







 超级会员免费看
超级会员免费看
在深度学习的发展史中,每一次架构层级的突破,都往往伴随着一种范式的转变。从卷积神经网络(CNN)引领计算机视觉,到循环神经网络(RNN)与LSTM带动自然语言处理的第一次腾飞,再到Transformer构建的语言模型帝国,每一次技术的跃迁都改变了“模型训练”和“模型应用”的基本关系。而如今,一个引发广泛思考的新架构理念正渐渐出现——Test-Time Training(简称TTT),正在重新定义模型训练的“时间维度”。
TTT 的本质在于:打破传统“训练-测试分离”的学习范式,在模型推理阶段动态更新权重,以适应特定任务或环境分布的偏移。这听起来或许像是“模型自我修正”,甚至“即时学习”的早期形态。它挑战了人们对“泛化能力”的传统定义,也触及了机器学习系统自主适应能力的核心议题。
这不仅仅是一次工程技巧的革新,而是一种方法论的重构。从固定权重的预训练-微调模式,转向“可塑”的推理机制,TTT 的出现提出了一个深远的问题:模型应不应该永远“固定”在推理阶段?模型是否应当在使用时继续学习?
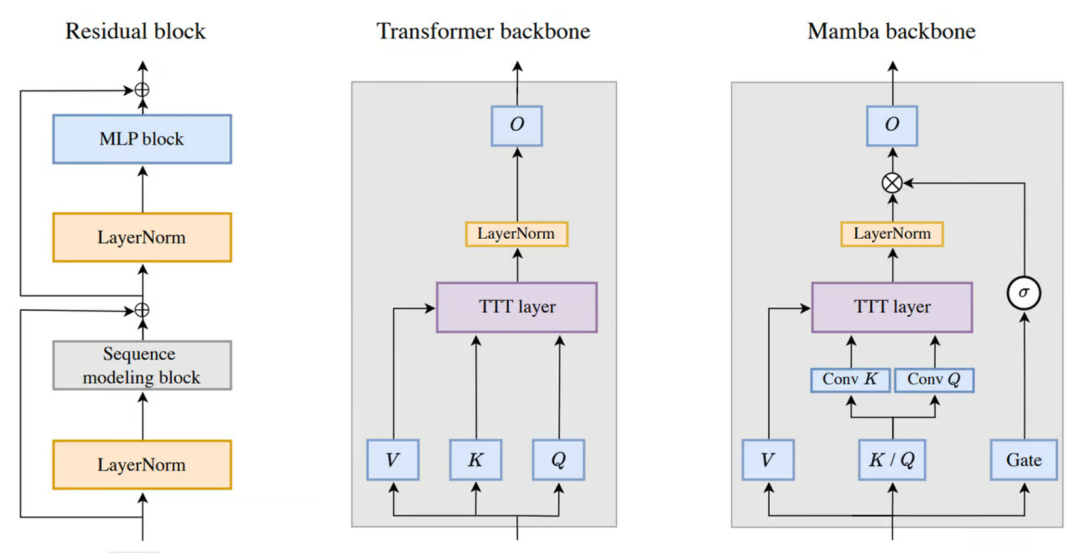
1. TTT 的起源:从训练/测试分离到动态推理
深度学习的主流范式自始至终都基于这样一个假设:模型在训练阶段学习通用模式,在测试阶段保持权重固定,通过“泛化能力”去应对未知数据分布。
这种做法虽然理论简洁、实现清晰,但在真实世界中经常受挫。因为训练数据和测试数据的分布通常并不一致,即所谓的“分

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1043
1043

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











