





微信公众号、知乎号(同名):李歪理,欢迎大家关注
(论文最近更新:2025.5.29)
FlexDuo是一种可插拔系统,用于为语音对话系统赋予全双工能力。全双工语音对话系统(Full-Duplex SDS)通过实现实时双向通信,显著提升了人机交互的自然性。然而,现有方法仍面临一系列挑战,例如:由于架构设计高度耦合、状态建模过于简单(仅采用二元状态模型),导致模块无法独立优化,以及上下文噪声干扰问题严重。
本文提出了一种名为 FlexDuo 的灵活全双工控制模块,它通过**“即插即用”(plug-and-play)架构设计**,将“全双工控制”功能从传统语音对话系统中解耦出来,具备良好的兼容性和模块化能力。
此外,受到人类在对话中信息过滤机制的启发,我们引入了一个显式的“空闲(Idle)状态”。一方面,该 Idle 状态可用于过滤冗余噪音和无关音频,从而提升对话质量;另一方面,它还建立了一个基于语义完整性的缓冲机制,在保障响应准确性的同时,有效降低了系统之间相互打断的风险。
在 Fisher 语料库上的实验结果表明,与传统的集成式全双工系统相比,FlexDuo 将误打断率降低了 23%,响应准确率提升了 8%。此外,与基于语音活动检测(VAD)的控制系统相比,FlexDuo 在中英文对话质量评估中也取得了更优的表现。
本文提出的模块化架构与基于状态的对话模型,为构建灵活高效的全双工对话系统提供了一条全新的技术路径。
1. 引言
语音对话系统是一种最直接的人机交互方式之一 。传统的基于轮流说话(turn-based)的对话系统,即使采用大语言模型(LLMs),通常也只支持半双工通信。虽然用户与助手之间可以双向交流,但无法同时进行。然而,在真实的人与人之间的交流中,打断(interruptions)、附和语(backchannels,如“嗯”“我知道了”)以及重叠语音(overlapping speech)都是常见现象。这意味着用户与助手之间的交流,理应可以同时说和听。随着人机对话对“模拟真实人类交流”的需求日益增长,**全双工语音对话系统(Full-Duplex SDS)**成为实现流畅、拟人化交流的关键技术方向。
近来,全双工语音对话系统的研究受到了广泛关注。目前已有的系统大多采用集成式架构设计,在全双工控制、对话生成、语音编码/解码模块之间存在高度耦合。这种设计通常需要对基础模型进行结构上的修改以及专门的后训练。然而,这种高度耦合的方式限制了系统的模块化能力,使得各组件难以被独立优化或替换,也不利于复用已有的高性能半双工对话系统。此外,当前大多数系统的建模重点仍主要集中在“说话”或“听”的状态上,忽略了对更多复杂对话状态的建模需求。
真实的对话场景中,常常会遇到一些无关的音频干扰,例如背景噪声或非目标人声等。这些非目标音频干扰不属于系统“说话”或“倾听”状态的范畴。然而,现有的研究工作尚未建立专门的状态模型来有效识别并过滤这些音频干扰,导致系统可能产生错误的响应,从而污染对话上下文。

我们提出了一个用于全双工对话控制与生成阶段的解耦框架,名为 FlexDuo。在对话控制阶段,除了传统的 “说话(Speak)” 和 “倾听(Listen)” 状态外,我们引入了一个额外的 “空闲(Idle)” 状态,用于指示当前的音频是否应该被忽略。在对话生成阶段,任何半双工的大语言模型(LLM)都可以用于处理经过筛选的上下文。例如,在图1上半部分所示的示例中,广播中传来的音频“今天的天气似乎好多了……”不需要系统响应。此时,控制模块能够识别并过滤这段音频,然后再将清理后的上下文传递给后续的半双工LLM,从而提升响应质量。
