



摘要
在当今全球化的商业环境中,企业需要处理来自不同国家和地区用户的多样化需求。智能问答系统不仅需要高效处理海量数据,还需要支持多语言交互,以满足不同用户的语言需求。本文将探讨如何利用 Dify 和 RAGFlow 构建支持多语言的智能问答系统,并应对复杂业务场景。我们将详细介绍系统的架构设计、多语言支持的实现、复杂业务场景的处理策略,以及如何通过代码示例和实际应用场景来展示系统的强大功能。此外,我们还将分享在实际部署过程中需要注意的事项和优化建议。
概念讲解
Dify
Dify 是一个开源的 AI 应用开发框架,专注于快速构建和部署智能应用。它提供了丰富的功能模块和工具节点,支持多种 AI 模型的集成,能够处理复杂的业务逻辑。Dify 的核心优势在于其用户友好的界面和强大的工作流编排能力,使得开发者可以快速搭建和测试智能应用。
RAGFlow
RAGFlow 是一个专注于文档检索和生成的开源框架,适用于处理复杂的文档和非结构化数据。它通过检索(Retrieve)、增强(Augment)和生成(Generate)三个步骤,高效地从大规模文档中提取信息并生成回答。RAGFlow 的高可定制性使得用户可以根据具体需求调整检索管道和生成逻辑。
RAG(Retrieve, Augment, Generate)
RAG 是一种结合检索、增强和生成的框架,用于处理复杂的问答任务。其工作原理如下:
-
检索(Retrieve):从大规模文档中检索与问题相关的片段。
-
增强(Augment):将检索到的片段与问题结合,生成上下文信息。
-
生成(Generate):基于增强后的上下文生成准确的回答。
架构设计
系统架构图
以下是结合 Dify 和 RAGFlow 构建多语言智能问答系统的架构图:
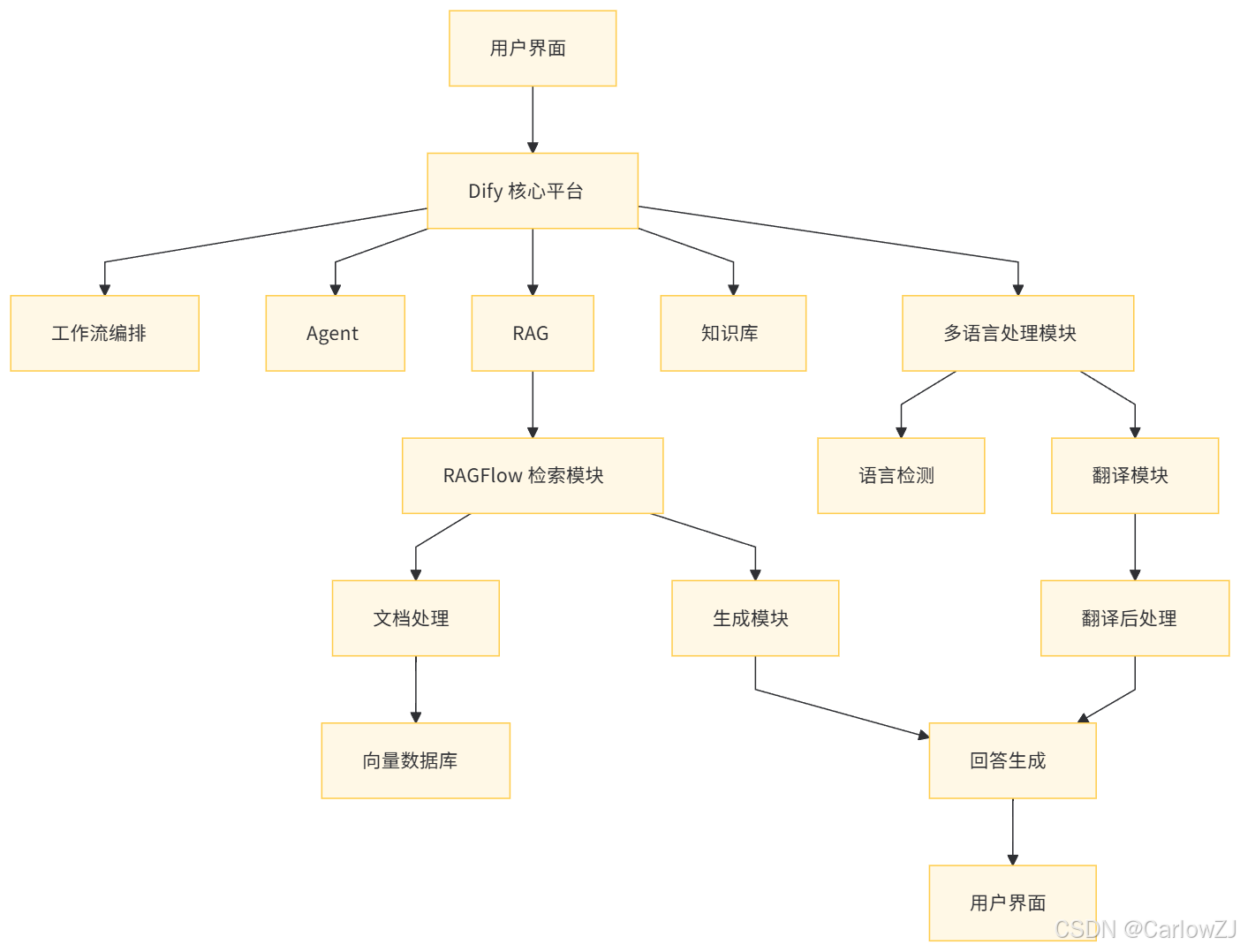
架构说明
-
用户界面:用户通过界面提交问题。
-
Dify 核心平台:负责接收用户请求,调用工作流和 Agent。
-
工作流编排:通过 Dify 的可视化界面编排任务流程。
-
Agent:处理用户的自然语言问题,调用 RAGFlow 模块。
-
RAGFlow 检索模块:从知识库中检索与问题相关的文档片段。
-
文档处理:对检索到的文档进行预处理,提取关键信息。
-
生成模块:结合检索结果生成回答。
-
向量数据库:存储文档的向量表示,用于高效检索。
-
回答生成:将生成的回答返回给用户界面。
-
多语言处理模块:支持多语言交互,包括语言检测和翻译功能。
-
语言检测:检测用户输入的语言。
-
翻译模块:将用户问题翻译为目标语言。
-
翻译后处理:对生成的回答进行翻译,返回给用户。
应用场景
场景一:企业国际化问答
对于跨国企业,需要一个支持多语言的智能问答系统,帮助全球员工快速获取公司政策、流程和技术文档等信息。通过 Dify + RAGFlow,可以实现以下功能:
-
多语言支持:支持多种语言的交互,包括中文、英文、日文等。
-
知识库检索:利用 RAGFlow 的深度检索能力,从企业文档中提取相关信息。
-
智能回答生成:结合 Dify 的 Agent 和 LLM 节点,生成准确、自然的回答。
-
多用户支持:Dify 支持多用户访问和权限管理,适合企业内部使用。
场景二:跨境电商客服
在跨境电商场景中,Dify + RAGFlow 可以快速响应不同国家客户的问题,提高客户满意度。具体实现如下:
-
多语言支持:支持多种语言的交互,包括英文、法文、德文等。
-
问题分类与理解:使用 Dify 的 Question Classifier 和 Question Understand 节点,对客户问题进行分类和意图理解。
-
检索与生成:调用 RAGFlow 检索相关文档,生成针对性的回答。
