



近期,针对同学们普遍关注的2025年下半年计算机技术与软件专业技术资格(软考)考试安排,现就有关考试科目及适宜人群简要说明如下,供广大考生参考。
一、关于考试时间安排
2025年下半年软考预计将于11月份举行。由于当前距离考试尚有一段时间,建议考生合理规划备考节奏,避免战线过长,影响学习效率。建议结合个人实际情况,适时启动备考工作。
二、关于中级考试科目
在中级类考试中,系统集成项目管理工程师为较受关注的重点科目。该科目被广泛认为是高级“信息系统项目管理师”(俗称“高项”)的中级替代版本,其考试内容约有60%至80%与高项高度重合,区别主要在于不包含论文写作部分,故考试难度相对较低。部分考生在上半年完成高项考试后,未做额外复习便直接报考本科目,亦能顺利通过,具有一定代表性和参考意义。
除系统集成项目管理工程师外,其余中级科目可依据考生所掌握的专业知识和工作领域进行选择。总体而言,中级科目不涉及论文,考试难度适中,适合希望通过考试提升专业能力和职业资质的人员报考。
三、关于高级考试科目
下半年高级考试中,信息系统项目管理师(高项)将不再开设。对于非计算机专业背景的考生而言,系统规划与管理师可视为其合适替代选项。2025年11月为该科目启用新版教材后的首次考试。虽然教材篇幅增加至原来的两倍,但内容结构更趋系统化,与“规划师”定位进一步契合,建议考生合理把握此次新教材首考的机会。

详情可以参考:
除系统规划与管理师外,其他高级考试如系统架构设计师、系统分析师及网络规划设计师等,技术专业性较强,适合计算机相关专业或从事技术研发与系统设计岗位的考生报考。建议非相关专业背景人员根据自身情况谨慎选择。
如果决定要冲击高级,但是不理解高级之间的区别的,可以参考下面这篇文章:
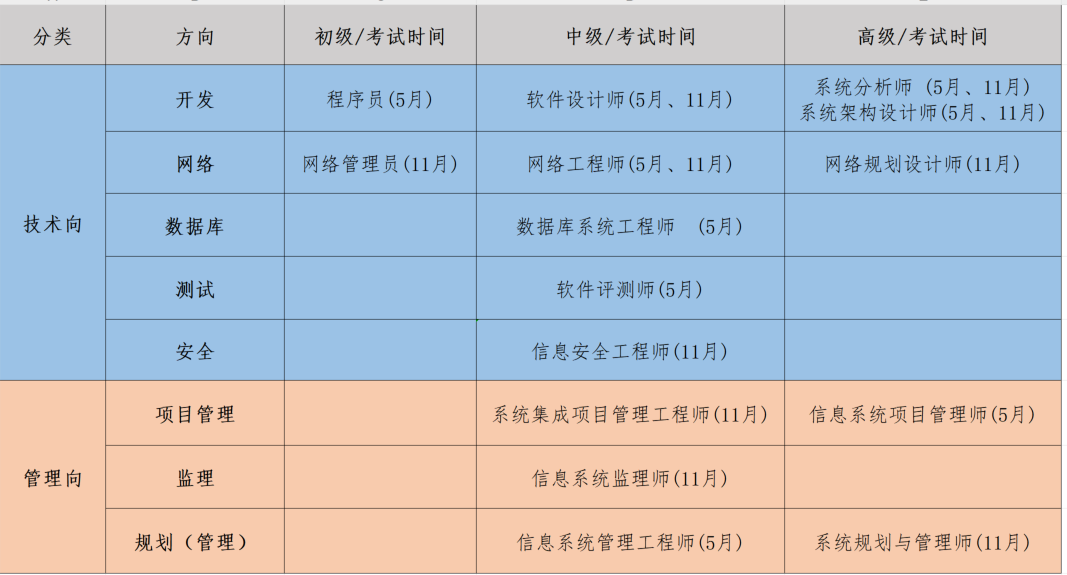
下表是我们根据科目时间安排、中高级、技术管理两条主线等因素做了归纳整理的结果,供不同背景、基础的同学参考。

















 1749
1749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









