



目录
随着人工智能技术的飞速发展,本地化部署和个性化定制的模型需求日益增长。DeepSeek 作为一个强大的本地模型,可以通过训练个人数据来打造专属的知识库。本文将详细介绍如何训练 DeepSeek 本地模型,帮助你快速上手并实现个性化应用。
1. 基本概念科普
在开始之前,我们需要了解一些基本概念。大语言模型(LLM)虽然功能强大,但其训练数据通常不包含个人私域数据。为了打造本地私域知识库,我们需要采用 RAG(Retrieval-Augmented Generation,检索增强生成)方法。具体来说,就是将私域数据向量化后存储到向量数据库中,结合 LLM 提供更专业的回复。
2. 下载 AnythingLLM 软件
AnythingLLM 是一个全栈应用程序,支持将文档、资源或内容转换为 LLM 的上下文。以下是下载和安装步骤:
-
下载地址:访问 AnythingLLM 官方网站,选择适合你系统平台的软件版本。
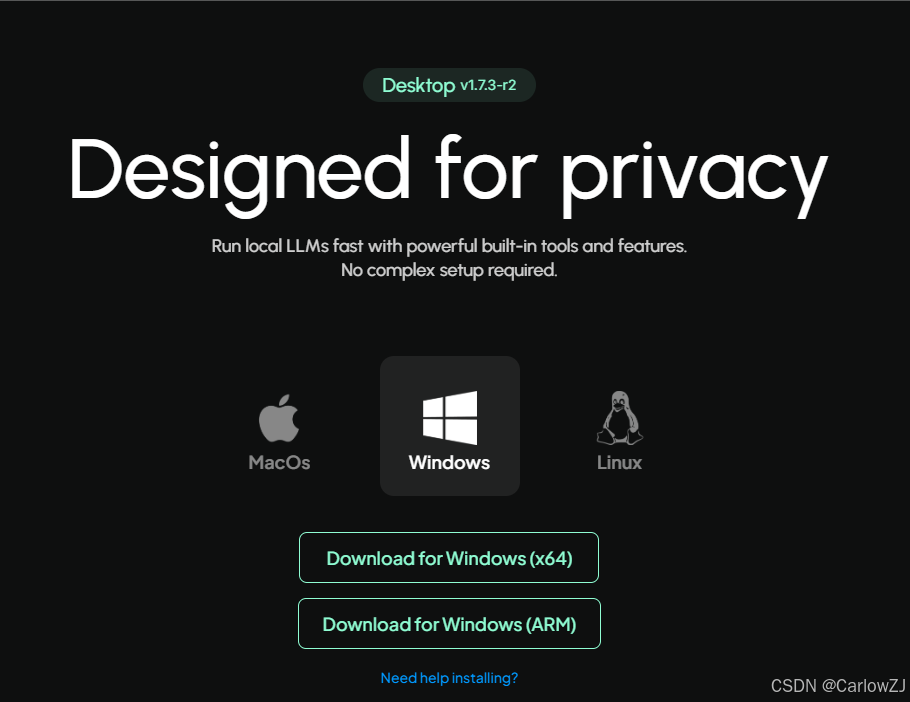
-
安装步骤:
-
下载完成后,双击安装文件并选择安装路径(默认为 C 盘,可更改)。
-
安装完成后,打开软件并点击“Get Started”进行初始化配置。
-
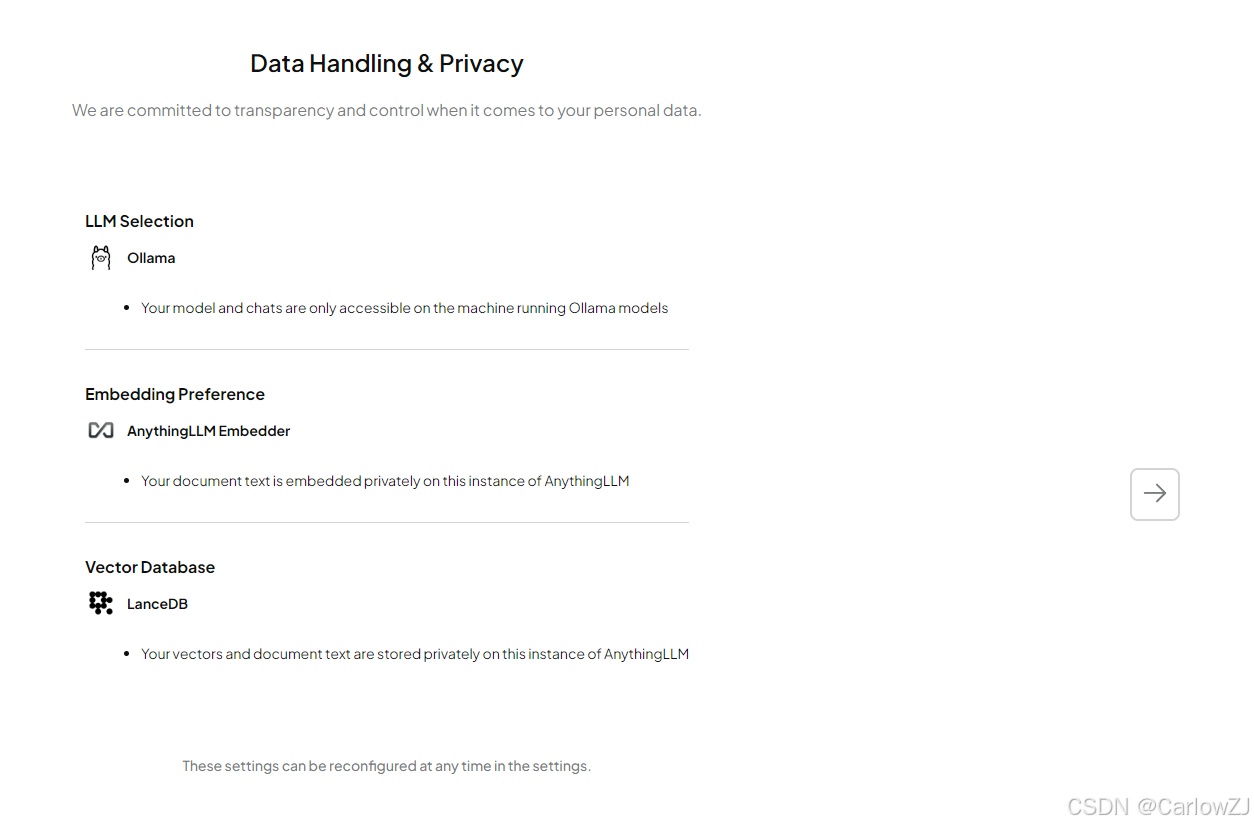
-
