



摘要
强化学习是机器学习中的一个重要分支,它通过智能体(Agent)与环境(Environment)的交互来学习最优行为策略。近年来,强化学习在游戏、机器人控制、智能决策等领域取得了显著的成果。本文将详细介绍强化学习的基本概念、核心算法、应用场景以及实现代码。通过数据流图和流程图,帮助读者更好地理解强化学习的工作原理和实现细节。同时,本文还将探讨在实际应用中需要注意的问题,并总结强化学习的优缺点。
一、引言
-
介绍强化学习的背景和重要性。
-
强化学习在人工智能领域的地位和发展趋势。
-
说明本文的目标和结构安排。
二、强化学习的基本概念
(一)强化学习的定义
-
强化学习是一种通过试错(trial-and-error)来学习最优行为策略的方法。
-
引用Sutton和Barto的定义:“强化学习是关于智能体如何在环境中采取行动以最大化累积奖励的研究。”
(二)强化学习的关键要素
1. 智能体(Agent)
-
智能体是学习和决策的主体,它根据当前状态选择行动。
-
智能体的目标是最大化累积奖励。
2. 环境(Environment)
-
环境是智能体所处的外部世界,它接收智能体的行动并返回新的状态和奖励。
-
环境可以是离散的或连续的。
3. 状态(State)
-
状态是环境的当前情况的描述,智能体根据状态选择行动。
-
状态可以是离散的或连续的。
4. 行动(Action)
-
行动是智能体在环境中可以采取的操作。
-
行动的选择基于当前状态和策略。
5. 奖励(Reward)
-
奖励是环境对智能体行动的反馈,用于指导智能体的行为。
-
奖励信号是标量值,可以是正的、负的或零。
(三)强化学习的目标
-
强化学习的目标是学习一个最优策略(Policy),使得智能体在长期运行中获得的最大累积奖励。
三、强化学习的数学模型
(一)马尔可夫决策过程(MDP)
-
MDP是强化学习的数学模型,它描述了智能体与环境的交互过程。
-
MDP由状态集合、行动集合、转移概率和奖励函数组成。
(二)策略(Policy)
-
策略是智能体在给定状态下选择行动的规则。
-
策略可以是确定性的或随机性的。
(三)价值函数(Value Function)
-
价值函数用于评估状态或行动的价值。
-
状态价值函数(State Value Function)和行动价值函数(Action Value Function)的定义。
(四)贝尔曼方程(Bellman Equation)
-
贝尔曼方程是强化学习中的核心方程,用于递归地计算价值函数。
-
贝尔曼期望方程和贝尔曼最优方程的区别。
四、强化学习的核心算法
(一)值函数方法(Value-based Methods)
1. Q学习(Q-Learning)
-
Q学习是一种无模型的强化学习算法,它通过学习行动价值函数来选择最优行动。
-
Q学习的更新公式和算法流程。
2. 深度Q网络(DQN)
-
DQN是Q学习的深度学习版本,它使用神经网络来近似行动价值函数。
-
DQN的架构和训练过程。
(二)策略梯度方法(Policy Gradient Methods)
1. REINFORCE算法
-
REINFORCE算法是一种基于策略梯度的强化学习算法,它直接优化策略函数。
-
REINFORCE算法的更新公式和算法流程。
2. 深度确定性策略梯度(DDPG)
-
DDPG是一种用于连续行动空间的策略梯度算法,它结合了值函数方法和策略梯度方法。
-
DDPG的架构和训练过程。
(三)Actor-Critic方法
-
Actor-Critic方法结合了值函数方法和策略梯度方法的优点,它同时学习策略函数和价值函数。
-
Actor-Critic算法的架构和训练过程。
五、强化学习的应用场景
(一)游戏
-
