



摘要
联邦学习(Federated Learning)是一种分布式机器学习技术,允许多个参与方在不共享数据的情况下协作训练模型。本文将详细介绍联邦学习的基本概念、技术架构、实现方法以及应用场景。通过代码示例和架构图,我们将逐步剖析联邦学习的工作原理,并讨论其在实际应用中的注意事项。文章最后将总结联邦学习技术的发展趋势和未来展望,帮助读者全面理解这一前沿技术。
一、引言
-
背景介绍
-
随着数据隐私保护法规的日益严格,传统的集中式数据处理方式面临诸多挑战。联邦学习作为一种能够在保护隐私的同时实现模型训练的技术,受到了广泛关注。
-
-
研究意义
-
联邦学习能够在保护用户隐私的同时,充分利用分布式数据资源,提升模型性能。
-
二、联邦学习的基本概念
(一)定义
-
联邦学习
-
联邦学习是一种分布式机器学习框架,允许多个参与方(客户端)在不共享数据的情况下协作训练全局模型。
-
-
核心特点
-
数据隐私保护:数据保留在本地,不进行共享。
-
分布式训练:模型在多个客户端上并行训练。
-
异构数据支持:支持不同客户端上的数据分布差异。
-
(二)联邦学习的类型
-
横向联邦学习
-
参与方的特征空间相同,样本空间不同。
-
-
纵向联邦学习
-
参与方的样本空间相同,特征空间不同。
-
-
联邦迁移学习
-
参与方的样本空间和特征空间均不同。
-
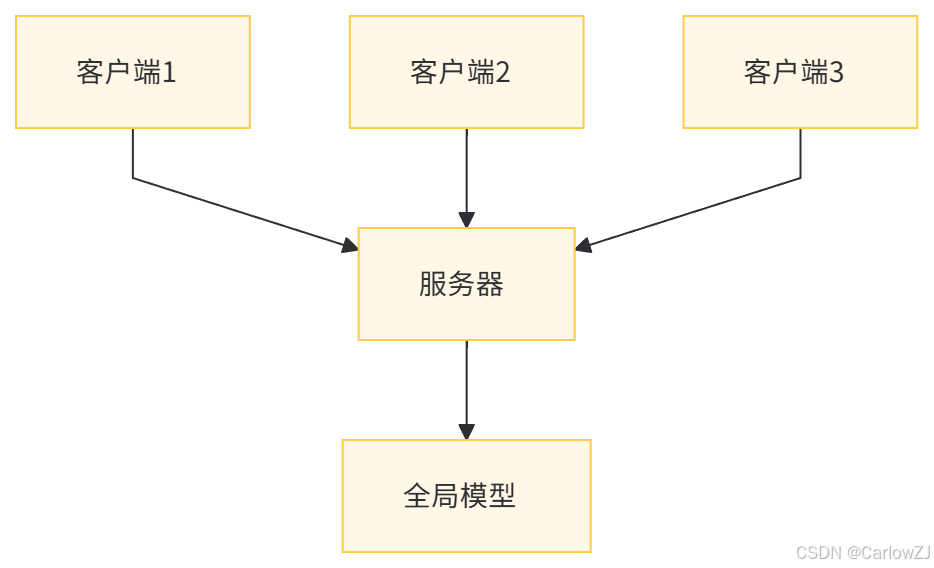
三、联邦学习的技术架构
(一)架构概述
-
客户端(Client)
-
数据所有者,负责在本地训练模型。
-
-
服务器(Server)
-
协调全局模型的更新,聚合客户端的模型参数。
-
-
通信机制
-
客户端与服务器之间的通信协议,确保数据传输的安全性和效率。
-
(二)架构图
四、联邦学习的关键技术
(一)模型聚合
-
加权平均聚合
-
根据客户端的数据量对模型参数进行加权平均。
-
-
安全聚合
-
使用加密技术确保聚合过程的安全性。
-
(二)隐私保护
-
差分隐私
-
在模型更新中添加噪声,保护隐私。
-
-
同态加密
-
允许在加密数据上直接进行计算。
-
(三)通信优化
-
压缩技术
-
对模型参数进行压缩,减少通信量。
-
-
异步通信
-
允许客户端异步更新模型,提高效率。
-
五、联邦学习的实现方式
(一)代码示例
1. TensorFlow Federated 示例
import tensorflow as tf
import tensorflow_federated as tff
# 定义一个简单的模型
def create_model():
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(10, activation='relu', input_shape=(784,)),
tf.keras.layers.Dense(10, activation='softmax')
])