确保你的本地ollama已经启动
-
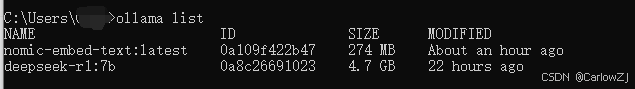

-
-
-
3. 配置 nomic-embed-text 模型
为了将个人数据向量化,我们需要配置嵌入模型 nomic-embed-text。以下是配置步骤:
-
下载嵌入模型:在终端或命令行中输入以下命令下载
nomic-embed-text模型:bash复制
ollama pull nomic-embed-text -
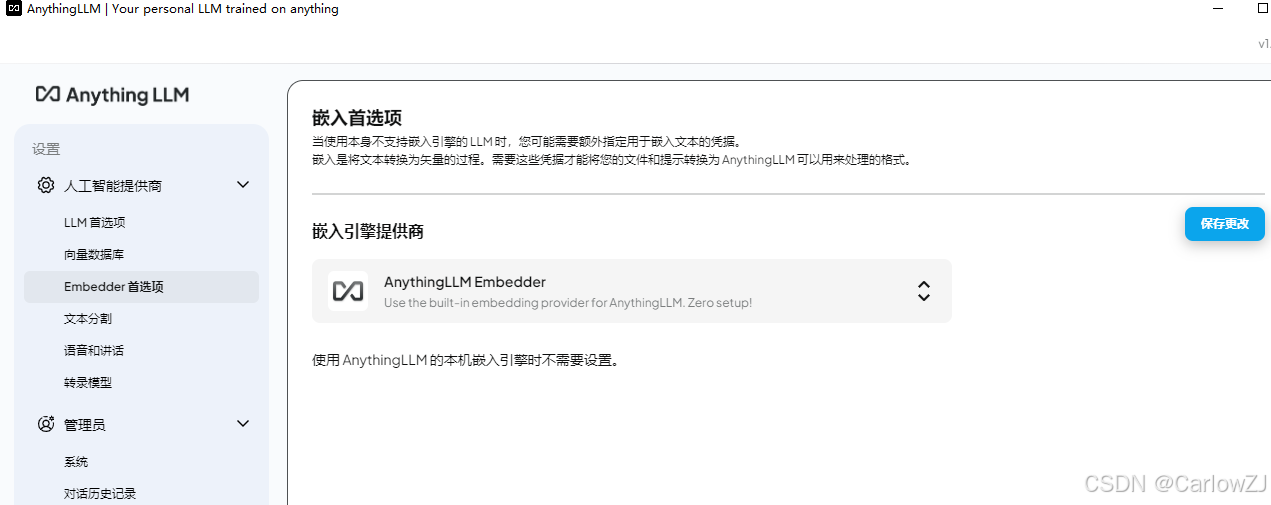
配置嵌入模型:
-
打开 AnythingLLM 软件,进入设置页面。
