









目录
前言
在大模型快速发展的今天,Retrieval-Augmented Generation(RAG)成为许多企业构建智能问答系统、企业知识助手的重要技术路径。你可能会认为,RAG 系统的工作流程只是“用户提问 → 系统回答”那么简单,但实际远非如此。RAG 的整体效果不仅依赖于底层大语言模型的能力,还涉及检索组件的准确性、Prompt 模板设计的合理性、回答内容的可信性和系统响应能力等多个维度。
一套优秀的 RAG 系统,需要在“检索 → 生成 → 评估 → 优化”的闭环中持续迭代。而评估,正是这个闭环中的关键一环。
本文将带你系统梳理 RAG 的评估逻辑,介绍评估的核心维度、主流方法与工具,帮助你构建一套健壮、可信、高效的 RAG 系统。
1. 为什么需要评估 RAG 系统?
你可能会问:RAG 系统不就是问问题、返回答案,有必要评估吗?
其实不然。RAG 系统不像传统检索系统,也不等同于纯文本生成。它融合了“语义检索 + 大模型生成”的能力,系统输出结果受多种因素影响:
- 向量检索是否准确?
- Prompt 模板是否合理?
- 回答是否基于文档内容?
- 模型是否生成了“幻觉”?
- 系统响应是否及时、稳定?
因此,评估 RAG 系统的目标,不只是检验“回答对不对”,更要识别和优化系统中每一个关键环节。
2. RAG 系统评估的四个核心维度
我们可以从以下四个维度出发,对 RAG 系统进行全面评估:
| 评估维度 | 含义 | 常见问题 |
|---|---|---|
| 检索质量(Recall) | 系统是否能召回与问题高度相关的内容 | 无关段落被召回、漏检 |
| 生成质量(Answer Quality) | 回答是否准确、有逻辑、语言流畅 | 胡编乱造、答非所问、表达混乱 |
| 上下文控制(Grounding) | 回答是否真实依赖原始文档内容 | 幻觉、无依据句 |
| 系统响应能力 | 是否能快速、稳定地响应请求 | 延迟、失败、Token 溢出 |
这四大维度构成了 RAG 系统质量的核心评估体系,任何上线前的系统都应至少覆盖这些方面的测试。
3. 检索质量评估方法
检索的好坏直接决定了大模型看到的信息质量。没有高质量的上下文,模型即使再强也无用武之地。
3.1 Top-K 精确度评估
给定一组标准问题和理想文档段落,评估系统召回结果中是否包含这些“应召回段落”。这是最常见的评估方式之一,适合在系统训练和调优阶段使用。
例如,设定 K=3,如果标准答案在返回的 Top-3 段落中出现,则视为一次命中。
3.2 人工标注与自动评分结合
- 人工评估更准确,但成本高;
- 自动方法可以用向量相似度匹配、BM25 排名等,作为辅助指标;
- 可结合工具如 LangChain 的
RetrieverEvaluator实现批量评估。
3.3 工具推荐
- LangChain Evaluation 模块
- 自定义召回率分析脚本(支持 CSV、JSON 格式对比)
4. 生成质量评估方法
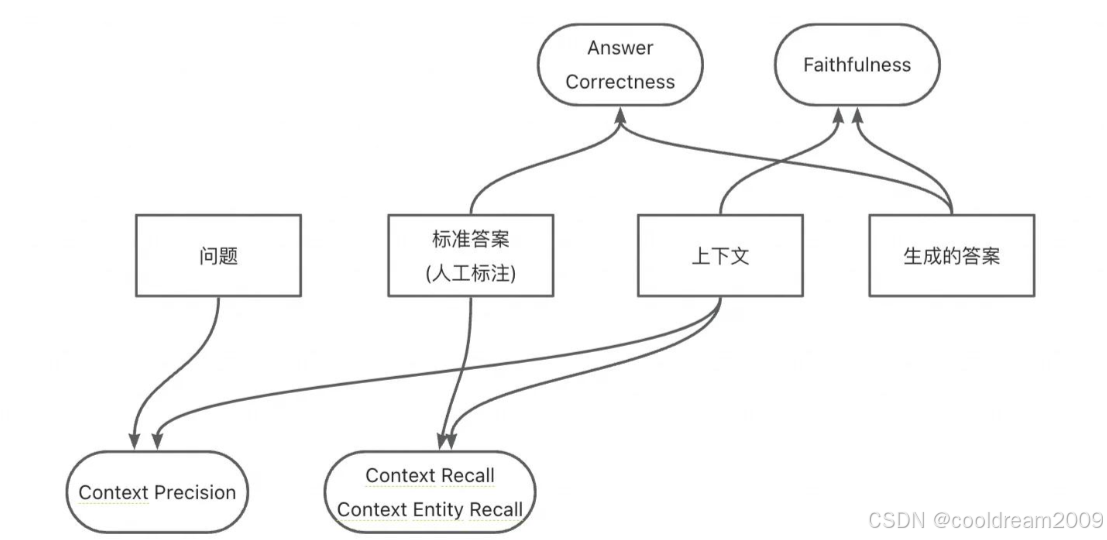
4.1 自动化指标评估
适用于结构化问答、简答题场景:
- BLEU:用于评估回答与参考答案的词语重合率;
- ROUGE:适合摘要任务,计算覆盖率和召回率;
- METEOR:对词序和语义有一定容忍度,综合性能较好。
4.2 模型自动打分(LLM-as-a-Judge)
使用 GPT-4、通义千问等模型作为“评委”,根据一套固定提示模板,让模型判断回答的准确性、完整性和语言表达质量。特别适合评估主观问答或开放性问题。
4.3 人工评分体系建议
以下是推荐的人工评分维度,可量化输出:
准确性(1~5分):是否回答了核心问题?
