




 超级会员免费看
超级会员免费看
微信公众号、知乎号(同名):李歪理,欢迎大家关注
KV Cache 一般用在做推理的时候,只有在加入Causal Mask时才能使用。这是加入 Causal Mask 的 attention 计算公式:
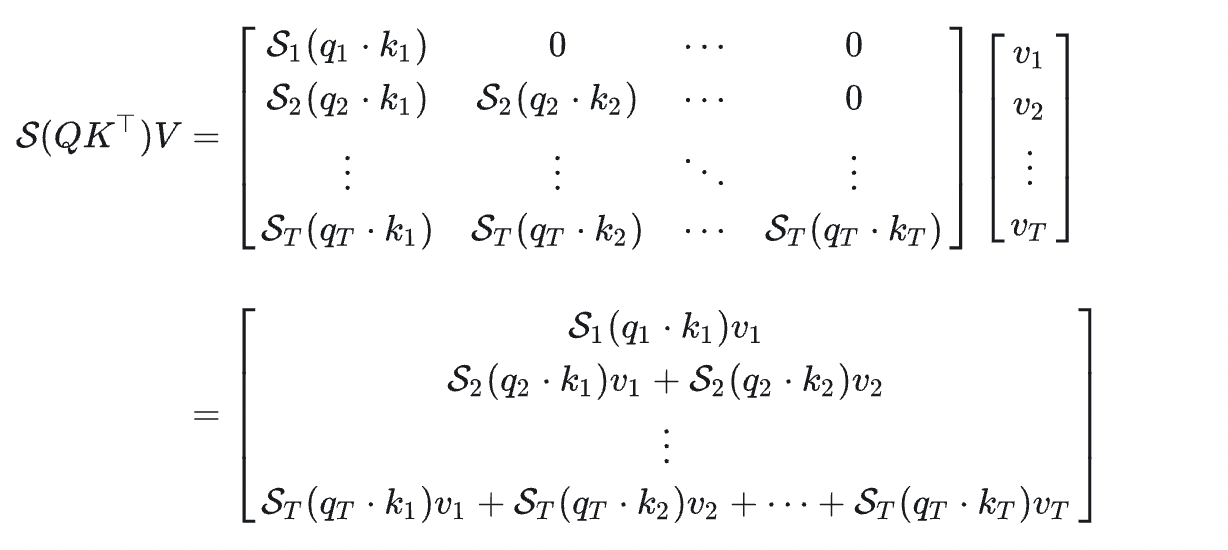
使用的时候是一个一个token输出的,如下面的式子所示:
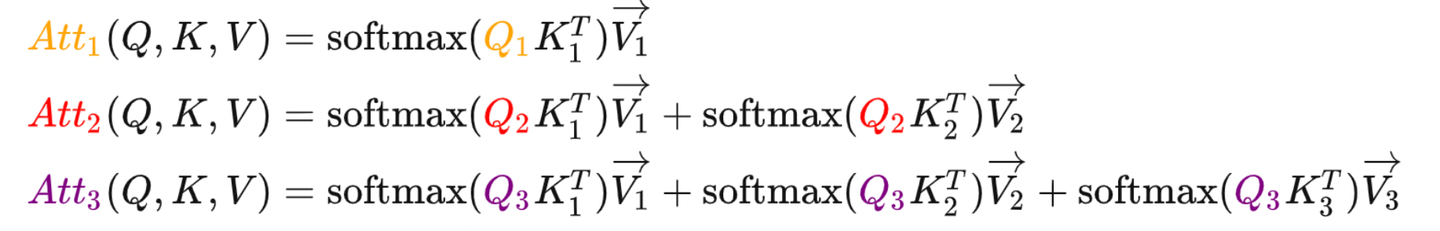
从式子上看答案很简单,因为在逐个 token 计算输出的时候当前轮的 QQQ 需要跟之前的 K,VK,V
微信公众号、知乎号(同名):李歪理,欢迎大家关注
KV Cache 一般用在做推理的时候,只有在加入Causal Mask时才能使用。这是加入 Causal Mask 的 attention 计算公式:
使用的时候是一个一个token输出的,如下面的式子所示:
从式子上看答案很简单,因为在逐个 token 计算输出的时候当前轮的 QQQ 需要跟之前的 K,VK,V
 1810
1810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


























