



摘要
Transformer架构是近年来自然语言处理(NLP)领域的一项重大突破,它通过自注意力机制(Self-Attention)和多头注意力机制(Multi-Head Attention)实现了对长距离依赖关系的有效建模。本文将详细介绍Transformer架构的核心概念、工作原理、实现方法、应用场景以及开发中需要注意的问题。通过理论讲解、代码示例和实际应用案例,帮助读者全面掌握Transformer架构的核心技术和实践方法。
一、Transformer架构的概念讲解
(一)背景与动机
传统的循环神经网络(RNN)及其变体(如LSTM和GRU)在处理长序列数据时存在梯度消失和梯度爆炸的问题,并且难以并行化处理,导致训练速度较慢。Transformer架构通过引入自注意力机制,克服了这些缺点,能够高效地处理长序列数据。
(二)核心概念
-
自注意力机制(Self-Attention)
-
自注意力机制允许模型在计算某个词的表示时,同时考虑句子中其他所有词的信息,从而捕捉长距离依赖关系。
-
计算公式:
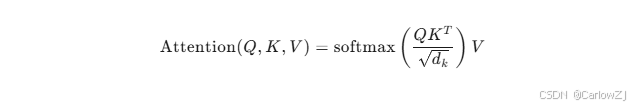
其中,Q、K、V分别代表查询(Query)、键(Key)、值(Value),dk是键向量的维度。
-
-
多头注意力机制(Multi-Head Attention)
-
多头注意力机制将输入分成多个不同的“头”,分别计算自注意力,然后将结果拼接起来。这样可以捕捉不同子空间中的信息。
-
多头注意力的计算公式:
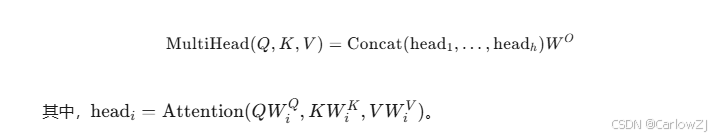
-
-
位置编码(Positional Encoding)
-
由于Transformer架构不依赖于序列的顺序信息,因此需要通过位置编码来引入位置信息。位置编码可以是固定的正弦余弦函数,也可以是可学习的参数。
-
(三)架构设计
Transformer架构由编码器(Encoder)和解码器(Decoder)组成。编码器负责将输入序列编码为上下文表示,解码器则利用这些上下文表示生成输出序列。
(四)架构图
二、Transformer架构的工作原理
(一)编码器(Encoder)
编码器由多个相同的层组成,每层包含两个主要模块:
-
多头自注意力模块
-
对输入序列进行自注意力计算,捕捉序列内部的依赖关系。
-
-
前馈神经网络
-
对每个位置的向量进行非线性变换。
-
(二)解码器(Decoder)
解码器也由多个相同的层组成,每层包含三个主要模块:
-
掩码多头自注意力模块
-
对输出序列进行自注意力计算,同时引入掩码机制,防止当前位置看到未来的信息。
-
-
多头注意力模块
-
使用编码器的输出作为键(Key)和值(Value),解码器的输出作为查询(Query),进行注意力计算。
-
-
前馈神经网络
-
对每个位置的向量进行非线性变换。
-
(三)数据流图

三、Transformer架构的代码示例
(一)使用TensorFlow实现Transformer
import tensorflow as tf
from tensorflow.keras import layers, models
def scaled_dot_product_attention(q, k, v, mask=None):
matmul_qk = tf.matmul(q, k, transpose_b=True)
dk = tf.cast(tf.shape(k)[-1], tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
if mask is not None:
scaled_attention_logits += (tf.cast(mask, tf.float32) * -1e9)
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1)
output = tf.matmul(attention_weights, v)
return output, attention_weights
class MultiHeadAttention(layers.Layer):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0
self.depth = d_model // self.num_heads
self.wq = layers.Dense(d_model)
self.wk = layers.Dense(d_model)
self.wv = layers.Dense(d_model)
self.dense = layers.Dense(d_model)
def split_heads(self, x, batch_size):
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.depth))
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, v, k, q, mask):
batch_size = tf.shape(q)[0]
q = self.wq(q)
k = self.wk(k)
v = self.wv(v)
q = self.split_heads(q, batch_size)
k = self.split_heads(k, batch_size)
v = self.split_heads(v, batch_size)
scaled_attention, attention_weights = scaled_dot_product_attention(q, k, v, mask)
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3])
concat_attention = tf.reshape(scaled_attention, (batch_size, -1, self.d_model))
output = self.dense(concat_attention)
return output, attention_weights
# 示例:创建一个MultiHeadAttention层
mha = MultiHeadAttention(d_model=512, num_heads=8)
(二)完整的Transformer模型
class Transformer(models.Model):
def __init__(self, num_layers, d_model, num_heads, dff, input_vocab_size, target_vocab_size, pe_input, pe_target, rate=0.1):
super(Transformer, self).__init__()
self.encoder = Encoder(num_layers, d_model, num_heads, dff, input_vocab_size, pe_input, rate)
self.decoder = Decoder(num_layers, d_model, num_heads, dff, target_vocab_size, pe_target, rate)
self.final_layer = layers.Dense(target_vocab_size)
def call(self, inp, tar, training, enc_padding_mask, look_ahead_mask, dec_padding_mask):
enc_output = self.encoder(inp, training, enc_padding_mask)
dec_output, attention_weights = self.decoder(tar, enc_output, training, look_ahead_mask, dec_padding_mask)
final_output = self.final_layer(dec_output)
return final_output, attention_weights
# 示例:创建一个Transformer模型
transformer = Transformer(num_layers=4, d_model=128, num_heads=8, dff=512, input_vocab_size=8500, target_vocab_size=8000, pe_input=10000, pe_target=6000)
四、Transformer架构的应用场景
(一)机器翻译
Transformer架构在机器翻译任务中表现出色,例如Google的神经机器翻译系统(GNMT)和OpenAI的GPT系列模型都基于Transformer架构。
(二)文本生成
Transformer架构可以用于生成文本,如新闻文章、故事、诗歌等。例如,GPT-3能够生成高质量的自然语言文本。
(三)问答系统
Transformer架构可以用于构建问答系统,通过理解问题的语义并从知识库中检索答案。
(四)情感分析
Transformer架构可以用于情感分析任务,通过分析文本的情感倾向来判断文本的正面或负面情感。
五、开发Transformer架构的注意事项
(一)数据预处理
-
对输入文本进行分词处理,如使用BERT的WordPiece分词方法。
-
将文本序列填充到固定长度,以便批量处理。
(二)模型训练
-
使用较大的学习率和学习率衰减策略。
-
使用批量归一化(Batch Normalization)或层归一化(Layer Normalization)加速训练过程。
(三)过拟合问题
-
使用Dropout技术防止过拟合。
-
使用正则化方法(如L2正则化)约束模型复杂度。
(四)性能优化
-
使用GPU或TPU加速训练过程。
-
优化模型结构,减少计算量。
六、总结
Transformer架构是自然语言处理领域的一项重要突破,通过自注意力机制和多头注意力机制,能够高效地处理长序列数据。本文详细介绍了Transformer架构的核心概念、工作原理、实现方法、应用场景以及开发中需要注意的问题。希望本文能够为读者提供有价值的参考,帮助读者更好地理解和应用Transformer架构。




















 1509
1509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