-
在“Embedding Preference”选项卡中,选择“Ollama”作为嵌入引擎提供商。
-
设置“Ollama Embedding Model”为
nomic-embed-text,并点击“保存更改”。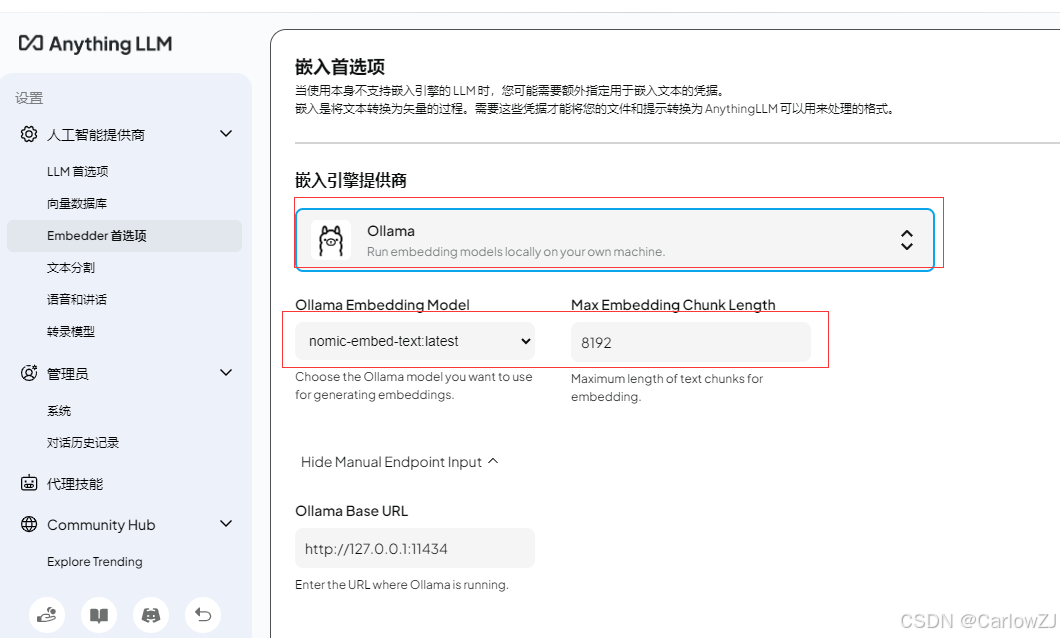
-
-
4. 演示如何正确训练个人数据
训练个人数据是打造私密知识库的关键步骤。以下是详细操作:
-
上传文档:
-
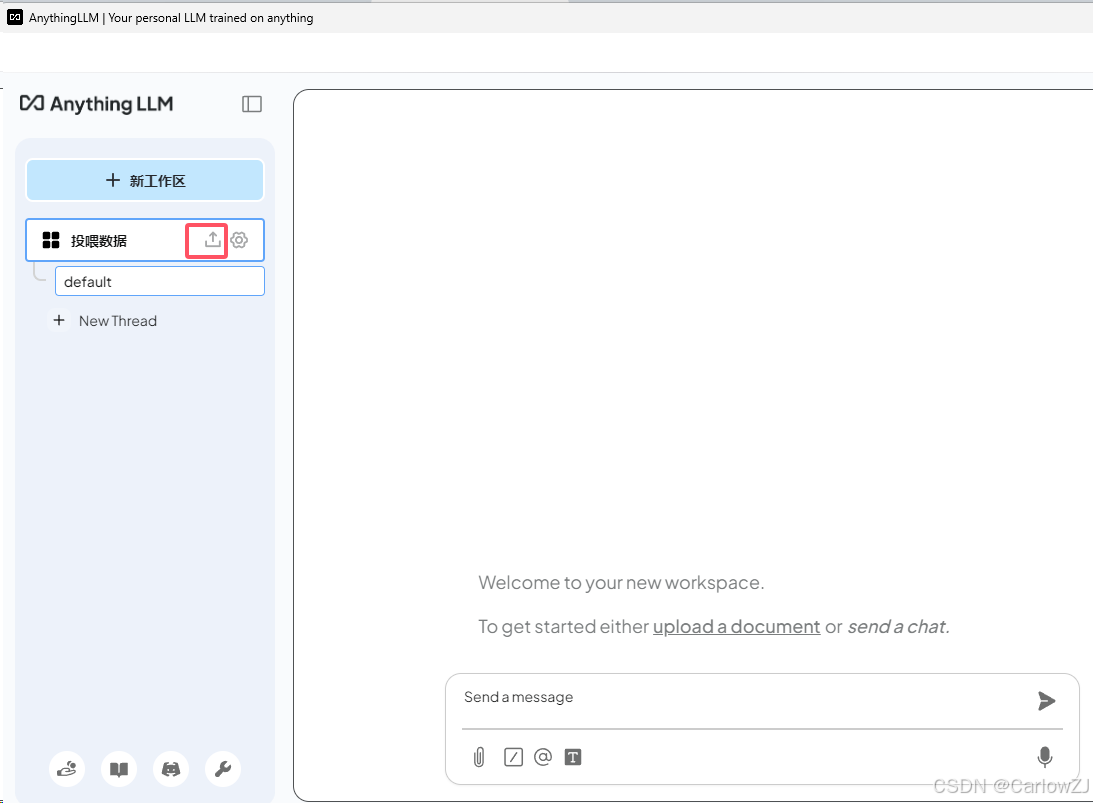
在 AnythingLLM 的工作区页面,点击“上传文档”按钮,选择需要训练的文档(支持 PDF、TXT、DOCX 等格式)。
