



摘要
机器学习是当今技术领域的热门话题,它在许多领域都取得了显著的成果。然而,对于初学者来说,构建一个完整的机器学习项目可能会感到有些困难。本文将从零开始,逐步介绍如何构建一个简单的机器学习项目,涵盖数据收集、预处理、模型训练、评估和部署的全过程。通过本文的介绍,读者将能够掌握机器学习项目的基本流程,并在实际应用中快速上手。文章中将使用Mermaid格式绘制流程图和数据流图,帮助读者更好地理解项目结构。
一、机器学习的基本概念
(一)什么是机器学习
机器学习是一种人工智能技术,它使计算机能够从数据中自动学习并改进。通过使用算法和统计模型,机器学习系统能够识别数据中的模式,并根据这些模式进行预测或决策。
(二)机器学习的类型
-
监督学习:通过标记的训练数据来学习输入和输出之间的映射关系。
-
无监督学习:在没有标记数据的情况下,自动发现数据中的结构和模式。
-
强化学习:通过与环境的交互来学习最优的行为策略。
(三)机器学习的应用场景
-
图像识别:自动识别图像中的物体、人脸等。
-
自然语言处理:语言翻译、情感分析等。
-
推荐系统:为用户推荐商品、电影等。
二、构建机器学习项目的准备工作
(一)技术选型
为了构建一个简单的机器学习项目,我们选择Python作为开发语言,因为它具有丰富的机器学习库和工具。我们将使用以下库:
-
NumPy:用于数值计算。
-
Pandas:用于数据处理和分析。
-
Scikit-learn:用于机器学习算法的实现。
-
Matplotlib:用于数据可视化。
(二)环境搭建
-
安装Python:从Python官网下载并安装最新版本的Python。
-
安装依赖库:在项目目录下运行以下命令,安装所需的库。
pip install numpy pandas scikit-learn matplotlib
三、机器学习项目的核心架构设计
(一)架构图
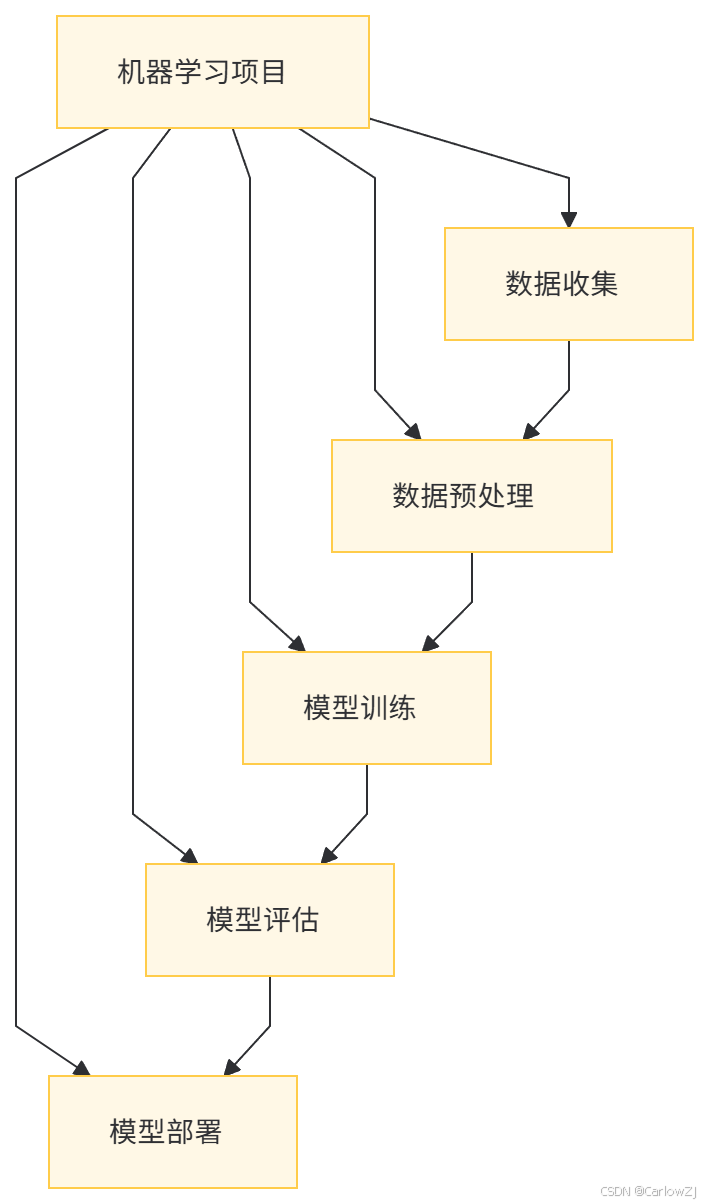
(二)架构说明
-
数据收集:获取用于训练和测试的数据。
-
数据预处理:清洗数据,处理缺失值,标准化等。
-
模型训练:选择合适的算法,训练模型。
-
模型评估:评估模型的性能,选择最优模型。
-
模型部署:将训练好的模型部署到生产环境中。
四、机器学习项目的代码实现
(一)数据收集
数据是机器学习项目的基础。我们可以从公开的数据集网站(如Kaggle)获取数据。以下是一个简单的代码示例,展示如何加载数据集。
import pandas as pd
# 加载数据集
data = pd.read_csv('data.csv')
print(data.head())(二)数据预处理
数据预处理是机器学习项目中非常重要的一步。我们需要对数据进行清洗、处理缺失值、标准化等操作。
# 处理缺失值
data = data.dropna()
# 数据标准化
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data[['feature1', 'feature2']] = scaler.fit_transform(data[['feature1', 'feature2']])(三)模型训练
选择合适的算法是机器学习项目的关键。我们将使用Scikit-learn库中的线性回归算法来训练模型。
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
# 划分训练集和测试集
X = data[['feature1', 'feature2']]
y = data['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
model = LinearRegression()
model.fit(X_train, y_train)(四)模型评估
评估模型的性能是机器学习项目中不可或缺的一步。我们将使用均方误差(MSE)来评估模型的性能。
from sklearn.metrics import mean_squared_error
# 预测测试集
y_pred = model.predict(X_test)
# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse}')(五)模型部署
