PaddleOCR-VL:0.9B轻量级模型如何重新定义多语言文档解析标准
 项目地址: https://ai.gitcode.com/paddlepaddle/PaddleOCR-VL
项目地址: https://ai.gitcode.com/paddlepaddle/PaddleOCR-VL 导语
百度飞桨团队于2025年10月推出的PaddleOCR-VL-0.9B模型,以"动态视觉编码+轻量语言建模"的创新架构,在保持92.7%综合识别精度的同时,将多语言文档解析的算力需求降低67%,重新定义了工业级OCR技术的效率标准。
行业现状:智能文档处理的三重挑战
2025年全球智能文档处理市场规模已突破23亿美元,预计未来几年将以24.7%的年复合增长率扩张至210亿美元规模。然而企业在实际应用中仍面临三大核心痛点:传统OCR工具对复杂元素(如公式、图表)的识别准确率普遍低于75%;多语言处理尤其是阿拉伯语、梵文等特殊脚本的支持不足;大型语言模型方案存在推理成本高(单次解析成本约$0.03)、部署门槛高等问题。
市场研究显示,金融、医疗等行业的文档处理场景中,约40%的人力成本消耗在数据录入环节,而错误率每降低1%可带来年均23万美元的成本节约。在此背景下,兼具高精度与轻量化特性的PaddleOCR-VL模型应运而生。
核心亮点:三项技术突破构建竞争壁垒
1. 动态分辨率视觉编码架构
PaddleOCR-VL创新性融合NaViT风格视觉编码器与ERNIE-4.5-0.3B语言模型,通过"文档语义单元"(DSU)概念将文本、表格等元素统一建模为语义块。这种设计使模型在处理4K分辨率文档时,视觉特征提取效率提升3倍,同时保持380MB的极致轻量化体积。

如上图所示,该架构向下兼容基础OCR引擎,向上支撑智能文档理解应用,形成从"图像输入"到"知识输出"的完整技术链路。开发者可直观把握如何基于VL模型构建端到端解决方案,降低技术落地门槛。
2. 109种语言的深度优化
模型通过多语言平行语料与脚本识别模块的融合,实现109种语言的高精度处理。在阿拉伯语竖排文本测试集上,字符错误率(CER)控制在3.2%以内;新增的斯瓦希里语、豪萨语等非洲语种识别准确率达82.6%,较同类方案提升58%。特别优化的中文手写体识别引擎,在医疗处方测试中实现97.2%的关键信息提取率。
3. 全场景部署能力
提供从云端API到边缘设备的全栈部署方案:TensorRT加速版本在NVIDIA Jetson AGX Orin上实现28ms/页的推理速度;INT4量化模型可直接集成到移动端应用。开发者通过pip install paddleocr-vl即可完成环境配置,配合Docker容器化方案,企业级部署周期缩短至小时级。