表达清晰度(1~5分):句子是否通顺自然?
引用覆盖度(1~5分):是否引用了相关上下文内容?
5. 如何识别和避免“幻觉”问题?
5.1 什么是幻觉?
幻觉是指:模型生成了在原始文档中不存在的信息,通常表现为:
- 编造事实(如虚构的人物、数据、功能);
- 自行补全不明确的语义;
- 滥用语气词,如“显然”、“众所周知”。
5.2 幻觉检测方法
- 要求引用段落编号或文档名称:提示模型在回答中显示出处;
- 人工/自动比对上下文与回答内容;
- 检测幻觉特征语句:比如使用“根据我们的研究”、“众所周知”等的句子,可以设置规则自动标记。
5.3 工具与技巧
- 使用“来源引用+回答分离”的 Prompt 结构;
- 多轮反馈比对上下文与回答之间的一致性;
- 结合语义检查工具(如 Haystack 的 QA Pipeline)对句子进行文档验证。
6. 如何优化 Prompt 模板以提升 Grounding?
Prompt 是连接“上下文 → 回答”的桥梁,一个不合理的 Prompt 可能导致模型不依据资料胡乱发挥。
6.1 Grounding 强化策略
- 明确告诉模型只能基于上下文回答;
- 强制要求列出引用段落编号;
- 引导模型在找不到答案时输出“未找到相关资料”;
6.2 推荐 Prompt 模板示例
请仅根据以下资料作答,不得使用常识或外部信息。
请在回答中列出引用段落编号。
如果未找到答案,请回答:“资料中未找到相关信息。”
6.3 回答结构优化技巧
- 建议使用 Markdown 输出(列表、编号、引用块);
- 指定结构:如“回答 + 来源”分段;
- 控制回答长度,防止冗长无用信息。
7. 系统响应能力与 Token 控制建议
RAG 系统在实际部署中,往往面临响应慢、成本高、Token 超限等问题。
7.1 性能优化建议
- 控制每次拼接的上下文段落数量(建议 3~5 条);
- 针对内容冗长文档,预先生成摘要嵌入;
- 高频问题使用缓存机制(预生成回答);
- 模型选型优先考虑性价比高的如 GPT-4-Turbo、Qwen-Turbo、Claude 3 Haiku。
7.2 Token 使用优化
- Prompt 使用精简表达;
- 删除冗余系统提示词;
- 使用短语替代长句描述。
8. 如何构建一套评估流程?
上线前必须建立完整的评估流程,确保系统输出的可靠性和稳定性。
8.1 关键准备内容
- 测试用例集:真实用户问题,50~200 条为宜;
- 标准答案与对应文档段落:用于比较与评分;
- 自动评估脚本:可选用 LangChain、Haystack 或自定义方案;
- 评估报告模板:包含以下关键指标:
| 指标名 | 含义 |
|---|---|
| 检索 Top-K 命中率 | 是否召回了相关段落 |
| 平均回答评分 | 人工或 LLM 打分均值 |
| 幻觉率 | 回答中包含虚假内容的比例 |
| 平均响应时长 | 系统平均处理耗时 |
结语
评估不是阻碍系统上线的障碍,而是保障系统质量的基石。一个高质量的 RAG 系统,不只是生成“看起来不错”的答案,而是要能稳定、准确、快速地服务真实场景。
从检索质量到生成效果,从幻觉控制到系统性能,每一环节都需要有明确的评估方法和优化手段。希望本文提供的框架与方法,能够为你的 RAG 项目提供实战价值,构建真正值得信赖的智能问答系统。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