FlexDuo 将控制信号发送给半双工LLM,以决定当前对话状态并过滤音频信息。半双工LLM基于已过滤的音频生成响应,并将上下文信息返回给FlexDuo。随后,FlexDuo 会根据更新后的上下文和对话状态预测下一时刻的对话策略。通过精细设计的对话状态定义与转换机制,FlexDuo 能够有效支持多样化的对话场景。我们采用轮替准确率(turn-taking accuracy) 和错误打断率(false interruption rate)来评估全双工交互性能,使用 条件困惑度(conditional perplexity)来衡量对话质量。实验结果表明,我们的方法在全双工交互指标上优于现有的集成式全双工系统基线:将错误打断率降低了 23%,将轮替准确率提升了 8%。与使用语音活动检测(VAD)控制的系统相比,FlexDuo 在中文和英文的 Fisher 数据集上均有提升。
我们的贡献总结如下:
- 可插拔模块设计:一种灵活的模块化架构,可无缝集成至现有的半双工系统中,在最小化开发与升级成本的同时,提供强大的全双工对话能力。
- 引入 Idle 状态:首次提出 Idle(空闲)机制,模拟人类在对话中对无效信息的过滤行为,在嘈杂环境下增强上下文清晰度,提升回复的一致性与准确性。
2. 相关工作
全双工语音对话系统:在基于大语言模型(LLM)的全双工语音对话系统中,现有方法主要采用集成式系统架构,通过修改模型结构来增强双工能力。具体而言,TurnGPT 在编码器-解码器框架中引入语音特征预测,用于检测对话的转换点;MThread 通过添加特殊状态 token(如 Speak、Listen)控制外部的 ASR(自动语音识别)和 TTS(语音合成)模块;VITA 使用双模型协同架构,通过监听器-生成器交替机制实现中断;Freeze-Omni 和 MinMo 在隐藏状态上附加分类器来预测系统状态;Moshi 通过并行处理用户语音输入和助手文本/语音输出流,将双工控制与语音生成模块紧密耦合。尽管这些方法提升了全双工交互能力,但其核心问题是将双工功能紧密集成进整个系统架构中,导致必须依赖端到端的级联操作。这种一体化架构存在显著限制:一旦要进行功能升级,就必须对整个系统重新训练。与此不同,我们提出了一种可插拔的全双工模块,该模块与对话系统解耦,并以非侵入式方式运行,仅基于对话上下文和状态做出双工决策。这种设计不仅支持模块的独立升级,还具备对各种半双工对话系统的良好兼容性。
半双工系统(Half-Duplex Systems):半双工系统通过大语言模型(LLM)实现轮流式对话,代表方法包括 SpeechGPT 和 LauraGPT。这类系统在响应之前必须等待用户完整说完一句话(依赖静音检测或显式的终止信号),从而导致互动延迟显著高于人类之间的自然对话。我们的方法是将一个半双工对话系统与对话状态检测器结合使用,以解耦的方式实现全双工对话系统。
有效输入检测(Valid Input Detection):在双工系统中,检测有效输入对于判断系统何时应当响应或中断当前动作至关重要。当前的全双工语音对话系统(Full Duplex SDS)中,有效音频输入的检测方法主要分为VAD和基于模型的方法。VAD(语音活动检测)方法可识别人类语音,但难以应对如附和语(backchannels) 等复杂场景,且通常需要依赖固定长度的静音段来确认说话是否结束。在基于模型的方法中,Freeze-Omni 和 MinMo 在生成回复过程中预测控制 token,以标记有效输入,但仍然依赖 VAD 进行语音检测,LSLM 融合了“说话”和“听”的通道信息,用于输入验证。我们的工作专注于人类语音的有效性检测,旨在减轻附和语、多人交谈等场景下的干扰影响,从而提升系统在真实对话环境下的稳健性。
