





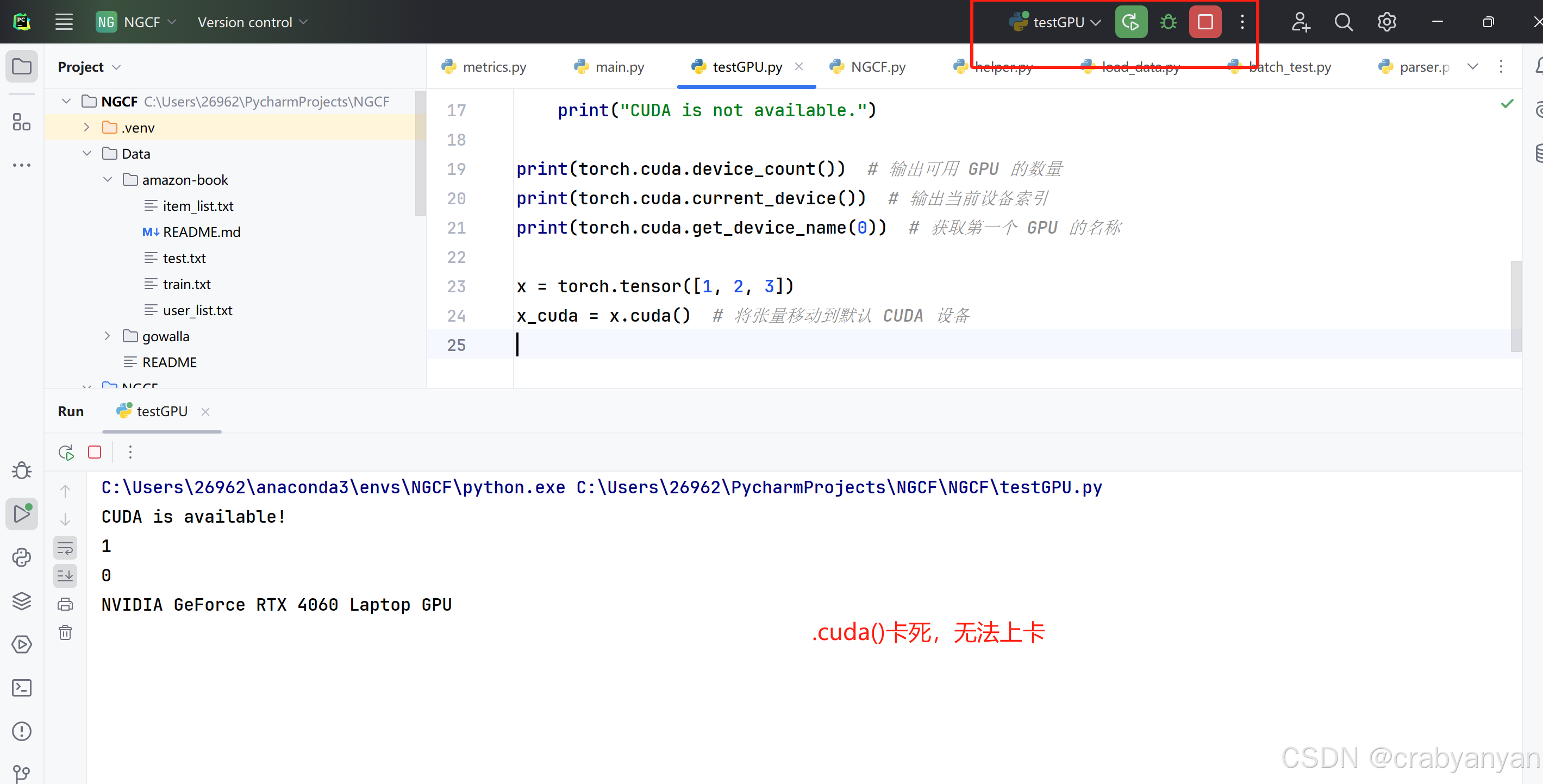
楼主因为要调一个五年前的深度学习的代码,但是发现代码无法运行,调试发现是model上GPU的时候卡死不动了,而且代码也不会报错
这是楼主的环境信息:
torch:1.3.1
CUDA :10.1
GPU: NVIDIA GeForce RTX 4060 Laptop GPU

楼主因为要调一个五年前的深度学习的代码,但是发现代码无法运行,调试发现是model上GPU的时候卡死不动了,而且代码也不会报错
这是楼主的环境信息:
torch:1.3.1
CUDA :10.1
GPU: NVIDIA GeForce RTX 4060 Laptop GPU
 7422
9991
2408
5513
8537
1772
7422
9991
2408
5513
8537
1772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























