







内存消耗
内存使用统计命令: info memory
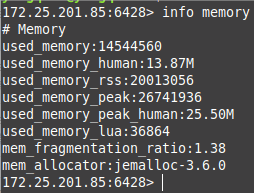
属性说明:
used_memory:Redis分配器分配的内存总量(单位是字节),也就是缓存数据内存占用量。used_memory_human只是显示更友好。used_memory_rss:从操作系统的角度显示Redis进程占用的物理内存总量,包括了没有被使用的内存。mem_fragmentation_ratio:内存碎片比率,该值是used_memory_rss / used_memory的比值。
ratio指数>1表明有内存碎片,说明used_memory_rss-used_memory多出的部分内存并没有用于数据存储,而是被内存碎片所消耗,如果两者相差很 大,说明碎片率严重。
ratio指数<1表明正在使用虚拟内存,虚拟内存其实就是硬盘,性能比内存低得多,这时应该增强机器的内存以提高性能。
一般来说,ratio的数值在1 ~ 1.5之间是比较健康的。used_memory_peak、used_memory_peak_human::用户cache数据的峰值大小。mem_allocator:在编译时指定的Redis使用的内存分配器,可以是libc、jemalloc、tcmalloc,默认是jemalloc。jemalloc在64位系统中,将内存空间划分为小、大、巨大三个范围;每个范围内又划分了许多小的内存块单位;存储数据的时候,会选择大小最合适的内存块进行存储。
产生内存碎片的原因:
Redis内部有自己的内存管理器,为了提高内存使用的效率,来对内存的申请和释放进行管理。
Redis中的值删除的时候,并没有把内存直接释放,交还给操作系统,而是交给了Redis内部的内存管理器。
Redis中申请内存的时候,也是先看自己的内存管理器中是否有足够的内存可用。
Redis的这种机制,提高了内存的使用率,但是会使Redis中有部分自己没在用,却不释放的内存,导致了内存碎片的发生。
碎片率的意义: mem_fragmentation_ratio的不同值,说明不同的情况。
- 大于1:说明内存有碎片,一般在1到1.5之间是正常的。
- 大于1.5:说明内存碎片率比较大,需要考虑是否要进行内存碎片清理,要引起重视。
- 小于1:说明已经开始使用交换内存,也就是使用硬盘了,正常的内存不够用了,需要考虑是否要进行内存的扩容。
解决内存碎片方案:
Redis版本是4.0以下的,Redis服务器重启后,Redis会将没用的内存归还给操作系统,碎片率会降下来。
Redis4.0版本开始,可以在不重启的情况下,线上整理内存碎片。
自动碎片清理,只要设置了如下的配置,内存就会自动清理了。
# 碎片整理总开关
# activedefrag yes
# 内存碎片达到多少的时候开启整理
active-defrag-ignore-bytes 100mb
# 碎片率达到百分之多少开启整理
active-defrag-threshold-lower 10
# 碎片率小余多少百分比开启整理
active-defrag-threshold-upper 100
手动碎片清理: memory purge
内存消耗图:

- 对象内存:是Redis内存占用最大的一块,存储着用户所有的数据。
- 缓冲内存:客户端缓冲、复制积压缓冲区、AOF缓冲区。
- 内存碎片:容易出现高内存碎片场景,频繁做更新操作,大量过期键删除,键对象过期删除后,释放的空间无法得到充分利 用,导致碎片率上升。重启节点可以做到内存碎片重新整理,因此可以利用高可 用架构,如Sentinel或Cluster,将碎片率过高的主节点转换为从节点,进行 安全重启。
设置内存上限:
使用maxmemory参数限制最大可用内存。
maxmemory限制的是Redis实际使用的内存量,也就是 used_memory 统计项对应的内存。
当超出内存上限maxmemory时使用LRU等删除策略释放空间。
Redis默认无限使用服务器内存,为防止极端情况下导致系统内存耗尽,建议所有的Redis进程都要配置maxmemory。
内存回收策略:
- 删除到达过期时间的键对象。
- 内存使用达到
maxmemory上限时触发内存溢出控制策略。
Redis 删除过期键的策略(缓存失效策略、数据过期策略)
惰性删除: 放任键过期不管,但是每次获取键时,都检査键是否过期,如果过期的话,就删除该键;如果没有过期,就返回该键。
定期删除: 每隔一段时间,默认100ms,程序就对数据库进行一次检査,删除里面的过期键。至于要删除多少过期键,以及要检査多少个数据库,则由算法决定。
Redis 的内存驱逐(淘汰)策略
当 Redis 的内存空间(maxmemory 参数配置)已经用满时,Redis 将根据配置的驱逐策略(maxmemory-policy 参数配置),进行相应的动作。
LRU: 最近最少使用。
LFU: 最不经常使用。
当前 Redis 的淘汰策略有以下8种:
noeviction:默认策略,不淘汰任何 key,直接返回错误。allkeys-lru:在所有的 key 中,使用 LRU 算法淘汰部分 key。allkeys-lfu:在所有的 key 中,使用 LFU 算法淘汰部分 key。allkeys-random:在所有的 key 中,随机淘汰部分 key。volatile-lru:在设置了过期时间的 key 中,使用 LRU 算法淘汰部分 key。volatile-lfu:在设置了过期时间的 key 中,使用 LFU 算法淘汰部分 key。volatile-random:在设置了过期时间的 key 中,随机淘汰部分 key。volatile-ttl:在设置了过期时间的 key 中,挑选 TTL(time to live,剩余时间)短的 key 淘汰。
缓存算法(FIFO 、LRU、LFU三种算法的区别)
https://www.cnblogs.com/hongdada/p/10406902.html
https://blog.youkuaiyun.com/a3192048/article/details/82291222
https://blog.youkuaiyun.com/wangxilong1991/article/details/70172302
FIFO算法
思想: 先进先出
LRU算法(最近最少使用)
思想: 算法根据数据的历史访问记录来进行淘汰数据,如果数据最近被访问过,那么将来被访问的几率也更高。
淘汰策略: 选择最久未使用的数据进行淘汰。
实现一: 使用一个链表保存缓存数据。
利用已有的 JDK 数据结构实现一个 Java 版的 LRU。
利用 LinkedHashMap 数据结构,链表结构的 HashMap,总是在头部插入元素。
LinkedHashMap 有一个这样的构造函数,accessOrder 参数表示访问元素的顺序模式,true表示会把访问的元素移到链表的头部,false则不会,默认为false。
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
返回 true 会把旧元素删除,可以自定义一个返回 true 的逻辑来删除尾部的元素。
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
利用上面的构造函数和方法就可以实现一个简单的LRU算法。
accessOrder 设置为 true,将访问的元素移到头部。
return super.size() > capacity,链表中的元素大于自定义的缓存个数时自动删除尾部的元素。
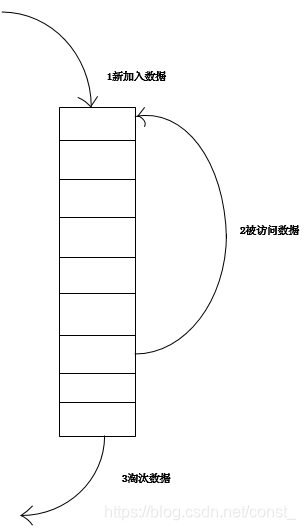
1、新数据插入到链表头部;
2、每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
3、当链表满的时候,将链表尾部的数据丢弃。
import java.util.LinkedHashMap;
import java.util.Map;
public class LRUCache<K, V> extends LinkedHashMap<K, V> {
// 缓存大小
private int capacity;
public LRUCache(int capacity) {
// Math.ceil 函数表示向上取整, 即小数部分直接舍去,并向正数部分进1,比如:Math.ceil(3.14) = 4
// true 表示让 linkedHashMap 将访问的元素移到到头部
super((int) Math.ceil(capacity / 0.75) + 1, 0.75f, true);
this.capacity = capacity;
}
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
// 当 map 中的数据量大于指定的缓存个数的时候,就自动删除最老的数据。
return super.size() > capacity;
}
public static void main(String[] args) {
System.out.println(i);
LRUCache<String, Integer> cache = new LRUCache<>(10);
for (int i = 0; i < 10; i++) {
cache.put("k" + i, i);
}
System.out.println("all cache : " + cache);
cache.get("k3");
System.out.println("get k3 after: " + cache);
cache.get("k4");
System.out.println("get k4 after: " + cache);
cache.get("k4");
System.out.println("get k4 after: " + cache);
cache.put("k10", 10);
System.out.println("put k10 after: " + cache);
}
}
输出结果:
all cache : {k0=0, k1=1, k2=2, k3=3, k4=4, k5=5, k6=6, k7=7, k8=8, k9=9}
get k3 after: {k0=0, k1=1, k2=2, k4=4, k5=5, k6=6, k7=7, k8=8, k9=9, k3=3} // 访问k3移到了头部
get k4 after: {k0=0, k1=1, k2=2, k5=5, k6=6, k7=7, k8=8, k9=9, k3=3, k4=4} // 访问k4移到了头部
get k4 after: {k0=0, k1=1, k2=2, k5=5, k6=6, k7=7, k8=8, k9=9, k3=3, k4=4} // 访问k4
put k10 after: {k1=1, k2=2, k5=5, k6=6, k7=7, k8=8, k9=9, k3=3, k4=4, k10=10} // 插入k10放在头部,尾部的k1被删除了
LFU算法(最不经常使用)
思想: 如果一个数据在最近一段时间内使用次数很少,那么在将来一段时间内被使用的可能性也很小。
淘汰策略: 选择一定时期内被访问次数最少的数据进行淘汰。
内存优化
Redis存储的所有值对象在内部定义为redisObject结构体。

















 736
736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