对话状态转换:现有系统通常通过定义二元状态(即“说话(Speak)”和“倾听(Listen)”)来建模轮流对话。在“说话”状态中,系统输出回应,并同时监听音频以决定是否需要转换状态;而在“倾听”状态中,所有环境音频都会被送入大语言模型进行处理,即使这些音频与当前对话无关。例如,MThread 和 VITA 使用显式控制 token 结合 VAD(语音活动检测)来预测状态转换;Freeze-Omni 和 MinMo 则在语言模型的隐藏状态中添加分类器进行状态预测;而 SyncLLM、LSLM 和 Moshi 则采用多通道结构,并行处理用户和助手的输入。这些方法虽然提升了并行处理能力,但普遍缺乏对非对话场景的主动过滤机制,系统仍被迫处理所有音频输入,不仅浪费计算资源,还会引入语义干扰。受人类在对话中能够自动“屏蔽无关声音”这一能力的启发,我们提出了一种新的对话状态——“空闲(Idle)”状态,用于过滤那些非必要的音频输入,从而提升系统的处理效率和对话质量。
3. 方法
在本节中,我们将介绍 FlexDuo 的模型架构,并解释其各个模块是如何协同工作的。接下来,我们将详细说明 FlexDuo 训练过程中的数据构建与训练策略。
3.1 模型结构
FlexDuo 是一个支持全双工语音对话的控制模块,采用了可插拔的架构设计。它通过实时接收用户音频流,并输出控制信号和过滤后的语音数据,从而控制任意半双工语音对话系统,实现对话状态的维持或切换,并保持上下文的整洁。这使系统能够实现类似人类交互的自然流畅对话,以及高质量的对话内容。FlexDuo 主要分为三个部分:上下文管理器(context manager)、状态管理器(state manager) 和 滑动窗口(sliding window)。其工作流程如图 2 所示,可分为以下六个步骤:(1)FlexDuo 接收用户的音频流数据,并将其切分为音频块传递给上下文管理器;(2)状态管理器为了预测当前时刻的对话动作,从上下文管理器中获取上下文信息;(3)状态管理器利用历史上下文以及当前音频滑动窗口来预测对话动作;(4)状态管理器将过滤后的音频和控制信号发送给半双工语言模型,以控制其行为;(5)半双工语言模型基于过滤后的音频流和控制信号为用户生成响应;(6)在生成用户响应的同时,半双工语言模型还会将一份副本发送回上下文管理器,以便为下一步对话动作的预测做好准备。
状态管理器(State Manager):状态控制器通过分析由上下文管理器提供的对话上下文和滑动窗口内的音频片段,来预测下一步的对话动作。它以固定时间间隔(120 毫秒)评估历史上下文和滑动窗口中的数据,从而决定下一步动作。在有限状态机(FSM)的基础上,状态管理器预测的动作将是以下七种对话状态中的一种,以实现状态的维持或转移:(1)K.S(保持说话):助手维持当前的说话状态;(2)K.L(保持倾听):用户尚未说完,系统继续监听;(3)K.I(保持空闲):当前为环境噪声、用户的附和语(如“嗯”)或其他第三方的语音,不需响应;(4)S2L(从说话转为倾听):用户打断了助手;(5)S2I(从说话转为空闲):助手自然说完并结束发言;(6)L2S(从倾听转为说话):助手开始回应用户或主动打断;(7)I2L(从空闲转为倾听):用户开始说话。为了让 FlexDuo 更好地利用这一有限状态机机制,我们结合系统当前的对话状态,来预测下一时刻的对话动作。我们的全双工控制模块会基于历史对话的上下文、当前状态,以及滑动窗口中累计的语音片段,来预测当前的对话策略。