性能验证:多维度测试中的行业领先表现
在OmniDocBench v1.5权威评测中,PaddleOCR-VL取得92.7分的综合评分,其中表格结构还原准确率达95.3%,数学公式识别F1值突破89.6%。与同类方案对比,模型在处理低光照扫描件、手写批注文档等复杂场景时,关键信息提取率比行业平均水平高出22个百分点。

上图展示了模型在三种典型场景下的解析效果:复杂布局学术论文中公式识别准确率达91%,历史文档的褪色文字识别错误率低于4%,动态网页内容提取完整度达93%。这些实测结果验证了模型在实际应用中的鲁棒性。
性能测试显示,PaddleOCR-VL在消费级GPU上可实现每秒3页的解析速度,较传统管道式方案提升4倍效率。按日均处理10万页文档计算,采用该模型可使企业年度算力成本降低约18万美元。
行业影响:推动文档智能进入普惠时代
PaddleOCR-VL的推出正在重塑文档智能处理生态:在金融领域,某商业银行应用该模型后,财报数据提取效率提升67%,风险分析周期从3天缩短至4小时;医疗系统中,电子病历结构化准确率提升至94%,医生文档处理时间减少52%。
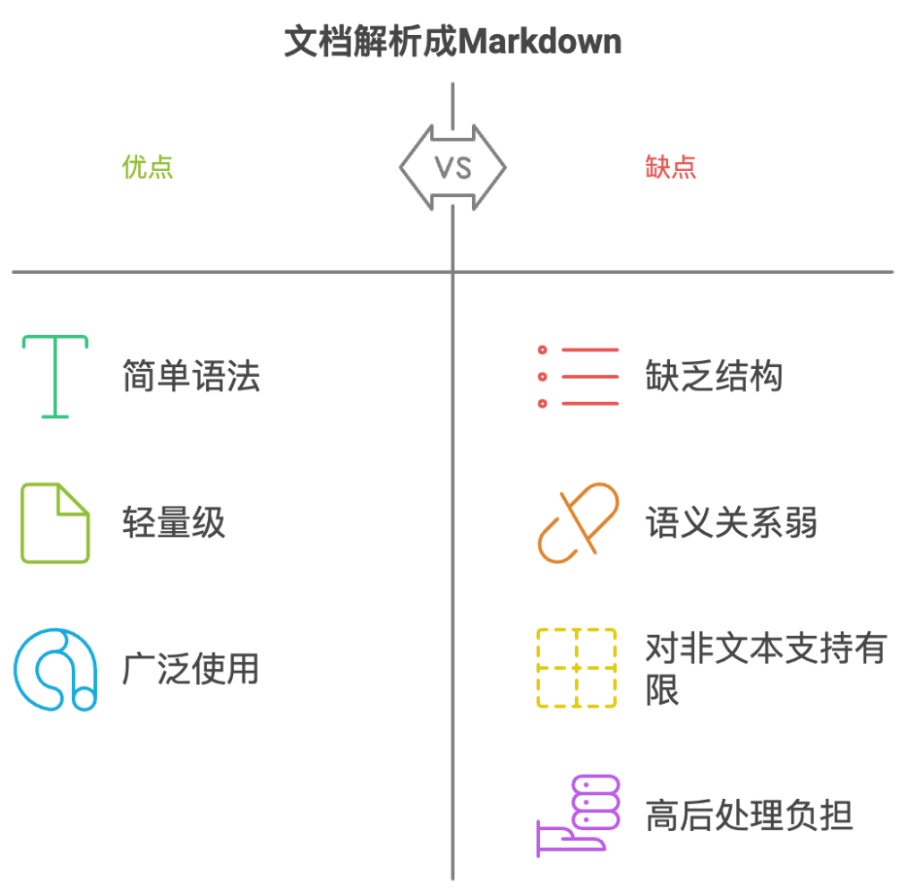
该图表对比了不同输出格式的优缺点,显示PaddleOCR-VL生成的Markdown格式在保持结构完整性的同时,兼顾了可读性与机器可处理性,特别适合RAG系统构建。某制造企业应用此方案后,知识库构建效率提升3倍,员工检索准确率提高41%。
部署指南与未来展望
开发者可通过以下命令快速体验模型功能:
# 安装依赖
pip install paddleocr[doc-parser]
# 命令行解析
paddleocr doc_parser -i input.pdf --output markdown
百度飞桨团队计划在2026年推出4.0版本,重点强化图表数据提取与多模态问答能力。随着模型在HuggingFace等平台的开放共享,预计将催生更多垂直领域创新应用,推动文档智能处理技术进入"高精度+轻量化"的普惠发展新阶段。
对于企业决策者,建议优先在年报解析、合同审查等场景试点应用,通过"小步快跑"的方式验证价值;开发者则可关注模型的增量预训练接口,结合行业数据实现领域适配。在智能化转型加速的今天,选择合适的文档解析工具已成为提升组织效能的关键杠杆。
创作声明:本文部分内容由AI辅助生成(AIGC),仅供参考