将训练好的模型部署到生产环境中,可以使用Flask框架来实现一个简单的API。
from flask import Flask, request, jsonify
import joblib
app = Flask(__name__)
# 加载模型
model = joblib.load('model.pkl')
@app.route('/predict', methods=['POST'])
def predict():
data = request.json
prediction = model.predict([data['feature1'], data['feature2']])
return jsonify({'prediction': prediction.tolist()})
if __name__ == '__main__':
app.run(debug=True)五、机器学习项目的数据流图
六、机器学习项目的应用场景
(一)房价预测
我们可以使用机器学习模型来预测房价。以下是一个简单的代码示例,展示如何使用线性回归模型预测房价。
# 加载房价数据集
data = pd.read_csv('house_prices.csv')
# 数据预处理
data = data.dropna()
scaler = StandardScaler()
data[['area', 'rooms']] = scaler.fit_transform(data[['area', 'rooms']])
# 划分训练集和测试集
X = data[['area', 'rooms']]
y = data['price']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
model = LinearRegression()
model.fit(X_train, y_train)
# 预测测试集
y_pred = model.predict(X_test)
# 评估模型
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse}')(二)客户流失预测
我们可以使用机器学习模型来预测客户是否会流失。以下是一个简单的代码示例,展示如何使用逻辑回归模型进行客户流失预测。
# 加载客户数据集
data = pd.read_csv('customer_churn.csv')
# 数据预处理
data = data.dropna()
scaler = StandardScaler()
data[['age', 'spending']] = scaler.fit_transform(data[['age', 'spending']])
# 划分训练集和测试集
X = data[['age', 'spending']]
y = data['churn']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X_train, y_train)
# 预测测试集
y_pred = model.predict(X_test)
# 评估模型
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy}')七、使用机器学习项目时需要注意的事项
(一)数据质量
-
数据清洗:确保数据中没有错误或异常值。
-
数据平衡:避免数据集中的类别不平衡问题。
(二)模型选择
-
选择合适的算法:根据问题的性质选择合适的算法。
-
超参数调整:通过交叉验证等方法调整模型的超参数。
(三)模型评估
-
选择合适的评估指标:根据问题的性质选择合适的评估指标。
-
避免过拟合:通过正则化等方法避免模型过拟合。
八、总结
通过本文的介绍,我们从零开始构建了一个简单的机器学习项目。从数据收集、预处理、模型训练、评估到部署,我们详细介绍了机器学习项目的基本流程。通过这个过程,读者可以更好地理解机器学习项目的核心概念和实现方法。在未来的学习中,我们可以进一步扩展这个项目,尝试更多的算法和优化方法,以提高模型的性能。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