πt=F(C,St−1,Wt:θ)\begin{equation} \pi_t=F(C,S_{t-1},W_t:\theta) \end{equation}πt=F(C,St−1,Wt:θ)
在等式(1)中 πt\pi_tπt 表示 ttt 时刻的对话策略,StS_tSt 表示 ttt 时刻的对话状态,CCC 表示对话历史上下文,WtW_tWt 表示 ttt 时刻滑动窗口中累积的语音块,F(:θ)F(:\theta)F(:θ) 代表在给定权重 θ\thetaθ 下全双工控制模块的前向计算过程。
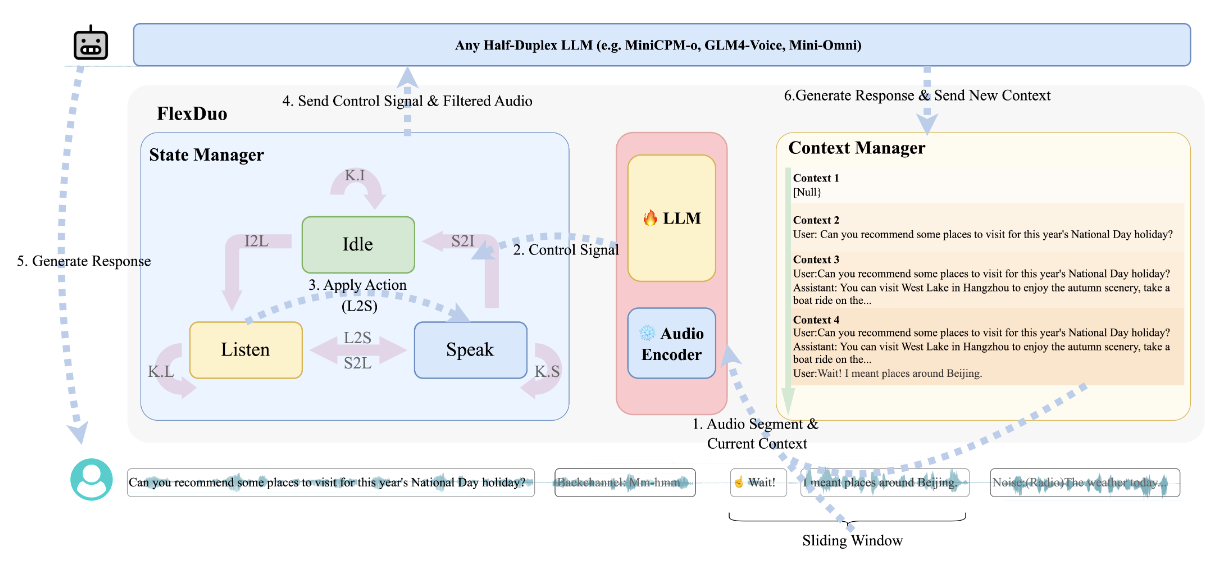
在预测出当前的对话动作后,状态管理器会将控制信号发送给半双工大语言模型(LLM)。当状态为 “Speak”(说话)时,意味着半双工 LLM 可以开始生成对用户的回复;当状态变为 “Idle”(空闲)或 “Listen”(聆听)时,半双工 LLM 的输出将会被中断。具体来说,在 “Idle” 状态下,状态管理器会对用户端接收到的音频进行过滤,以帮助语音对话系统剔除冗余内容,从而保持对话的整洁和高质量。例如,在图 2 下方的用户流程示意图中间位置,由于对话状态为 “Idle”,用户发出的回声性语气词(backchannels)被成功过滤掉了。而在 “Listen” 状态下,状态管理器会将用户音频传递给半双工 LLM,用于预填充(prefilling)上下文信息。
上下文管理器(Context Manager):FlexDuo 定义了三种对话状态:Speak(说话)、Idle(空闲) 和 Listen(聆听)。状态的转换过程与触发条件如图 2 所示。在 Speak 状态下,FlexDuo 驱动语音系统输出对话音频。当状态从 Listen 转换为其他状态时,表示用户的发言已结束,FlexDuo 会将该段对话保存至对话上下文中,并将上下文从 Context 1 更新为 Context 2。当状态从 Speak 转换为其他状态时,表示助手的发言已结束,FlexDuo 会将上下文从 Context 2 更新为 Context 3。
滑动窗口(Sliding Window):FlexDuo 实时监测当前环境中的音频输入,并将音频片段送入滑动窗口中。滑动窗口的工作机制会根据系统所处的状态而发生变化:当系统处于 Listen(聆听) 状态时,表示系统正在接收有意义的人类语音输入,此时滑动窗口开始累计语音块。当系统处于 Speak(说话) 或 Idle(空闲) 状态时,说明环境中存在冗余噪声或无效信息,此时滑动窗口采用固定长度的方式进行预测,以降低计算开销。
滑动窗口的累计方式如下所示:
Wt={[Wt−1,at],if St−1=Listen[at−w+1,…,at−1,at],others\begin{equation} W_t = \begin{cases} [W_{t-1}, a_t], & \text{if } S_{t-1} = \text{Listen} \\ [a_{t-w+1}, \ldots, a_{t-1}, a_t], & \text{others} \end{cases} \end{equation}Wt={[Wt−1,at],[at−w+1,…,at−1,at],if St−1=Listenothers
在等式(2)中 ata_tat 表示 ttt 时刻滑动窗口内的语音块,www 是滑动窗口的尺寸,在文章中被设置为4.
