







前言
Redis 的同学应该都知道,它基于键值对(key-value)的内存数据库,所有数据存放在内存中,内存在 Redis 中扮演一个核心角色,所有的操作都是围绕它进行。我们在实际维护过程中经常会被问到如下问题,比如数据怎么存储在Redis里面能节约成本、提升性能?Redis内存告警是什么原因导致?
Redis 内存管理
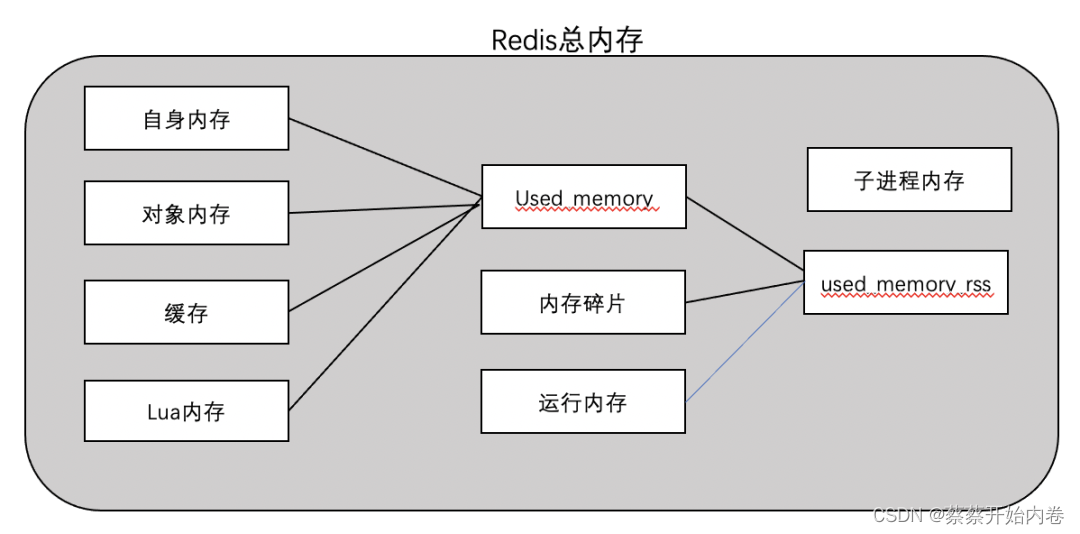
-
used_memory:Redis内存占用中最主要的部分,Redis 分配器分配的内存总量(单位是KB),主要包含自身内存(字典、元数据)、对象内存、缓存,lua 内存。 -
自身内存:自身维护的一些数据字典及元数据,一般占用内存很低。
-
对象内存:所有对象都是
Key-Value型,Key 对象都是字符串,Value 对象则包括5种类(String,List,Hash,Set,Zset),5.0 还支持stream类型。 -
缓存:客户端缓冲区(普通 + 主从复制 + pubsub)以及aof 缓冲区。 -
Lua 内存:主要是存储加载的 Lua 脚本,内存使用量和加载的 Lua 脚本数量有关。 -
used_memory_rss:Redis 主进程占据操作系统的内存(单位是 KB),是从操作系统角度得到的值,如 top、ps 等命令。 -
内存碎片:如果对数据的更改频繁,可能导致redis释放的空间在物理内存中并没有释放,但redis又无法有效利用,这就形成了内存碎片。 -
运行内存:运行时消耗的内存,一般占用内存较低,在 10M 内。 -
子进程内存:主要是在持久化的时候,aof rewrite或者rdb产生的子进程消耗的内存,一般也是比较小。
优化策略
缩减键值对象
key长度:如在设计键时,在完整描述业务情况下,键值越短越好。value长度:值对象缩减比较复杂,常见需求是把业务对象序列化成二进制数组放入Redis。首先应该在业务上精简业务对象,去掉不必要的属性避免存储无效数据。其次在序列化工具选择上,应该选择更高效的序列化工具来降低字节数组大小。
共享对象池
对象共享池指Redis内部维护[0-9999]的整数对象池。创建大量的整数类型redisObject存在内存开销,每个redisObject内部结构至少占16字节,甚至超过了整数自身空间消耗。所以Redis内存维护一个[0-9999]的整数对象池,用于节约内存。 除了整数值对象,其他类型如list,hash,set,zset内部元素也可以使用整数对象池。因此开发中在满足需求的前提下,尽量使用整数对象以节省内存。
可以通过object refcount 命令查看对象引用数验证是否启用整数对象池技术。
redis> set foo 100
OK
redis> object refcount foo
(integer) 1
redis> set bar 100
OK
redis> object refcount bar
(integer) 2
- 对象共享意味着多个引用共享同一个redisObject,这时lru字段也会被共享,导致无法获取每个对象的最后访问时间。如果没有设置maxmemory,直到内存被用尽Redis也不会触发内存回收。
- 对于ziplist编码的值对象,即使内部数据为整数也无法使用共享对象池,因为ziplist使用压缩且内存连续的结构,对象共享判断成本过高。
- 整数对象池复用的几率最大,其次对象共享的一个关键操作就是判断相等性,Redis之所以只有整数对象池,是因为整数比较算法时间复杂度为O(1),只保留一万个整数为了防止对象池浪费。如果是字符串判断相等性,时间复杂度变为O(n),特别是长字符串更消耗性能(浮点数在Redis内部使用字符串存储)。。
对象优化
字符串优化
字符串类型的 3 种编码:
int编码除了自身object无需分配内存,object的指针不需要指向其他内存空间,无论是从性能还是内存使用都是最优的。embstr是会分配一块连续的内存空间,但是假设这个value有任何变化,那么value对象会变成raw编码,而且是不可逆的。
Redis自身实现的字符串结构有如下特点:
- O(1)时间复杂度获取:字符串长度,已用长度,未用长度。
- 可用于保存字节数组,支持安全的二进制数据存储。
- 内部实现空间预分配机制,降低内存再分配次数。
- 惰性删除机制,字符串缩减后的空间不释放,作为预分配空间保留。
注意点:
因为字符串(SDS)存在预分配机制,日常开发中要小心预分配带来的内存浪费;
key 尽量控制在 44 个字节数内,走 embstr 编码,embstr 比 raw 编码减少一次内存分配,同时因为是连续内存存储,性能会更好;
多个 string 类型可以合并成小段 hash 类型去维护,小的 hash 类型走 ziplist 是有很好的压缩效果,节约内存。
ziplist
存储list时每个元素会作为一个 entry;存储 hash 时 key 和 value 会作为相邻的两个 entry;存储 zset 时 member 和 score 会作为相邻的两个entry,当不满足上述条件时,ziplist 会升级为 linkedlist,hashtable 或 skiplist 编码。
③在任何情况下大内存的编码都不会降级为 ziplist。
④linkedlist 、hashtable 便于进行增删改操作但是内存占用较大。
⑤ziplist 内存占用较少,但是因为每次修改都可能触发 realloc 和 memcopy,可能导致连锁更新(数据可能需要挪动)。因此修改操作的效率较低,在 ziplist 的条目很多时这个问题更加突出。

















 786
786

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









