer = create_model_and_tokenizer('qwen/Qwen-VL-Chat')
# 训练循环(伪代码)
for example in raw_dataset:
image = Image.open(example['image_path'])
image_tensor = transform(image)
text = example['caption']
# ...送入模型训练
5. 分布式与性能优化
5.1 分布式训练架构
5.2 性能优化甘特图
5.3 分布式训练代码片段
from llamafactory import create_model_and_tokenizer, create_trainer
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDP
# 初始化分布式环境
if not dist.is_initialized():
dist.init_process_group(backend='nccl')
# 加载模型
model, tokenizer = create_model_and_tokenizer('llama3-8b')
model = DDP(model)
# 创建Trainer并训练
trainer = create_trainer(model, tokenizer)
trainer.train()
6. 安全与企业级部署
6.1 安全架构图
6.2 Docker部署示例
# 拉取官方镜像
sudo docker pull hiyouga/llamafactory:latest
# 运行容器
sudo docker run -it --rm --gpus=all --ipc=host hiyouga/llamafactory:latest
7. 模型评估与监控
7.1 评估指标体系
7.2 评估与监控代码
# 评估模型困惑度
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
def evaluate_perplexity(model_name, eval_text):
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
inputs = tokenizer(eval_text, return_tensors='pt')
with torch.no_grad():
outputs = model(**inputs, labels=inputs['input_ids'])
loss = outputs.loss
perplexity = torch.exp(loss)
print(f"困惑度: {perplexity.item():.2f}")
# 用法示例
evaluate_perplexity('llama3-8b', '你好,请介绍一下你自己。')
8. 实战案例与常见问题
8.1 典型应用案例
- 新闻标题分类器:基于DeepSeek-R1-Distill-Qwen-7B微调,提升中文新闻理解能力。
- 多模态文旅助手:Qwen2-VL微调,支持图文问答。
- 角色扮演对话:LLaMA3模型微调,适用于智能客服。
8.2 常见问题分布
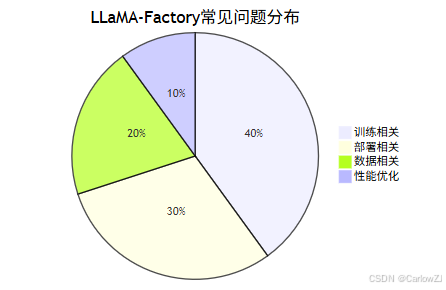
常见问题FAQ举例:
Q1:训练显存不足怎么办?
- 优先使用QLoRA/LoRA微调,或减小batch size。
- 检查数据集是否过大,适当裁剪。
Q2:推理速度慢如何优化?
- 启用vLLM推理加速。
- 使用模型量化,降低显存占用。
Q3:数据格式报错?
- 检查数据字段是否齐全,建议用上文Python校验脚本。
9. 最佳实践与扩展阅读
9.1 实施建议
- 数据优先:高质量数据决定模型上限。
- 资源评估:根据硬件选择微调方法。
- 监控全程:训练、评估、部署全流程监控。
- 自动化脚本:提升开发与运维效率。
- 持续学习:关注社区与官方文档更新。
9.2 扩展阅读
10. 参考资料
- 《LLaMA-Factory官方指南》
- 《LLaMA-Factory数据准备与处理》
- 《LLaMA-Factory模型微调实战》
- 《LLaMA-Factory多模态训练》
- 《LLaMA-Factory分布式训练与性能优化》
- 《LLaMA-Factory安全与隐私保护》
- 《LLaMA-Factory企业级应用实践》
- 《LLaMA-Factory模型评估与优化》
- 官方GitHub与社区博客
- 相关论文与技术文档
总结
LLaMA-Factory为中国AI开发者提供了高效、灵活、可扩展的大模型微调与部署平台。通过本文的全景梳理与实战案例,读者可系统掌握从数据到部署的全流程,快速落地AI应用。欢迎留言交流,共同进步!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