3.2 训练数据构建:
为了获得用于训练的对话状态标签,我们对原始的音频对话数据进行了处理。我们的训练数据来源于 Fisher 数据集,该数据集包含了两位说话者分别录制的对话音频。我们首先使用语音活动检测(VAD)对音频中有效的语音片段进行标注,以提取所谓的“句间停顿单元(IPU)”。IPU 被定义为单个说话者连续的语音片段。如果两个相邻的 IPU 之间的静默间隔少于 160 毫秒,则将它们合并为一个 IPU。
若一个 IPU 完全被另一位说话者的语音重叠,则将其标记为 backchannel(附和语气词),这类语音不需要系统作出回复或打断。其余未被重叠的 IPU 被标记为有效的对话轮次(valid dialogue turn),如图 3 所示。

此外,由于对话轮次中可能包含第三方语音(例如背景广播或无关人员的讲话),我们使用 GPT-4o 来进一步筛选每轮对话中的 IPU 片段。具体做法是,将处理过的对话上下文作为参考,提示 GPT-4o 判断某一 IPU 片段(通过 ASR 转写为文本)是否与上下文语义相关。相关的评估提示语详见附录 A.1。我们随机抽取了 100 个样本进行人工评估,GPT-4o 自动判断的接受率达到了 84%。
我们随机将一位说话者设为用户,另一位设为助手,然后根据 VAD 的时间戳将有效的轮次组织为用户-助手的对话流程。最终我们得到了包含 671 小时英文 Fisher 数据 和 263 小时中文 Fisher 数据 的数据集。训练数据集中各类标签的分布见表 1。
关于训练数据的组织方式(见图 3),我们采用滑动窗口机制对音频流进行重新分段。每个重组后的音频片段都根据 VAD 提取的信息(例如轮次转换、话语是否完成、系统当前状态)进行标注,并附加历史对话上下文。结合已有研究成果和我们系统的目标,我们在标注过程中引入了人类偏好。轮次转换的标注与说话者的反应模式相关:为模拟真实世界中的打断场景,FlexDuo 规定助手(Assistant)只能在用户(User)发言结束之后才开始接管轮次。然而,为了真实还原用户打断的行为,用户的接管时机保持不变,从而完整模拟用户在特定时刻打断系统的现实情境。
为了区分「backchannel」(即 “嗯”、“我明白了” 这类不打断的应答)与真正的用户打断行为,我们将系统的“聆听阶段”设定为在用户发言开始 500 毫秒之后再启动。这一延迟给予系统判断语义的时间,确保在处理重叠语音时更加稳健,同时保持自然的对话节奏。
3.3 模型训练
我们使用 Qwen2-audio-7B-Instruct 作为基础模型,因为它在音频理解任务中表现优异,能够帮助我们从用户语音中提取语义和音频特征。为了保持其音频处理能力,我们将音频编码器部分冻结不动,仅对大语言模型(LLM)部分进行训练,以实现双工交互对齐。我们为对话动作在 LLM 的词汇表中添加了特殊 token。在每个任务中,模型的输入包括:历史对话上下文、当前时间窗口内的用户音频,以及当前对话状态。模型推理完成后,会输出一个对话动作 token,FlexDuo 随后将最终的控制信号返回给半双工的 LLM。
4. 实验
4.1 评估指标
为了自动评估 FlexDuo 在全双工对话场景中的表现,我们从两个维度进行考察:交互能力 和 对话质量。