-
在工作区界面,点击【上传】。
-
-
选择需要上传的文件。
-
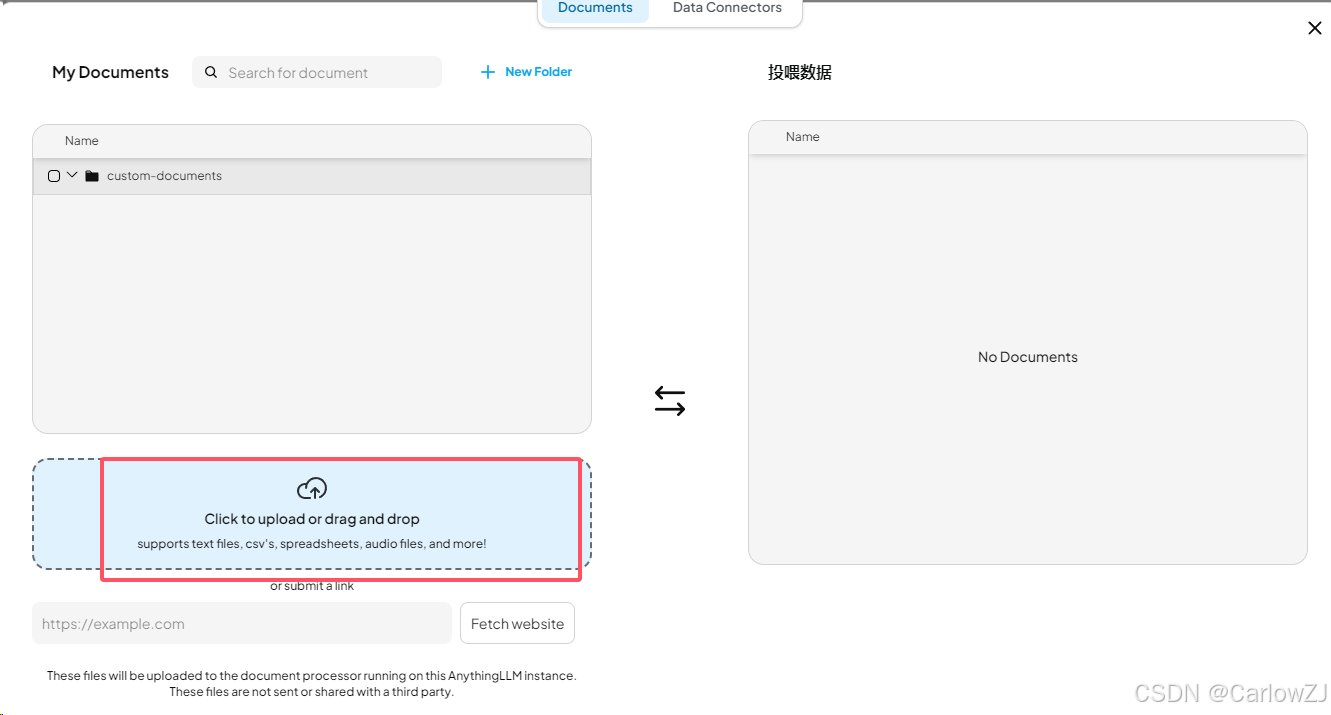
-
勾选上传的文件,点击【Move to Workspace】。
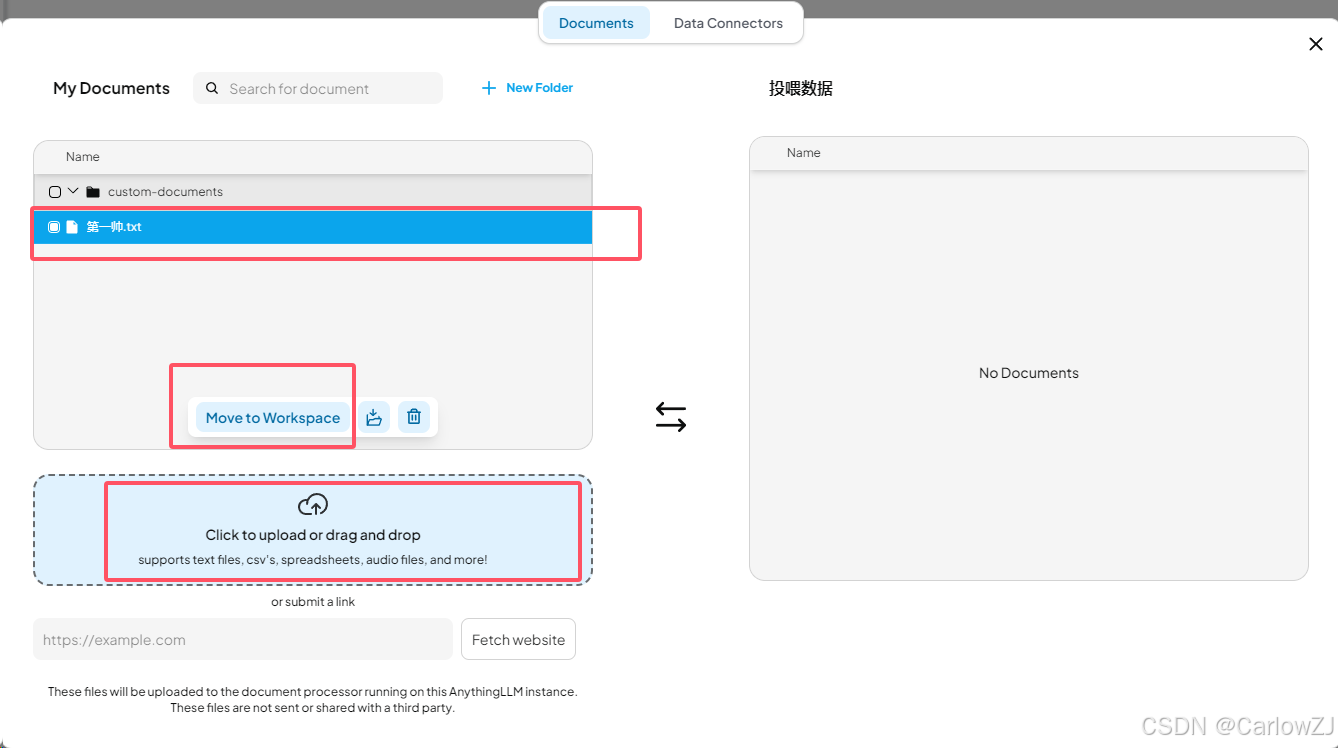
-
点击【Save and Embed】。
-
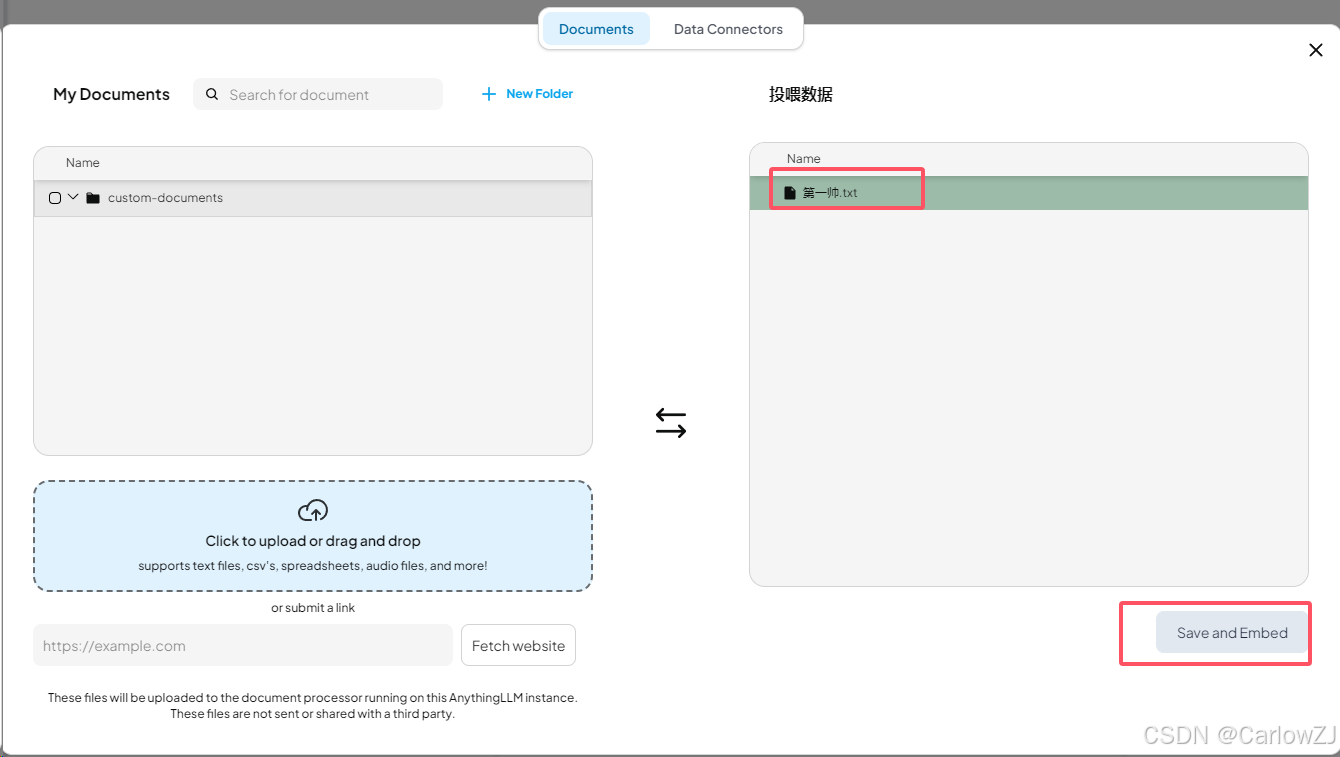
-
固定文件
-
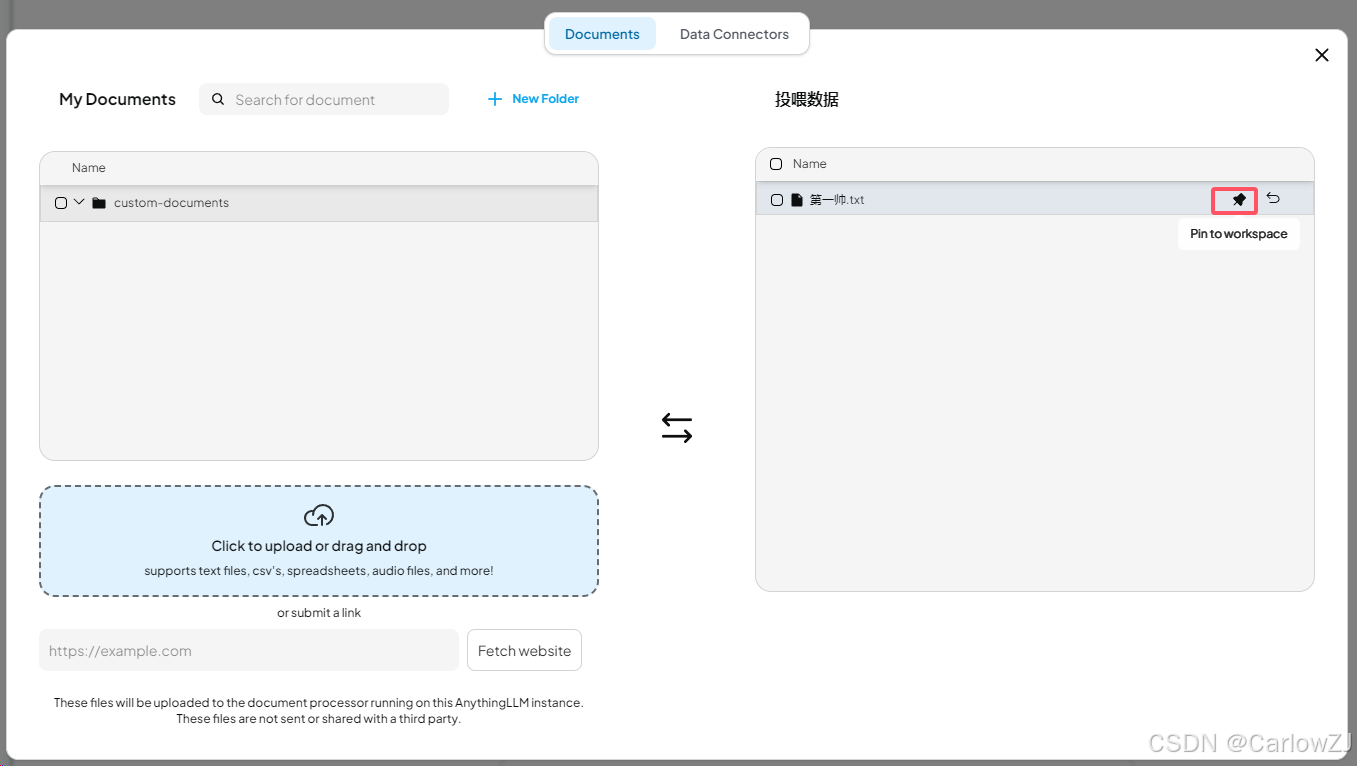
-
选中上传的文档后,点击“Save and Embed”按钮,等待模型完成向量转换。
-
-
配置工作区:
-
点击“工作区设置”,在“聊天设置”中选择“Ollama”作为 LLM 提供商,并设置工作区聊天模型为
deepseek-r1。 -
点击“Update workspace agent”完成配置。

-
5. 训练前后效果对比和缺陷
效果对比
在训练个人数据之前,模型可能无法回答与个人私域数据相关的问题。例如,当被问及“赵靖宇是谁?”时,未训练数据的模型可能无法给出准确回答。而训练数据后,模型能够结合私域知识库提供更精准的回答。
缺陷
尽管训练数据可以显著提升模型的个性化能力,但这种方法也存在一些局限性:
-
数据隐私:虽然本地部署可以保护数据隐私,但数据的向量化和存储仍需谨慎操作。
-
性能限制:向量数据库的性能和容量可能限制模型的检索效率。
-
模型更新:训练数据后,模型的更新和维护需要更多精力。
通过以上步骤,你已经成功训练了 DeepSeek 本地模型,并打造了自己的私密知识库。希望这篇文章能帮助你更好地理解和应用这一技术。如果你有任何疑问或建议,欢迎在评论区留言交流!



















 1469
1469

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











