




0、资源链接
官方 readme: https://github.com/hiyouga/LLaMA-Factory/blob/v0.9.1/README_zh.md
官方文档: https://llamafactory.readthedocs.io/zh-cn/latest/
官方推荐的知乎教程:https://zhuanlan.zhihu.com/p/695287607
1、安装 LLaMA Factory
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"笔者conda环境 Python 包如下:
accelerate==1.4.0 aiofiles==23.2.1 aiohappyeyeballs==2.6.1 aiohttp==3.11.13 aiosignal==1.3.2 airportsdata==20250224 annotated-types==0.7.0 anyio==4.8.0 astor==0.8.1 async-timeout==5.0.1 attrs==25.2.0 audioread==3.0.1 av==14.2.0 blake3==1.0.4 certifi==2025.1.31 cffi==1.17.1 charset-normalizer==3.4.1 click==8.1.8 cloudpickle==3.1.1 compressed-tensors==0.9.1 contourpy==1.3.1 cupy-cuda12x==13.4.0 cycler==0.12.1 datasets==3.3.2 decorator==5.2.1 depyf==0.18.0 dill==0.3.8 diskcache==5.6.3 distro==1.9.0 dnspython==2.7.0 docstring_parser==0.16 einops==0.8.1 email_validator==2.2.0 exceptiongroup==1.2.2 fastapi==0.115.11 fastapi-cli==0.0.7 fastrlock==0.8.3 ffmpy==0.5.0 filelock==3.17.0 fire==0.7.0 fonttools==4.56.0 frozenlist==1.5.0 fsspec==2024.12.0 gguf==0.10.0 gradio==5.21.0 gradio_client==1.7.2 groovy==0.1.2 h11==0.14.0 httpcore==1.0.7 httptools==0.6.4 httpx==0.28.1 huggingface-hub==0.29.3 idna==3.10 importlib_metadata==8.6.1 iniconfig==2.0.0 interegular==0.3.3 jieba==0.42.1 Jinja2==3.1.6 jiter==0.9.0 joblib==1.4.2 jsonschema==4.23.0 jsonschema-specifications==2024.10.1 kiwisolver==1.4.8 lark==1.2.2 lazy_loader==0.4 librosa==0.11.0 -e git+https://github.com/hiyouga/LLaMA-Factory.git@30038d9ce701b421bd521c72073fcc08909fe25a#egg=llamafactory llvmlite==0.43.0 lm-format-enforcer==0.10.11 markdown-it-py==3.0.0 MarkupSafe==2.1.5 matplotlib==3.10.1 mdurl==0.1.2 mistral_common==1.5.3 mpmath==1.3.0 msgpack==1.1.0 msgspec==0.19.0 multidict==6.1.0 multiprocess==0.70.16 nest-asyncio==1.6.0 networkx==3.4.2 nltk==3.9.1 numba==0.60.0 numpy==1.26.4 nvidia-cublas-cu12==12.4.5.8 nvidia-cuda-cupti-cu12==12.4.127 nvidia-cuda-nvrtc-cu12==12.4.127 nvidia-cuda-runtime-cu12==12.4.127 nvidia-cudnn-cu12==9.1.0.70 nvidia-cufft-cu12==11.2.1.3 nvidia-curand-cu12==10.3.5.147 nvidia-cusolver-cu12==11.6.1.9 nvidia-cusparse-cu12==12.3.1.170 nvidia-cusparselt-cu12==0.6.2 nvidia-nccl-cu12==2.21.5 