在交互能力方面,我们参考 MinMo,使用轮次接管(turn-taking)指标来评估系统管理对话轮次转换的能力。测试集从 Fisher 数据集中提取,并按照前述的数据构建方法进行轮次注释。此外,我们引入错误打断率(false interruption rate)来评估系统错误打断对方说话的情况。具体而言,评估指标被划分为四项任务:用户接管(User turn-taking),助手接管(Assistant turn-taking),助手错误打断率(Assistant false interruption rate)和用户错误打断率(User false interruption rate)。
对于轮次接管任务,我们关注系统能否在前 K 帧内正确接管对话:对于助手接管(Assistant turn-taking),我们评估系统在前 K 个语音帧内成功切换到 “Speak” 状态的 F1 分数。对于用户接管(User turn-taking),我们评估模型能否在前 K 个语音帧内成功从 “Speak” 状态转移到 “Idle” 或 “Listen” 状态的 F1 分数。
对于错误打断率(false interruption rate),我们计算某一说话者的正常对话中被另一说话者错误打断的比例。具体而言,对于助手的错误打断(Assistant false interruption),我们衡量在用户正在说话时,助手错误地插话的情况。助手错误打断率 FaF_aFa 的计算方式如下:Fa=1−(1/N)∑i=1NIiDiF_a=1-(1/N)\sum_{i=1}^N\frac{I_i}{D_i}Fa=1−(1/N)∑i=1NDiIi,其中,𝑁𝑁N 表示测试集中用户在一次对话轮次中说话的样本数量。IiI_iIi 表示从用户开始说话到助手错误打断为止的时间持续长度。DiD_iDi 表示用户该轮说话的总持续时间。如果该样本中用户的讲话未被助手错误打断,则视为 Ii=DiI_i=D_iIi=Di。
对于用户错误打断率(User false interruption),我们评估以下场景:当助手正在说话时,用户发出附和声(如“嗯”“我知道了”)或无关噪音,结果助手被错误中断。用户错误打断率 FuF_uFu 的计算公式为:Fu=1−(1M∑i=1MSiTi)F_u=1-(\frac{1}{M}\sum_{i=1}^M\frac{S_i}{T_i})Fu=1−(M1∑i=1MTiSi),其中:MMM 表示测试集中助手在一个轮次中说话的样本数量;SiS_iSi 表示助手开始说话后直到被用户或背景噪音错误打断为止的持续时间;TiT_iTi 表示该轮助手原本应完成的说话时间(即期望持续时间)。如果该样本中助手未被用户错误打断,则视为 Si=TiS_i=T_iSi=Ti。
在轮次接管能力与错误打断率之间存在权衡关系。例如:如果助手采用激进策略,即快速响应并倾向于打断用户,那么助手的轮次接管指标会提升,但与此同时,错误打断率也会增加;相反,如果助手采用保守策略,即礼貌地等待并允许用户打断自己,那么用户的轮次接管指标会提升,但用户的错误打断率也会升高。
为了全面反映系统在轮次交替与错误打断控制方面的综合表现,论文设置参数 k=1k=1k=1,并进行以下计算:将用户与助手的轮次接管 F1 分数的平均值记为 “轮次接管综合分(Turn-taking Combined)”;将用户与助手的错误打断率的平均值记为 “错误打断率综合分(False Interruption rate Combined)”。
为了评估对话质量,我们对比评估了集成了 FlexDuo 与传统基于 VAD 的半双工 LLM 系统的性能差异。具体做法是:使用 Fisher 语料库中的对话,将其中一位说话者的音频同时传入两个系统,并为基线 LLM 提供 20 轮历史上下文用于对齐语境(详见附录 A.2)。音频输入在上下文之后开始。随后,我们收集两个系统的输入音频和生成音频,并通过自动语音识别(ASR)进行转录。
