




 本文介绍了Cascade-Correlation算法,该算法从直接的输入/输出连接开始,逐步构建隐藏层,通过最大化候选单元输出与残差误差的匹配来训练权重。相比反向传播,Cascade-Correlation更快,因为它每次只训练一层权重,并且可以在不预先确定网络大小和拓扑的情况下构建深度网络。此外,由于旧特征检测器被冻结,因此适合增量式‘课程’训练。
本文介绍了Cascade-Correlation算法,该算法从直接的输入/输出连接开始,逐步构建隐藏层,通过最大化候选单元输出与残差误差的匹配来训练权重。相比反向传播,Cascade-Correlation更快,因为它每次只训练一层权重,并且可以在不预先确定网络大小和拓扑的情况下构建深度网络。此外,由于旧特征检测器被冻结,因此适合增量式‘课程’训练。
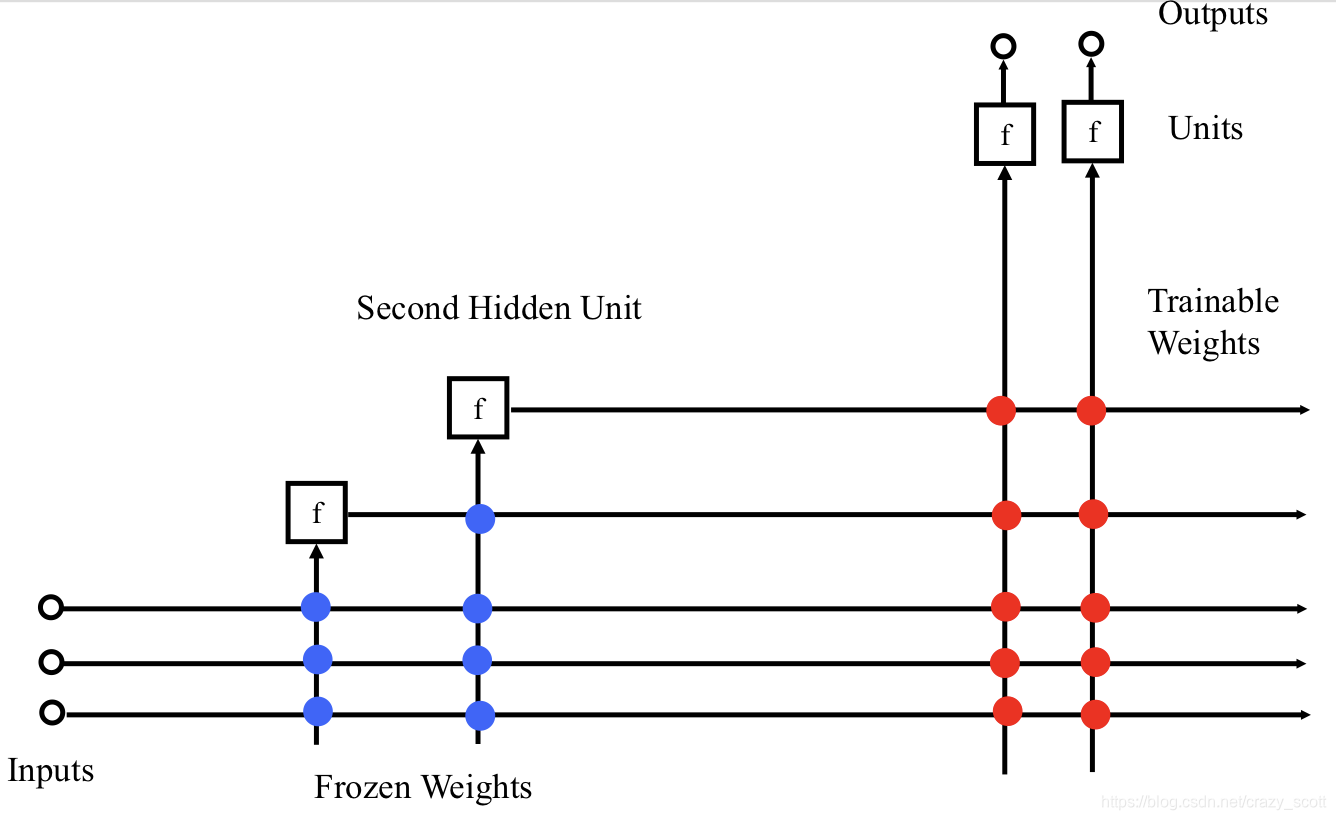
Cascade-Correlation Algorithm
- Start with direct I/O connections only. No hidden units.
- Train output-layer weights using BP or Quickprop.
- If error is now acceptable, quit.
- Else, Create one new hidden unit offline.
- Create a pool of candidate units. Each gets all available inputs. Outputs are not yet connected to anything.
- Train the incoming weights to maximize the match (covariance) between each unit’s output and the residual error:
- When all are quiescent, tenure the winner and add it to active net. Kill all the other candidates.
- Re-train output layer weights and repeat the cycle until done.
Why Is Backprop So Slow?
- Moving Targets
- All hidden units are being trained at once, changing the environment seen by the other units as they train.
- Herd Effect
- Each unit must find a distinct job – some component of the error to correct.
- All units scramble for the most important jobs. No central authority or communication.
- Once a job is taken, it disappears and units head for the next-best job, including the unit that took the best job.
- This is a very inefficient way to assign a distinct useful job to each unit.
Advantages of Cascade Correlation
- No need to guess size and topology of net in advance.
- Can build deep nets with higher-order features.
- Much faster than Backprop or Quickprop.
- Trains just one layer of weights at a time (fast).
- Works on smaller training sets (in some cases, at least).
- Old feature detectors are frozen, not cannibalized, so good for incremental “curriculum” training.
- Good for parallel implementation.

















 3998
3998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









