






论文题目:Handling time-varying constraints and objectives in dynamic evolutionary multi-objective optimization
动态演化多目标优化中时变约束和目标的处理(Radhia Azzouz a,* ,SlimBechikha,LamjedBenSaida, Walid Trabelsi b)Swarm and Evolutionary Computation 39 (2018) 222–248
刚开始学习多目标优化算法,不作商业用途,如果有不正确的地方请指正!
个人总结:
摘要
- 提出一种新的自适应惩罚函数和行的可行性驱动策略,嵌入NSGA-II中。
- 。可行性驱动策略能够根据环境的变化引导搜索向新的可行方向进行
提出的算法内容
提出了一种基于NSGA - II框架的动态进化算法来进行交叉、变异和选择操作。
A.算法基本框架
初始化以后计算惩罚函数,根据惩罚函数进行排序。
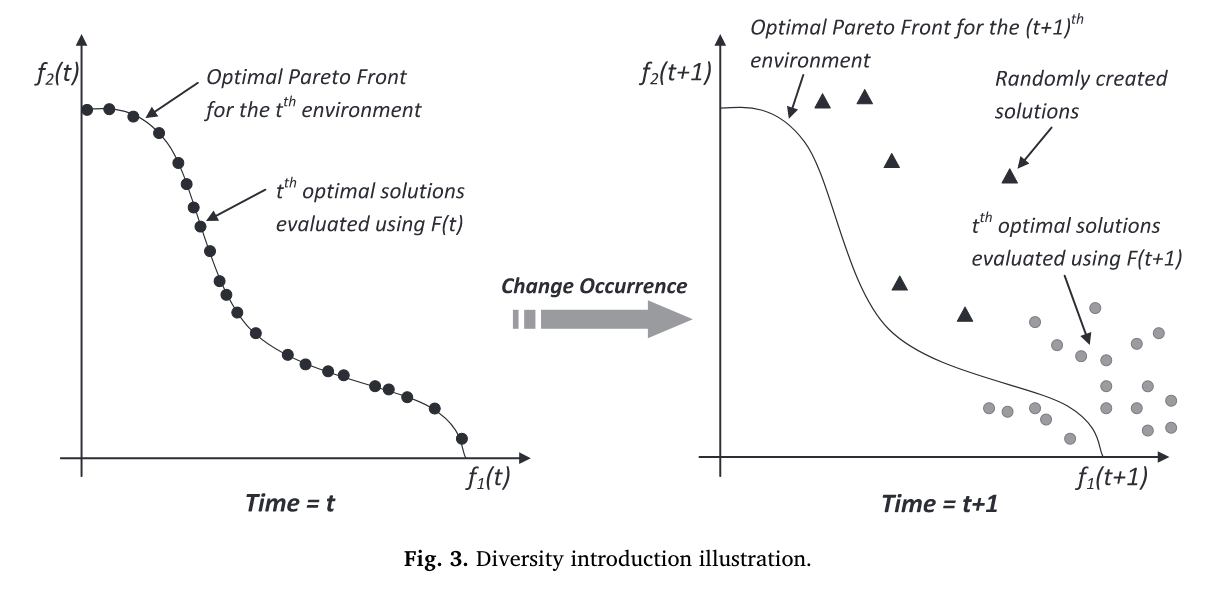
如果发生变化,使用可行性驱动策略改善一些不可行解,并引入一些随机解。
值得注意的是,在对解进行排序时,与采用约束支配原则的NSGA - II相反,采用的是经典的Pareto支配关系。这是因为使用的是基于惩罚的方法来处理约束。

B.新的动态自适应惩罚函数
提出一种适用于动态环境的自适应惩罚函数,通过将从其目标函数值中检索的信息与惩罚量本身相结合,有效地利用有趣的不可行解。即使在可行性比率较高的情况下,也应始终关注不可行解。
该惩罚函数是通过自适应地结合归一化的目标函数和归一化的约束nt违反值得到的。这种自适应组合是相对于解的质量(即目标函数值和约束nt违反值)和种群可行性比率进行的。

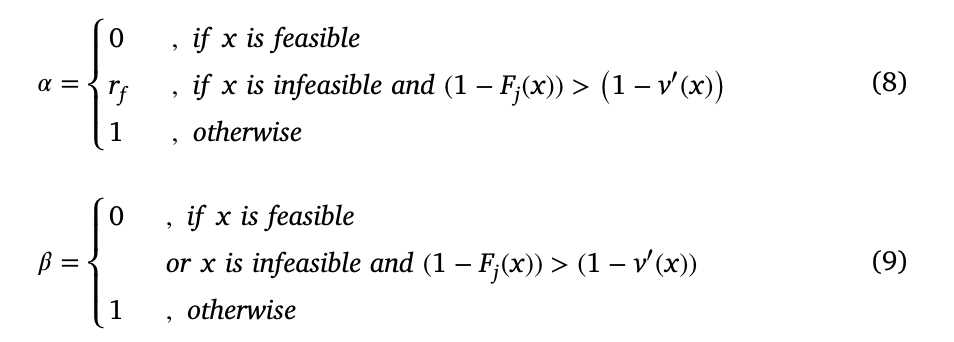
其中Fj ( x )是解x的规范化的第j个原始目标值,v′( x )是解x的规范化的约束违反值,rf是种群可行比