nvidia-nvjitlink-cu12==12.4.127 nvidia-nvtx-cu12==12.4.127 openai==1.66.3 opencv-python-headless==4.11.0.86 orjson==3.10.15 outlines==0.1.11 outlines_core==0.1.26 packaging==24.2 pandas==2.2.3 partial-json-parser==0.2.1.1.post5 peft==0.12.0 pillow==11.1.0 platformdirs==4.3.6 pluggy==1.5.0 pooch==1.8.2 prometheus-fastapi-instrumentator==7.0.2 prometheus_client==0.21.1 propcache==0.3.0 protobuf==6.30.0 psutil==7.0.0 py-cpuinfo==9.0.0 pyarrow==19.0.1 pybind11==2.13.6 pycountry==24.6.1 pycparser==2.22 pydantic==2.10.6 pydantic_core==2.27.2 pydub==0.25.1 Pygments==2.19.1 pyparsing==3.2.1 pytest==8.3.5 python-dateutil==2.9.0.post0 python-dotenv==1.0.1 python-multipart==0.0.20 pytz==2025.1 PyYAML==6.0.2 pyzmq==26.3.0 qwen-vl-utils==0.0.10 ray==2.40.0 referencing==0.36.2 regex==2024.11.6 requests==2.32.3 rich==13.9.4 rich-toolkit==0.13.2 rouge-chinese==1.0.3 rpds-py==0.23.1 ruff==0.11.0 safehttpx==0.1.6 safetensors==0.5.3 scikit-learn==1.6.1 scipy==1.15.2 semantic-version==2.10.0 sentencepiece==0.2.0 shellingham==1.5.4 shtab==1.7.1 six==1.17.0 sniffio==1.3.1 soundfile==0.13.1 soxr==0.5.0.post1 sse-starlette==2.2.1 starlette==0.46.1 sympy==1.13.1 termcolor==2.5.0 threadpoolctl==3.6.0 tiktoken==0.9.0 tokenizers==0.21.0 tomli==2.2.1 tomlkit==0.13.2 torch==2.5.1 torchaudio==2.5.1 torchvision==0.20.1 tqdm==4.67.1 transformers @ file:///home/coco/my_project/transformers triton==3.1.0 trl==0.9.6 typer==0.15.2 typing_extensions==4.12.2 tyro==0.8.14 tzdata==2025.1 urllib3==2.3.0 uvicorn==0.34.0 uvloop==0.21.0 vllm==0.7.3 watchfiles==1.0.4 websockets==15.0.1 xformers==0.0.28.post3 xgrammar==0.1.11 xxhash==3.5.0 yarl==1.18.3 zipp==3.21.0
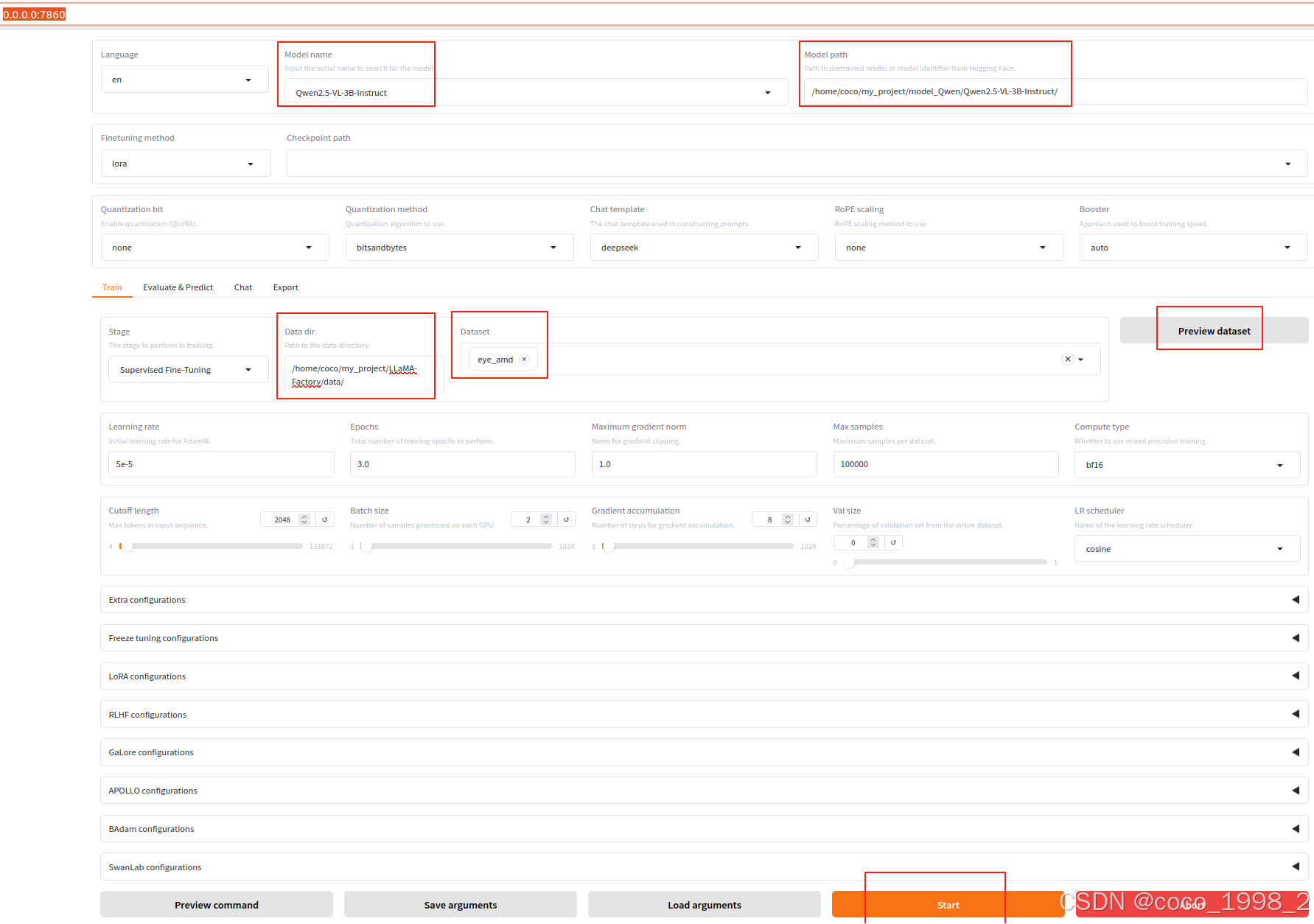
2、可视化微调UI页面
LLaMA Board 可视化微调(由 Gradio 驱动)
命令行输入:
llamafactory-cli webui执行截图:

3、finetune 数据准备
关于数据集文件的格式,请参考 data/README_zh.md 的内容。你可以使用 HuggingFace / ModelScope / Modelers 上的数据集或加载本地数据集。
注册数据集
需要在/home/coco/my_project/LLaMA-Factory/data/dataset_info.json文件中注册自定义数据集。笔者使用的数据集定义如下:
"eye_amd": {
"file_name": "short_ds_vl2_AMD_DR_train.json",
"formatting": "sharegpt",
"columns": {
&n
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2512
2512

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









