









目录
前言
随着大语言模型(LLM)的普及和企业智能化需求的增长,基于“检索增强生成(RAG)”的知识问答系统成为应用热点。这类系统的核心优势在于可以结合大模型的语言理解能力与本地知识库的精确内容,实现准确、实时、可信的问答体验。
然而,很多开发者在构建过程中会忽视一个至关重要的环节——知识库的召回测试。召回环节决定了模型能否获取到正确的知识支撑,是影响最终问答质量的关键因素之一。本文将深入解析什么是知识库召回测试、为什么重要、如何评估,并结合实践提出优化建议,助力你构建高质量的智能问答系统。
1 什么是知识库召回测试?
1.1 概念解释
知识库召回测试,通俗地说,是一种用于评估系统在用户提问时,能否从知识库中正确找出相关文档片段的测试方法。它主要关注的是“检索”这个步骤的效果,而不是最终模型生成答案的能力。
在RAG流程中,一般包括以下四个关键步骤:
- 用户输入问题
- 将问题向量化处理
- 在知识库中通过向量匹配或关键词检索找到最相关的文档
- 将这些文档片段传入大模型生成回答
召回测试聚焦于第3步,旨在评估检索是否准确覆盖了问题所需的信息内容。
1.2 与模型生成的区别
值得注意的是,召回测试并不是测试模型回答是否准确,而是测试它看到的信息是否全面、正确。哪怕大模型很强,如果召回的文档没有包含正确答案,它也无从发挥。这也是为什么“检索效果”是决定RAG系统性能的基础。
2 为什么要进行召回测试?
召回测试的重要性主要体现在以下三个方面:
- 评估系统质量基线:只有确保检索部分能准确召回相关文档,才能进一步评估模型生成的表现。
- 发现知识库结构问题:召回测试可揭示分段策略、索引粒度、Embedding模型等配置的缺陷。
- 指导系统优化路径:通过测试数据反馈,可明确是否需要调整检索器、改写查询、增强预处理等。
在真实应用中,如果没有系统性地进行召回测试,用户体验往往表现为“模型看起来能说会道,但经常答非所问”,这在企业场景中尤为致命。
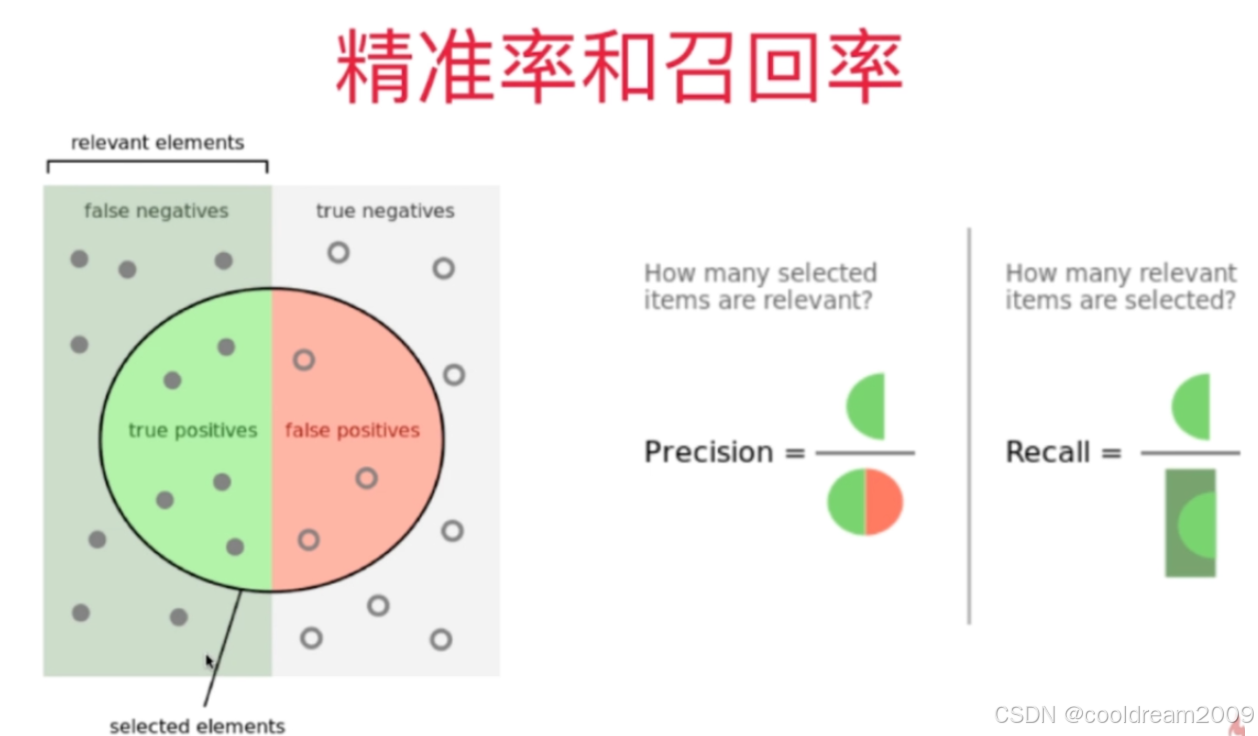
3 召回测试的核心指标与评估方法
3.1 常用指标说明
召回测试的效果评估通常采用以下几个指标:
| 指标 | 计算公式 | 含义说明 |
|---|---|---|
| Recall@k | 正确召回的文档数 ÷ 所有应召回的相关文档数 | 检索是否覆盖了应该给模型的文档 |
| Precision@k | 正确召回的文档数 ÷ 实际返回的 Top-k 文档数 | 检索返回结果的“纯度” |
| F1 Score | Precision 和 Recall 的调和平均数 | 兼顾召回率与准确率的综合评分 |
这些指标的评估通常在一组预先标注好的问答样本集上完成。
3.2 评估流程步骤
进行一次系统的召回测试,大致流程如下:
- 构建测试样本集:收集若干典型问题,并为每个问题标注标准答案来源片段或原始文档位置。
- 执行检索测试:使用当前系统对测试问题进行检索,记录返回的前k个文档片段。
- 比对召回效果:检查系统召回的内容中是否包含标注的正确文档,根据比对结果计算 Recall@k、Precision@k 等指标。
