




一、大模型的特点
1)不确定性 与传统应用不同,模型的输出是不确定的,即使多次问它一样的问题,给出的结果也可能不一样。这种特性对于日常应用业务 OK,但是如果要在企业内用来处理具体业务问题,就必须提高这个稳定性,否则影响生产经营,例如产线操作人员通过模型获取操作步骤或者参数,如果步骤或者数据不对可能会导致产品出现质量问题等等。
2)静态性 模型一旦训练好,就无法再补充数据,因此模型不会了解你自己组织内部的年假规定,注意事项。如何让大模型掌握这些数据是另外一个需要解决的问题。
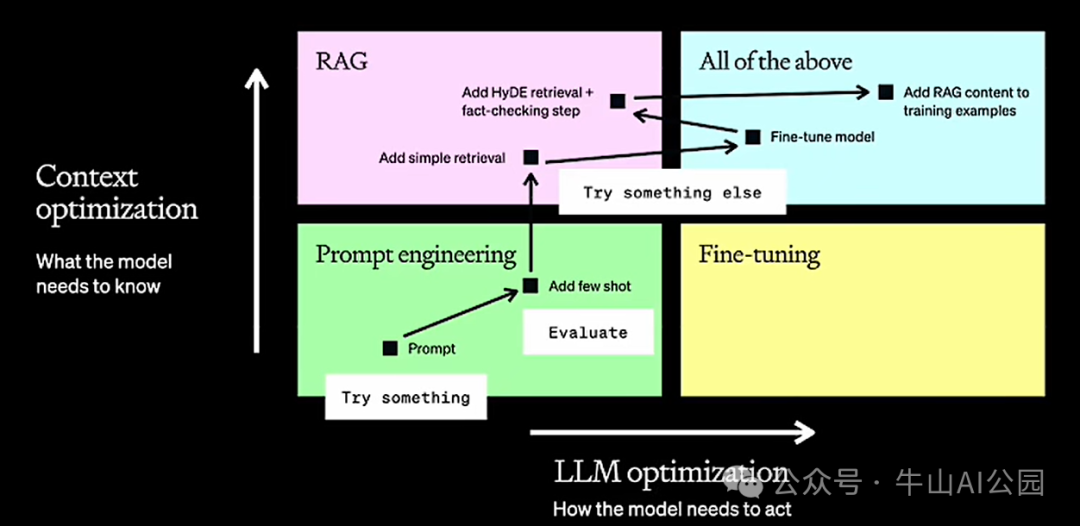
上述问题会影响大模型在企业内部的使用,因此针对模型的优化主要会有 两个方向:
行为优化: 对应上图横轴,横轴表示大模型的表现能力,让大模型做它原来不会做的事情,例如以一个医学专家的方式进行表达,或者其他新的方式进行表达,并且它能理解。这个维度主要解决模型输出形式上的稳定性。
上下文优化: 对应上图竖轴,竖轴表示大模型的知识能力,这个纬度主要关注私域数据,是让模型知道它所不知道的事情,包括:模型训练中从未见过的数据,比如内部代码、文档、规范、策略等。这个维度主要解决模型输出内容上的相关性。
二、针对大模型的优化主要有三种方法:
方法 1 提示工程(Prompt Engineering)
提示工程(Prompt Engineering)是指通过精心设计、实验及优化输入文本(即提示),来引导大型预训练语言模型(如 GPT)生成更精准、高质量输出的过程。这门技术让非编程用户也能通过类似于“指令”的方式与 AI 交互,有点类似软件工程在 AI 时代的化身。其优点包括任务归一化,简化多样任务处理流程,并能灵活适应广泛需求。缺点主要是“门槛低,落地难”,找到高效提示往往依赖反复试验且效果不稳定。
提示词工程是最经济可行,也是见效最快的方式;在生成式 AI(GenAI)这个领域中大家经常听说的 零样本/多样本学习(Zero-short/Few-short learning)或者 上下文引导学习(in-context learnning)其实都是提示词工程中的一些具体方法和技巧。在实际应用中,应该首先考虑使用提示工程的方式优化大模型应用,这是成本最低,见效最快的方式。提示词工程可以同时为模型补充上下文(上下文优化)和优化模型的行为(行为优化)。因此提示词工程可以同时在以上 2 个维度上帮助我们提升模型的性能、质量和用户体验,让我们可以更快达到目标。对任何应用场景,我们都不建议在还没有尝试提示工程的前提下就开始引入 RAG 或者微调。
方法 2 - 检索增强式内容生成(RAG - Retrieval Augmented Generation)
RAG 并不是某种系统/工具/产品,RAG 是一种为模型补充知识的方法。首先,任何的大模型一旦训练完成就变成了一个静态的文件,它只存储了在训练过程中提供给它的知识(数据)。因此,当你问 ChatGPT 自己公司内部规章制度的相关规定,它必定无法准确回答,而且还会给出误导性的答案。为了解决这个问题,最简单的方式就是先告诉大模型这些规定,然后再让它回答。这种方式就是提示词工程中的多样本学习(few-short learning)。同时,大模型是没有记忆的,你提出的每一个问题其实对他来说都是全新的问题。当我们需要为模型提供更多上下文的时
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 358
358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









