




 超级会员免费看
超级会员免费看
1. 常用通信算子
2. 各通信算子的功能
-
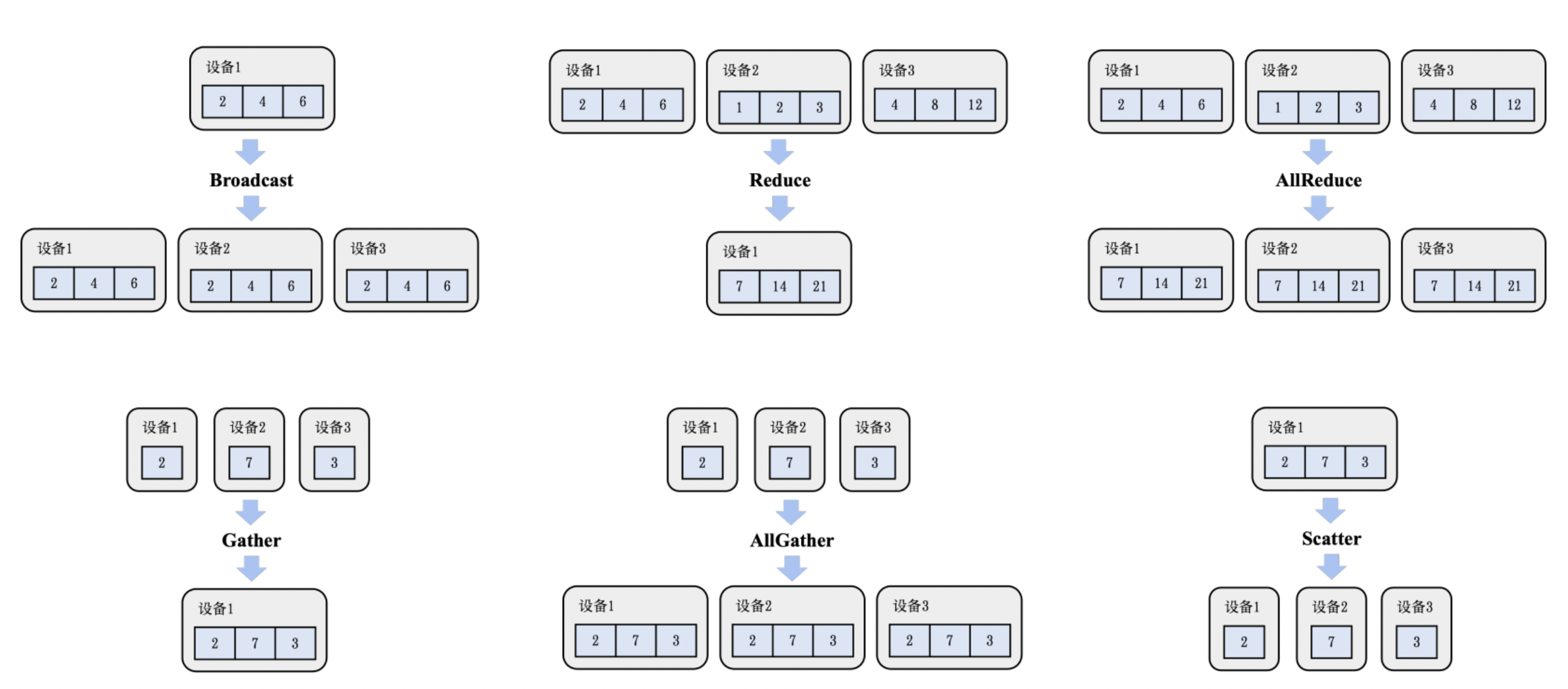
Broadcast
输入:一个 GPU(如 GPU 0)上有一份数据,例如模型参数 W。
操作:这个数据被 广播 到所有其他 GPU。
输出:每个 GPU 都拥有一份相同的 W。
-
Gather(收集)
作用:把多个设备上的张量数据收集到一个指定设备(通常是 rank 0)。
🔹 示例:
假设有 4 个 GPU,每个 GPU 上有一个张量 x_i:GPU0: x0
GPU1: x1
GPU2: x2
GPU3: x3
执行 Gather(to=GPU0) 后:
GPU0: [x0, x1, x2, x3]
GPU1: -
GPU2: -
GPU3: -
-
All-Gather
每个节点保留自己数据,并收集其它节点的数据,拼成一个完整的大张量。
输入: 每个 GPU 有一块张量 x_i。
操作: 所有 GPU 把自己的张量广播给其他 GPU。
输出: 每个 GPU 拿到所有 GPU 的数据:[x_0, x_1, …, x_{n-1}]。
📦 用途:
张量并行时,将切分在不同 GPU 的子张量重新拼成完整张量,供后续使用。
🧠 类比:
像小组每人写了一部分论文,然后大家交换收集后各自合并出完整稿。
-
Reduce(归约)
作用:将多个设备上的张量执行一个归约操作(如加法、最大值、平均值),并将结果存储在一个目标设备上。🔹 示例(reduce-sum to GPU0):
GPU0: x0
GPU1: x1
GPU2: x2
GPU3: x3
执行 Reduce(op=sum, to=GPU0) 后:
GPU0: x0 + x1 + x2 + x3
GPU1: -
GPU2: -
GPU3: -
可以把它看作:先收集,再相加,但更高效。
-