我们采用条件困惑度(Conditional Perplexity) 作为衡量对话质量的指标。对于多轮对话的困惑度得分,我们使用 Qwen2.5-1.5B-Instruct 模型计算,同时将对话历史上下文一并提供。
4.2 训练配置
我们使用 Qwen2-audio-7B-Instruct 作为基础模型,并在 Fisher 数据集上进行了微调,该数据集包含 831 小时的英文语料和 389 小时的中文语料。数据集按 10:1:1 的比例划分为训练集、验证集和测试集。训练目标为标准的 交叉熵损失函数(cross-entropy),并对历史对话上下文和用户音频输入部分进行了 损失屏蔽(loss masking),以避免对这些部分反向传播无效梯度。我们采用了 AdamW 优化器(学习率设为 1e-5),每张 GPU 的 批大小为 3,总训练步数为 40,000 步,其中 前 500 步用于热身(warm-up)。训练在 8 张 NVIDIA H800 GPU 上进行,并使用了 DeepSpeed ZeRO-3 优化策略来提升显存利用效率和分布式训练性能。
4.3 基线
我们主要比较了三类系统:(1)全双工系统:如 Moshi。(2)借助 VAD 的双工系统:如 Freeze-Omni 和 MinMo。(3)基于 VAD 的半双工系统。其中,Moshi 通过并行处理用户和系统的音频流,实现了真正的全双工对话系统,突破了传统轮流说话机制的限制。Freeze-Omni 采用三阶段训练策略,分别优化语音输入编码、语音输出解码以及双工状态控制模块。然而,它仍依赖于一个预处理的 VAD 模块(Voice Activity Detection,语音活动检测) 来识别用户的语音输入。MinMo 作为一种集成架构,内置了全双工预测模块,能够实时判断系统是否应该暂停或继续响应。VAD 是一种将音频信号中的语音段与非语音段区分开的技术。通过检测语音活动并设置静音阈值,VAD 控制对话系统的轮换说话行为,决定何时交出或争取发言权。
4.4 主要结果
FlexDuo 可以适配任何半双工对话系统。在本论文中,我们将 FlexDuo 集成到 GLM4-voice 和 MiniCPM-o 中,构建了一个全双工语音对话系统(SDS),并与当前开源最先进的系统在交互能力指标上进行了对比。结果如表 2 所示。
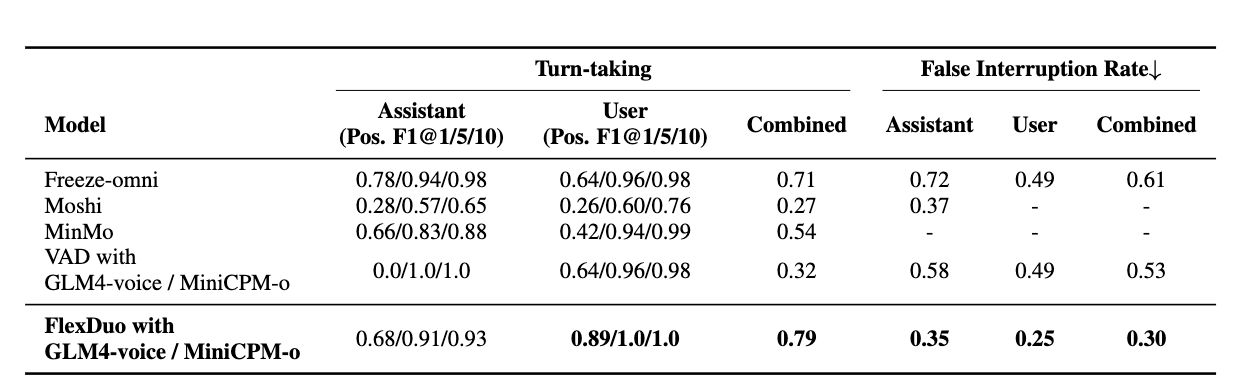
结果表明,在使用相同生成模型的前提下,相较于基于 VAD 的系统,我们的方法显著提升了全双工交互能力。此外,得益于对 “Idle(空闲)” 状态的显式建模,FlexDuo 能够比现有的全双工对话系统更有效地降低误打断率,从而在轮换发言与错误打断两项任务之间实现更好的平衡。
与基于 VAD 控制的半双工系统相比,FlexDuo 将整体误打断率降低了 23.1%,同时保持了可比的轮换发言性能。进一步地,与集成式全双工对话系统的基线模型相比,FlexDuo 实现了 23% 的整体误打断率降低 和 8% 的轮换发言性能提升。
值得注意的是,VAD 在本研究中仅作为工具用于分割有效音频。我们采用图 3 右侧所示的方法,能够从全局视角在离线条件下精确标注训练音频数据。因此,虽然我们的训练数据标注依赖 VAD,但所提出的 FlexDuo 在性能上依然能够超越它。