return model
# 定义联邦学习策略
def model_fn():
model = create_model()
return tff.learning.from_keras_model(
model,
input_spec=train_data.element_spec,
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()]
)
# 构建联邦学习过程
iterative_process = tff.learning.build_federated_averaging_process(model_fn)
# 模拟客户端数据
train_data = [tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(20) for _ in range(10)]
# 训练联邦学习模型
state = iterative_process.initialize()
for round_num in range(1, 11):
state, metrics = iterative_process.next(state, train_data)
print(f'Round {round_num}, Metrics: {metrics}')
2. PyTorch 示例
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
# 定义一个简单的模型
class SimpleModel(nn.Module):
def __init__(self):
super(SimpleModel, self).__init__()
self.fc = nn.Linear(784, 10)
def forward(self, x):
return self.fc(x)
# 定义联邦学习训练过程
def federated_train(model, client_data, epochs=5):
client_models = []
for data in client_data:
client_model = SimpleModel()
client_model.load_state_dict(model.state_dict())
optimizer = optim.SGD(client_model.parameters(), lr=0.01)
for epoch in range(epochs):
for inputs, labels in data:
optimizer.zero_grad()
outputs = client_model(inputs)
loss = nn.CrossEntropyLoss()(outputs, labels)
loss.backward()
optimizer.step()
client_models.append(client_model.state_dict())