All-Reduce
所有节点先各自计算,然后将结果加和(或其他操作)后广播给每个节点。输入: 每个 GPU 有一块张量 x_i。
操作: 所有 GPU 进行加法归约(reduce, 如 sum),然后 同步每人一份(all)。
输出: 每个 GPU 得到的是同样的一份归约后的结果。
📦 用途:
梯度同步:模型并行 / 数据并行训练时,各个 GPU 算出的梯度需要合并平均,All-Reduce 是最常用方式。
🧠 类比:
像大家各自写了一份报告,然后统一汇总整理(求和),再发一份完整版给所有人。
-
Scatter(分发)
作用:将一个大张量(或张量列表)从一个设备分发到多个设备上,每个设备拿到一部分。
🔹 示例:
GPU0 有一个张量列表 [x0, x1, x2, x3],执行 Scatter(from=GPU0) 后:GPU0: x0
GPU1: x1
GPU2: x2
GPU3: x3
这是 Gather 的反操作,常用于把输入切片后发给不同 GPU 并行处理。
-
Reduce-Scatter
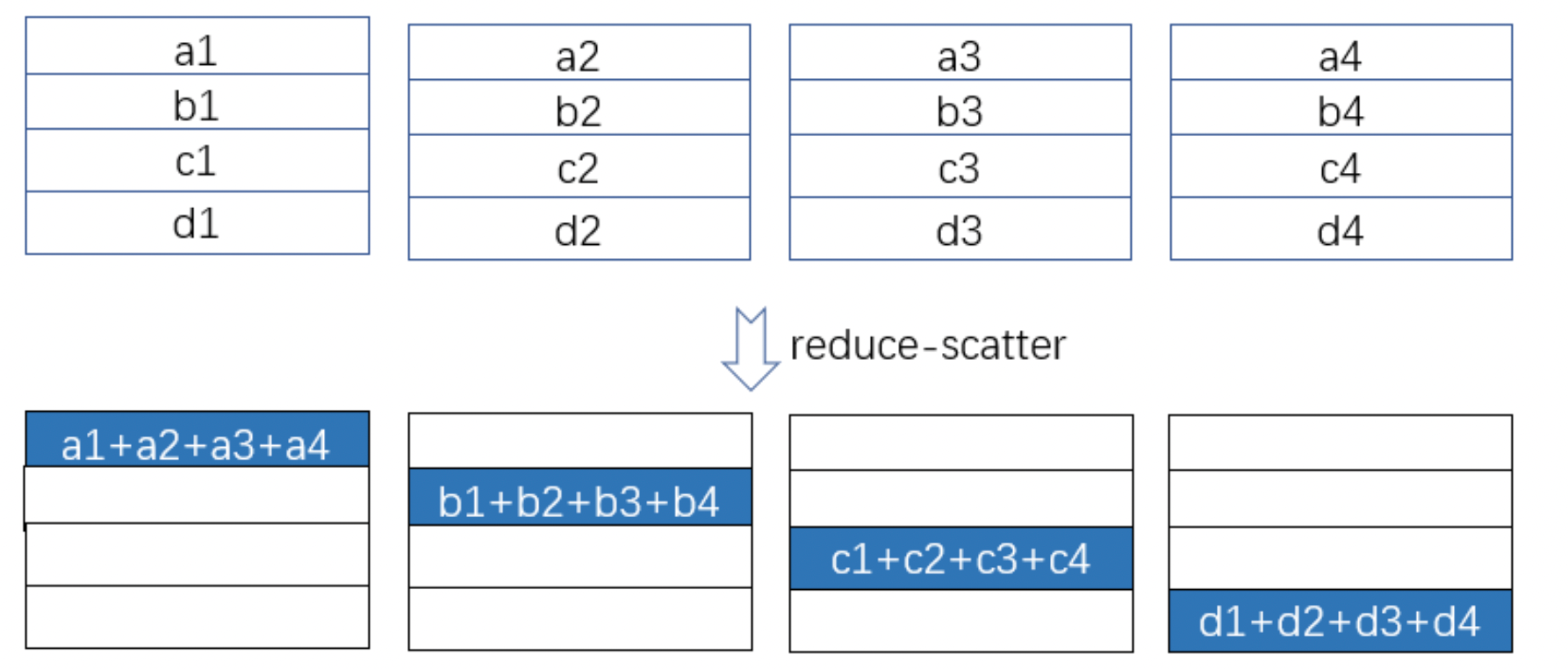
All-Reduce 的反操作:先将数据加和(reduce),然后将总结果切分发给各 GPU。
输入: 每个 GPU 有一个完整张量。
操作: 先将所有 GPU 的对应位置的数据加和,然后均匀分发切片给各 GPU。
输出: 每个 GPU 得到总归约结果的一部分(即一个 slice)。
📦 用途:常在反向传播中配合 All-Gather 使用,实现模型并行高效通信。在深度学习显存优化ZeRO中经常被用到。
🧠 类比:每人写了一份报告,大家加总起来,统一剪成几段,每人分一段。


















 558
558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