4.5 关于 “Idle(空闲)” 状态的消融实验
为了验证显式定义的 Idle 状态对系统性能的关键影响,本实验通过在双工控制模块中移除 Idle 状态,进行对比分析。我们将原始模型(FlexDuo)与去除 Idle 状态后的模型(w/o Idle)在核心交互能力指标上的表现进行了比较,结果如表 3 所示。在噪声环境下移除 Idle 状态后,整体轮换发言的 F1 得分下降了 15.68%,而误打断率上升了 13.62%。这些结果表明,Idle 状态在噪声过滤与响应敏感性之间起到了有效的平衡作用。

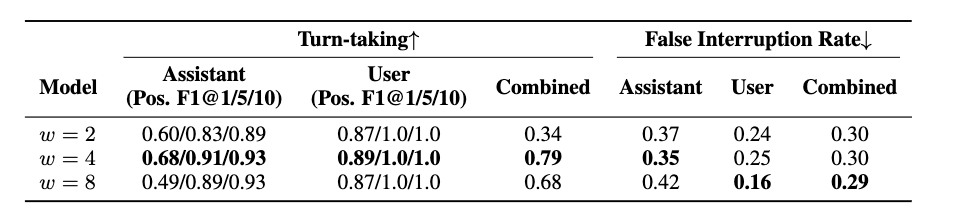
为研究滑动窗口大小对全双工系统交互性能的影响,我们在 Fisher 对话数据集上设计了一个控制变量实验。我们设置了窗口大小 w∈{2,4,8}w \in \{2,4,8\}w∈{2,4,8},并测量了不同配置下的交互性能指标差异。如表 4 所示,在选择滑动窗口大小时存在权衡关系:较小的滑动窗口有利于助手实时响应,但会削弱语义理解能力;相反,较大的滑动窗口能够增强上下文建模能力,但会带来交互延迟。
4.6 对话质量与延迟
表 5 展示了在生成模型 GLM4-Voice 下,FlexDuo 与 VAD 控制系统的性能对比。在 Fisher 英语数据集上,FlexDuo 实现了 35.3% 的条件困惑度(Conditional Perplexity, cond. PPL)降低,而在中文数据集上则降低了 19%。这些实验结果表明,FlexDuo 能够在真实场景中有效管理轮换(turn-taking)与上下文选择(context selection)(参见附录 A.2 中的示例,由于历史上下文不同,VAD 控制系统生成的回复存在逻辑不一致性)。
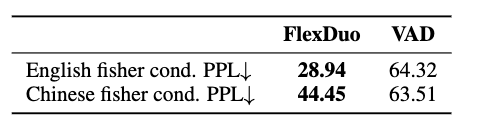
表 6 对比了 FlexDuo 模块与 VAD 模块的响应延迟。VAD 系统的延迟通常是人为设置的阈值超参数,用于在响应速度与准确性之间取得平衡。500ms 的设置值来自于商业产品与学术研究中的默认配置 [33]。FlexDuo 通过语义理解预测对话状态,在用户语音尚未完全结束前便做出响应。这种方式克服了传统 VAD 对显著停顿的依赖,能够在语义单元完成后立即响应,从而将平均响应延迟减少了 156 毫秒。

5. 结论
本文针对全双工语音对话系统(Full-Duplex SDS)中存在的模块耦合度高、语境噪声干扰严重等问题,提出了一种模块化双工控制框架。该框架通过可插拔架构设计与显式 Idle(空闲)状态建模,显著提升了系统的交互能力与对话质量。具体而言,该设计将双工控制从语音对话系统中解耦,使现有的半双工对话系统能够直接复用,从而大幅降低系统升级与优化成本。受人类在对话中过滤无关信息能力的启发,我们引入了 Idle 状态,用于过滤噪声与冗余输入,确保对话历史语境的清晰度。通过精心设计的七种对话策略与有限状态机(FSM)机制的协同控制,系统能够动态应对复杂的交互场景,例如打断与回声反馈(backchannel)交流。未来,我们将重点开展两个研究方向:探索多模态信息(如视线、手势、面部表情)在协同全双工对话控制中的集成;建模用户的对话状态,构建更加全面的对话策略,并引入强化学习进行训练与优化。


















 267
267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