- 结果分析与反馈优化:根据结果判断当前知识库配置、向量模型、分段方式等是否存在改进空间。
4 示例解析:一次召回测试实战
假设我们在 Dify 平台上部署了一个知识库系统,主题为“华为云部署 Dify 平台指南”,知识库中包含以下文档内容:
文档片段:“部署完成后,请访问 http://xxx.xxx.xxx:5000,首次登录需设置管理员账号。”
现在我们的问题是:“华为云部署 Dify 平台后如何设置管理员?”
若系统在检索中返回了以下Top-3文档:
- 文档A:介绍 Dify 平台的功能组件
- 文档B:如何设置管理员账号(包含目标信息)
- 文档C:华为云一键部署模板说明
根据召回测试:
- 应召回的文档只有1个(文档B)
- 实际召回的Top-3中包含文档B
- 所以 Recall@3 = 1,Precision@3 = 1/3,F1 ≈ 0.5
这个测试提示:虽然命中了关键信息,但准确率偏低,可能存在噪音信息,应考虑优化向量模型或分段粒度。
5 常见问题与优化建议
5.1 常见召回不足的原因
知识库召回不准的原因通常包括以下几类:
- 分段策略不合理:内容被切得太碎或太长,导致信息语义不完整
- 向量化模型效果差:选用的Embedding模型无法正确理解语义
- 检索配置参数设置不当:如Top-k过小、相似度阈值过高
- 知识库内容冗余或结构混乱:影响召回的精准度
5.2 实践中的优化建议
为了提升知识库召回效果,可以尝试以下方法:
- 合理设置分段长度(通常推荐100~300字之间)
- 采用高性能中文Embedding模型(如 BGE、E5)
- 使用Hybrid检索(关键词+向量结合)增强准确率
- 定期对知识库进行去重、结构化整理
- 引入查询改写(Query Rewriting)优化用户输入表达
6 Dify 平台中的召回测试实践建议
在 Dify 等平台中,虽然没有内建的召回评估面板,但你可以通过以下方式手动或半自动完成:
6.1 使用调试模式查看召回内容
每次提问后,在“调试模式”中可以看到系统检索到的文档片段,包括其具体内容和匹配得分,可用于人工对比是否命中目标内容。
6.2 构建内部测试集评估
企业开发团队可自行维护一套问题-答案-参考文档三元组,在部署变更后定期回归测试,量化指标变化。
6.3 与 RAG 指标协同优化
将召回测试作为“模型生成评估”的前置环节,确保只有检索召回达标后,再测试生成效果。两者结合,才能全面评估系统质量。
结语
知识库召回测试,是构建高质量 RAG 应用中不可或缺的一环。它不像模型训练那样显眼,却在整个问答流程中起到“给大模型喂什么信息”的关键作用。
只有通过科学系统的召回测试,开发者才能有依据地优化知识库结构、调整检索策略,从而真正释放大模型的知识理解与生成能力。希望本文的讲解和实践建议,能为你在智能问答系统建设的道路上提供有力支持。


















 5909
5909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