强化学习在游戏中的应用,如AlphaGo、AlphaStar等。
-
强化学习如何帮助智能体在游戏中取得胜利。
(二)机器人控制
-
强化学习在机器人控制中的应用,如机器人路径规划、抓取等。
-
强化学习如何帮助机器人学习最优控制策略。
(三)智能决策
-
强化学习在智能决策中的应用,如金融投资、资源分配等。
-
强化学习如何帮助智能体做出最优决策。
(四)自然语言处理
-
强化学习在自然语言处理中的应用,如机器翻译、文本生成等。
-
强化学习如何帮助智能体生成高质量的文本。
六、强化学习的实现代码示例
(一)Q学习的Python实现
import numpy as np
# 初始化参数
num_states = 10
num_actions = 2
q_table = np.zeros((num_states, num_actions))
learning_rate = 0.1
discount_factor = 0.9
epsilon = 0.1
num_episodes = 1000
# Q学习算法
for episode in range(num_episodes):
state = np.random.randint(0, num_states)
done = False
while not done:
# ε-greedy策略选择行动
if np.random.rand() < epsilon:
action = np.random.randint(0, num_actions)
else:
action = np.argmax(q_table[state])
# 执行行动,获得新的状态和奖励
next_state, reward, done = env.step(state, action)
# 更新Q值
q_table[state, action] += learning_rate * (reward + discount_factor * np.max(q_table[next_state]) - q_table[state, action])
state = next_state
(二)DQN的Python实现
import torch
import torch.nn as nn
import torch.optim as optim
# 定义DQN网络
class DQN(nn.Module):
def __init__(self, input_dim, output_dim):
super(DQN, self).__init__()
self.fc1 = nn.Linear(input_dim, 128)
self.fc2 = nn.Linear(128, 128)
self.fc3 = nn.Linear(128, output_dim)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
# 初始化参数
input_dim = 10
output_dim = 2
dqn = DQN(input_dim, output_dim)
optimizer = optim.Adam(dqn.parameters(), lr=0.001)
criterion = nn.MSELoss()
replay_buffer = []
batch_size = 32
num_episodes = 1000
# DQN训练过程
for episode in range(num_episodes):
state = env.reset()
done = False
while not done:
# ε-greedy策略选择行动
if np.random.rand() < epsilon:
action = np.random.randint(0, output_dim)
else:
q_values = dqn(torch.tensor(state, dtype=torch.float32))
action = torch.argmax(q_values).item()
# 执行行动,获得新的状态和奖励
next_state, reward, done = env.step(action)
# 将经验存储到回放缓冲区
replay_buffer.append((state, action, reward, next_state, done))
# 从回放缓冲区中采样一批经验进行训练
if len(replay_buffer) > batch_size:
batch = np.random.choice(len(replay_buffer), batch_size, replace=False)
for idx in batch:
state, action, reward, next_state, done = replay_buffer[idx]
q_values = dqn(torch.tensor(state, dtype=torch.float32))
target_q_values = q_values.clone()
if done:
target_q_values[action] = reward
else:
next_q_values = dqn(torch.tensor(next_state, dtype=torch.float32))
target_q_values[action] = reward + discount_factor * torch.max(next_q_values)
loss = criterion(q_values, target_q_values)
optimizer.zero_grad()
loss.backward()
optimizer.step()
state = next_state
七、强化学习的数据流图
(一)Q学习的数据流图
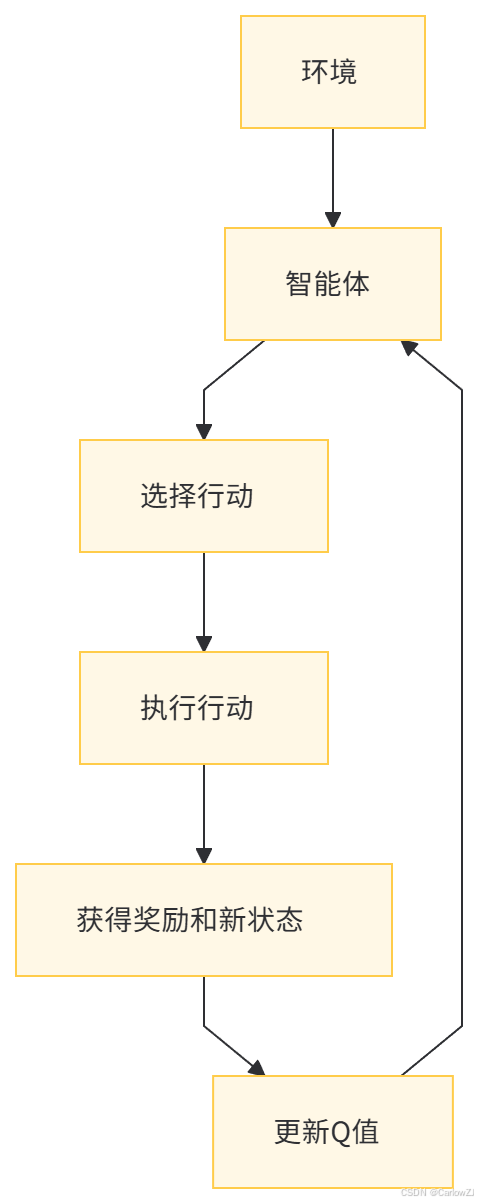
(二)DQN的数据流图
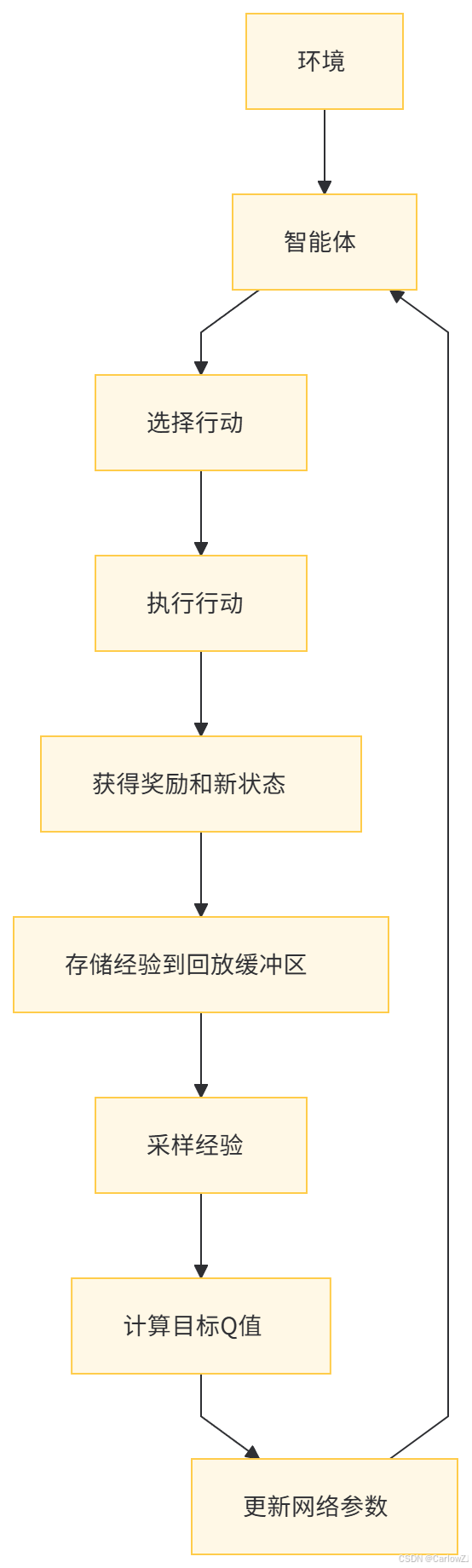
八、使用强化学习时的注意事项
(一)探索与利用的平衡
-
探索新行动与利用已知最优行动之间的平衡是强化学习中的关键问题。
-
ε-greedy策略、Softmax策略等方法可以有效解决探索与利用的平衡问题。
(二)奖励设计
-
奖励设计对强化学习的性能有重要影响。
-
奖励信号应该能够正确引导智能体的行为,避免误导智能体。
(三)环境的复杂性
-
环境的复杂性会影响强化学习的训练难度。
-
对于复杂的环境,可能需要更复杂的算法和更多的训练时间。
(四)算法的选择
-
不同的强化学习算法适用于不同的问题。
-
选择合适的算法可以提高强化学习的效率和性能。
(五)模型的泛化能力
-
强化学习模型的泛化能力决定了其在新环境中的表现。
-
通过数据增强、正则化等方法可以提高模型的泛化能力。
九、总结
-
强化学习是一种通过智能体与环境的交互来学习最优行为策略的方法。
-
强化学习的核心算法包括值函数方法、策略梯度方法和Actor-Critic方法。
-
强化学习在游戏、机器人控制、智能决策等领域有广泛的应用。
-
在使用强化学习时需要注意探索与利用的平衡、奖励设计、环境的复杂性、算法的选择和模型的泛化能力等问题。



















 1738
1738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