-
自动化流程:通过 Dify 的工作流编排,实现自动化的客户问题处理流程。
场景三:国际学术研究助手
对于国际学术研究人员,Dify + RAGFlow 可以帮助他们快速检索和理解大量文献。具体实现如下:
-
文献检索:利用 RAGFlow 检索与研究主题相关的文献。
-
文献摘要生成:结合 Dify 的生成模块,生成文献摘要。
-
研究问题回答:通过 Dify 的 Agent,回答研究人员的具体问题。
-
多语言支持:支持多种语言的交互,包括英文、中文、日文等。
代码示例
RAGFlow 配置示例
以下是 RAGFlow 知识库检索的代码示例:
# 初始化 RAGFlow 检索模块
from ragflow import RAGFlow
ragflow = RAGFlow(
model_name="your_model_name",
embedding_model="your_embedding_model",
vector_db="your_vector_db"
)
# 检索文档
query = "用户问题"
results = ragflow.retrieve(query)
# 生成回答
answer = ragflow.generate(results)
print(answer)Dify 工作流配置示例
在 Dify 中,可以通过以下方式配置工作流:
- name: "知识问答工作流"
steps:
- name: "问题理解"
type: "Question Understand"
config:
model: "your_model"
- name: "多语言处理"
type: "Multi-Language Processing"
config:
languages: ["en", "zh", "ja"]
- name: "知识库检索"
type: "Knowledge Retrieval"
config:
ragflow_api: "http://your_ragflow_api"
- name: "回答生成"
type: "Answer"
config:
template: "根据检索结果生成回答"数据流图
以下是系统数据流图,展示了数据在各个模块之间的流动:

多语言支持的实现
语言检测
语言检测是多语言问答系统的第一步。通过语言检测模块,系统可以自动识别用户输入的语言,并根据语言调用相应的翻译模块。
from langdetect import detect
def detect_language(query):
try:
language = detect(query)
return language
except:
return "en" # 默认语言为英文翻译模块
翻译模块负责将用户问题翻译为目标语言,并将生成的回答翻译回用户的语言。
from googletrans import Translator
translator = Translator()
def translate_text(text, target_language):
translation = translator.translate(text, dest=target_language)
return translation.text翻译后处理
翻译后处理模块负责对生成的回答进行翻译,确保回答的语言与用户输入的语言一致。
def post_process_translation(answer, user_language):
translated_answer = translate_text(answer, user_language)
return translated_answer复杂业务场景的处理策略
场景一:多模态问答