return client_models
# 模拟客户端数据
client_data = [DataLoader(dataset, batch_size=20) for dataset in datasets]
# 初始化全局模型
global_model = SimpleModel()
# 联邦学习训练
for round_num in range(1, 11):
client_models = federated_train(global_model, client_data)
# 聚合客户端模型
for key in global_model.state_dict().keys():
global_model.state_dict()[key] = torch.mean(torch.stack([model[key] for model in client_models]), dim=0)
print(f'Round {round_num}, Global Model Updated')
六、联邦学习的应用场景
(一)移动设备
-
分布式训练
-
在移动设备上训练模型,保护用户隐私。
-
-
个性化推荐
-
根据用户数据提供个性化服务。
-
(二)医疗领域
-
多中心研究
-
在保护患者隐私的前提下,联合多家医院的数据进行研究。
-
-
疾病预测
-
利用分布式数据训练疾病预测模型。
-
(三)金融领域
-
风险评估
-
联合多家金融机构的数据进行风险评估。
-
-
反欺诈系统
-
利用分布式数据训练反欺诈模型。
-
(四)物联网
-
设备协同
-
在物联网设备上进行分布式训练,提升设备性能。
-
-
智能监控
-
利用分布式数据训练智能监控模型。
-
七、联邦学习的注意事项
(一)数据异构性
-
数据分布差异
-
不同客户端的数据分布可能不同,需要设计合适的算法来处理。
-
-
数据量差异
-
不同客户端的数据量可能不同,需要合理分配权重。
-
(二)通信效率
-
通信成本
-
通信是联邦学习的瓶颈,需要优化通信协议和模型压缩技术。
-
-
同步机制
-
客户端与服务器之间的同步机制需要高效且可靠。
-
(三)隐私保护
-
差分隐私
-
在模型更新中添加噪声,保护隐私。
-
-
同态加密
-
使用加密技术确保数据安全。
-
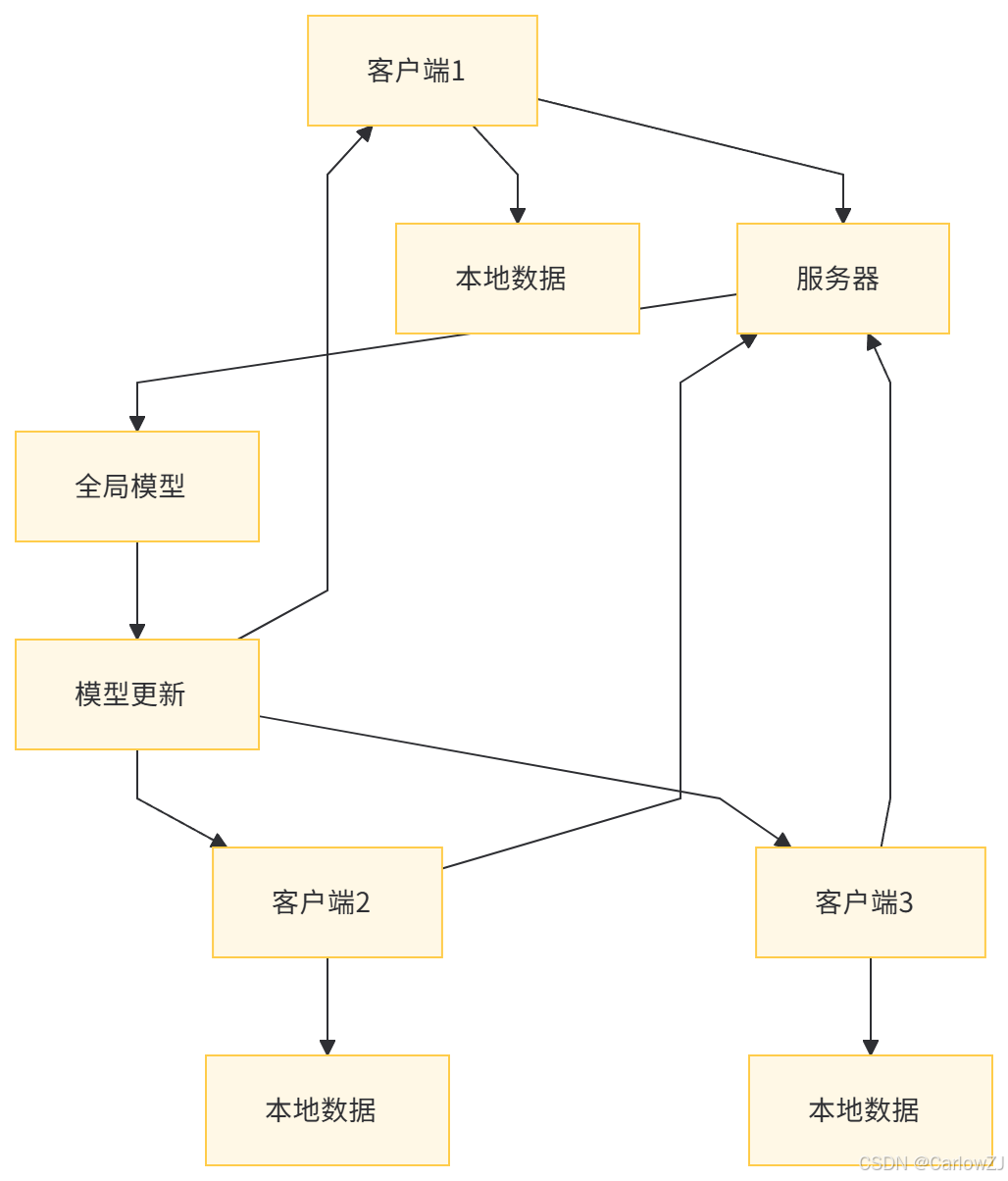
八、联邦学习的数据流图
九、总结
-
联邦学习的优势
-
联邦学习能够在保护隐私的同时,充分利用分布式数据资源,提升模型性能。
-
-
未来发展方向
-
随着人工智能技术的不断发展,联邦学习将在更多领域发挥重要作用,如跨领域联邦学习、联邦学习与区块链的结合等。
-



















 967
967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