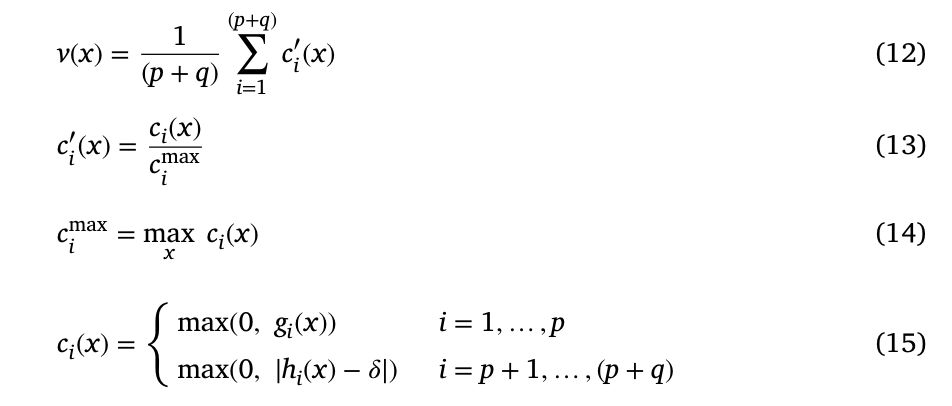
由于采用了归一化的目标函数值,第j个目标函数在可行解和不可行解中最好的解Fj = 0,最差的解Fj = 1
作为对这种情况的简单总结。可以说,当比较两个具有相同约束违反值的不可行解时,根据目标函数值来决定哪一个更好。当比较两个目标函数值相同的不可行解时,根据约束违反值进行决策。对于可行解和不可行解,若可行比例较高,则几乎是占优的可行解。否则,如果可行比例较低,则不可行解可能在约束违反值较低且目标函数值较好的情况下占优。
C.变化处理机制
该策略能够根据环境的变化引导搜索向新的可行域移动。实际上,部分PS可能位于可行域和不可行域之间的约束边界上。
我们在决策空间中的每个不可行解与其最近的可行解之间应用一个关于标准化欧氏距离的交叉算子。然后,在原始解和它的两个子解中,保持约束违反最小化方面最突出的解。通过匹配可行解和不可行解,我们帮助不可行个体向可行解进化。对这些个体的修复,主要是对那些约束违反值较低的个体的修复,不仅可以从可行的一面搜索最优解,也可以从不可行的一面搜索最优解。
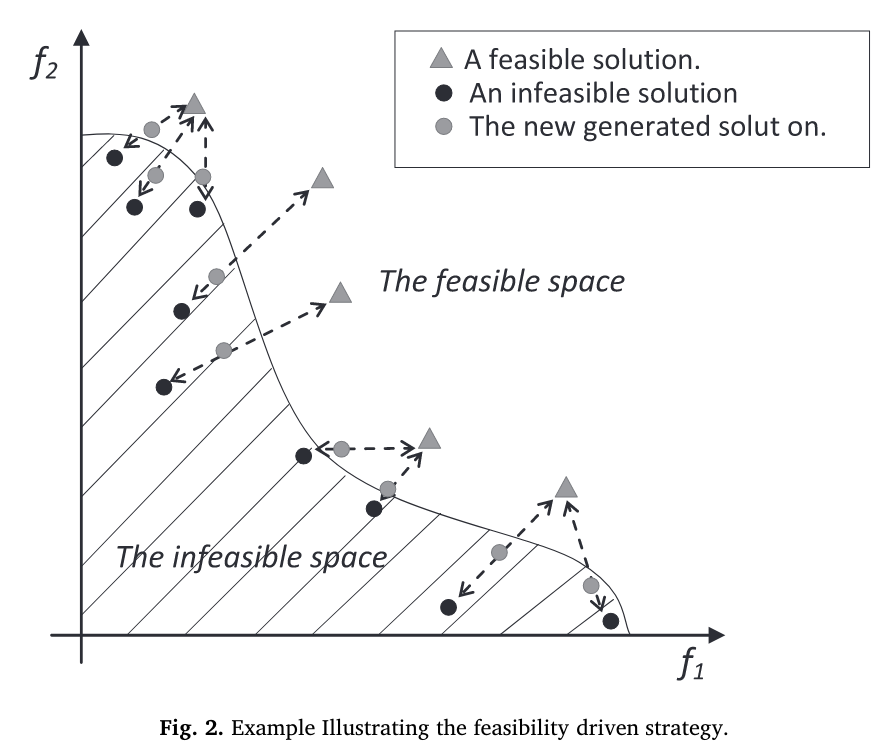
为什么进行随机初始化引入。
具体参数
Binary Tournament selection with crowded-comparison operator
( SBX ),分布指数为5,概率为0.9 分布指数为20,概率为1 /个变量的多项式变异 20%的新个体 产生。

















 2446
2446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