在某些业务场景中,用户可能需要通过图片、视频等多媒体内容提问。Dify + RAGFlow 可以通过以下方式支持多模态问答:
-
多媒体处理:对用户上传的多媒体内容进行预处理,提取关键信息。
-
多模态检索:结合多媒体内容和文本内容进行检索。
-
多模态生成:生成包含多媒体内容的回答。
场景二:动态知识库更新
在某些业务场景中,知识库的内容可能需要动态更新。Dify + RAGFlow 可以通过以下方式支持动态知识库更新:
-
实时数据同步:通过数据同步模块,实时更新知识库中的内容。
-
增量更新:对知识库进行增量更新,减少更新成本。
-
版本管理:对知识库进行版本管理,确保系统的稳定性和可靠性。
场景三:个性化问答
在某些业务场景中,用户可能需要个性化的问答服务。Dify + RAGFlow 可以通过以下方式支持个性化问答:
-
用户画像:通过用户画像模块,了解用户的兴趣和需求。
-
个性化检索:根据用户画像,进行个性化的检索。
-
个性化生成:根据用户画像,生成个性化的回答。
注意事项
数据安全
在企业环境中,确保数据的安全性和隐私性是至关重要的。需要对数据进行加密处理,并严格控制访问权限。
性能优化
对于大规模文档处理,需要优化 RAGFlow 的检索管道,以提高响应速度。同时,需要优化翻译模块的性能,减少翻译时间。
模型选择
根据具体需求选择合适的模型,平衡性能和成本。对于多语言支持,需要选择支持多语言的模型。
数据质量
确保知识库中的数据质量,定期更新和维护文档。对于多模态问答,需要确保多媒体内容的质量和准确性。
用户反馈
收集用户反馈,持续优化问答系统的性能和回答质量。对于多语言问答,需要收集不同语言用户的反馈,优化翻译模块的性能。
实际部署中的注意事项
环境准备
在部署之前,需要确保以下环境已经准备就绪:
-
服务器资源:根据系统规模选择合适的服务器配置。
-
网络环境:确保服务器的网络环境稳定,能够快速响应用户请求。
-
存储资源:为知识库和向量数据库准备足够的存储空间。
部署流程
-
安装依赖:安装 Dify 和 RAGFlow 的相关依赖库。
-
配置系统:根据实际需求配置 Dify 和 RAGFlow 的参数。
-
部署服务:将系统部署到服务器上,并启动相关服务。
-
测试系统:进行全面的测试,确保系统的稳定性和性能。
-
监控与维护:部署监控系统,实时监控系统的运行状态,并定期进行维护。
安全性考虑
-
数据加密:对存储在服务器上的数据进行加密处理,防止数据泄露。
-
访问控制:设置严格的访问控制策略,限制用户对系统的访问权限。
-
备份机制:定期备份系统数据,防止数据丢失。
持续改进与用户反馈
用户反馈机制
用户反馈是系统优化的重要依据。可以通过以下方式收集用户反馈:
-
用户评分:在用户界面中添加评分功能,让用户对回答的质量进行评分。
-
反馈表单:提供反馈表单,让用户可以详细描述他们的需求和建议。
-
数据分析:分析用户的行为数据,了解用户的需求和使用习惯。
持续改进策略
-
定期更新知识库:根据用户反馈和业务需求,定期更新知识库中的文档。
-
优化模型参数:根据用户反馈和系统性能数据,调整模型参数,提高回答质量。
-
改进系统功能:根据用户需求,不断改进系统的功能和用户体验。
总结
Dify 和 RAGFlow 的结合为企业级问答系统提供了强大的支持。通过优化系统架构、提升性能、确保数据安全以及收集用户反馈,可以构建一个高效、稳定且可扩展的智能问答系统。本文通过详细的代码示例、架构设计和实际部署案例,展示了如何实现这一目标。希望本文能够为您的项目提供有价值的参考。



















 8014
8014

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











