




第20章 平坦内存模型和软件任务切换
该章节的代码功能和前面几章类似,只是本章通过平坦内存模型简化开发、通过软件进行任务切换。如果前面几章都理解了,这章就容易理解了。
平坦内存模型:在实践中,又分段又分页没有必要,太过于复杂,使用分页系统提供的保护机制就已经足够了。但是分段功能是处理器固有的,任何时候都无法关闭,所以,一个变通的方法就是只分一个段,段的长度是4GB,这个就是平坦内存模型。
软件任务切换:因为硬件切换太慢,流行的操作系统不使用硬件切换,是自行在任务之间进行切换,称之为任务切换。
流行的操作系统上一般也不使用调用门,而是采用软中断或者快速系统调用的方式提供服务。
- 32位Linux通过0x80中断提供系统服务;
- 64位Linux采用64位处理器提供的快速系统调用机制。
多段模型和平坦模型
多段模型和段页式内存管理
多段模型(Multi-Segment Model):保护模式下,首先按程序的结构分段,创建各个段的描述符,用描述符指向物理内存中的各个段。描述符中的基地址给出了段的起始物理地址,界限值给出了段的长度(边界),属性值指示了段的类型和特权级别等性质。
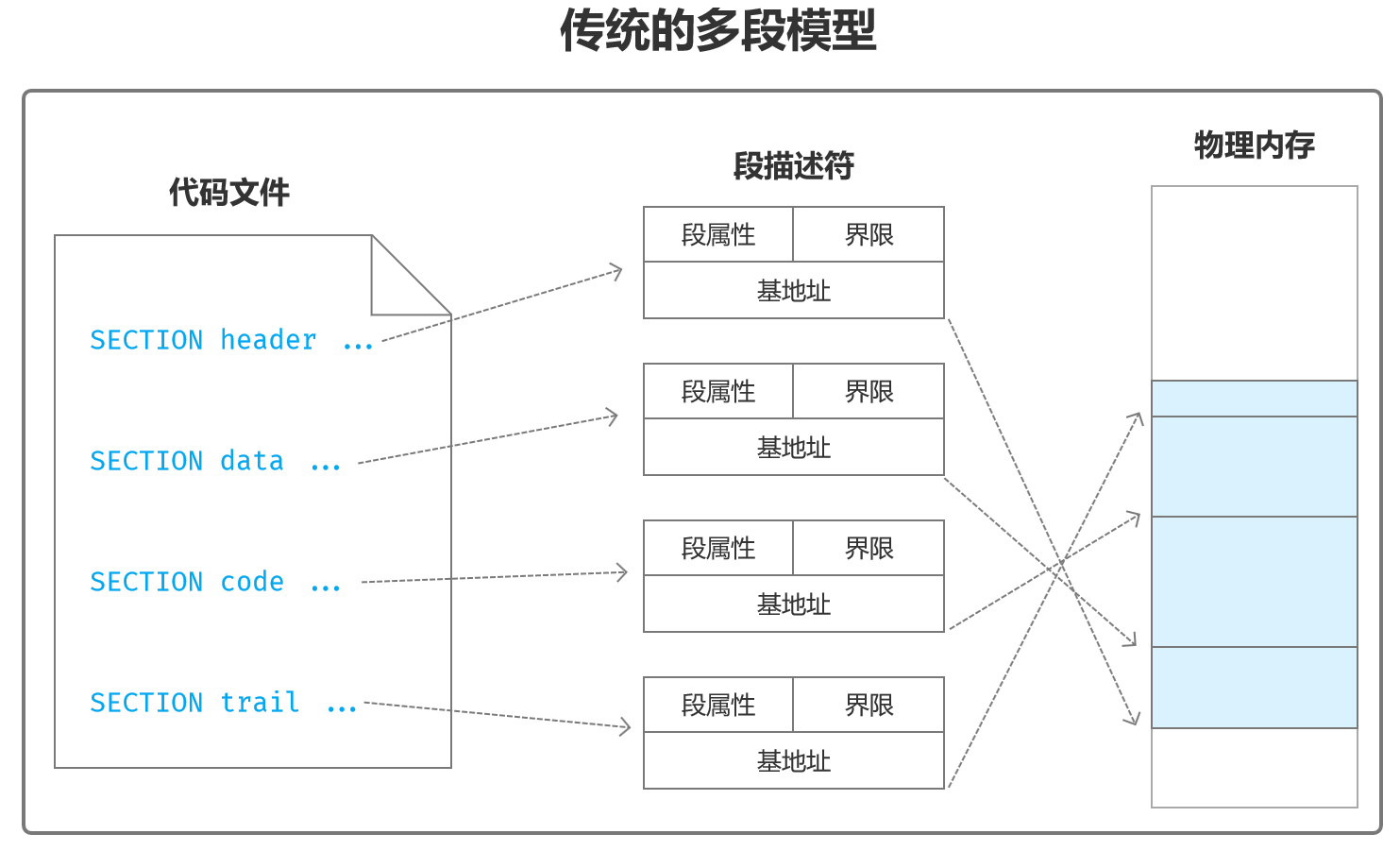
分页机制下的多段模型:传统的多段模型适用于开启了页功能之后的系统环境。依然是按程序的结构分段,创建各个段的描述符。但是,段是在任务自己的虚拟地址空间内分配的,而不是在物理内存中分配的。因此,段描述符中的基地址是段的线性地址,或者说是虚拟地址。
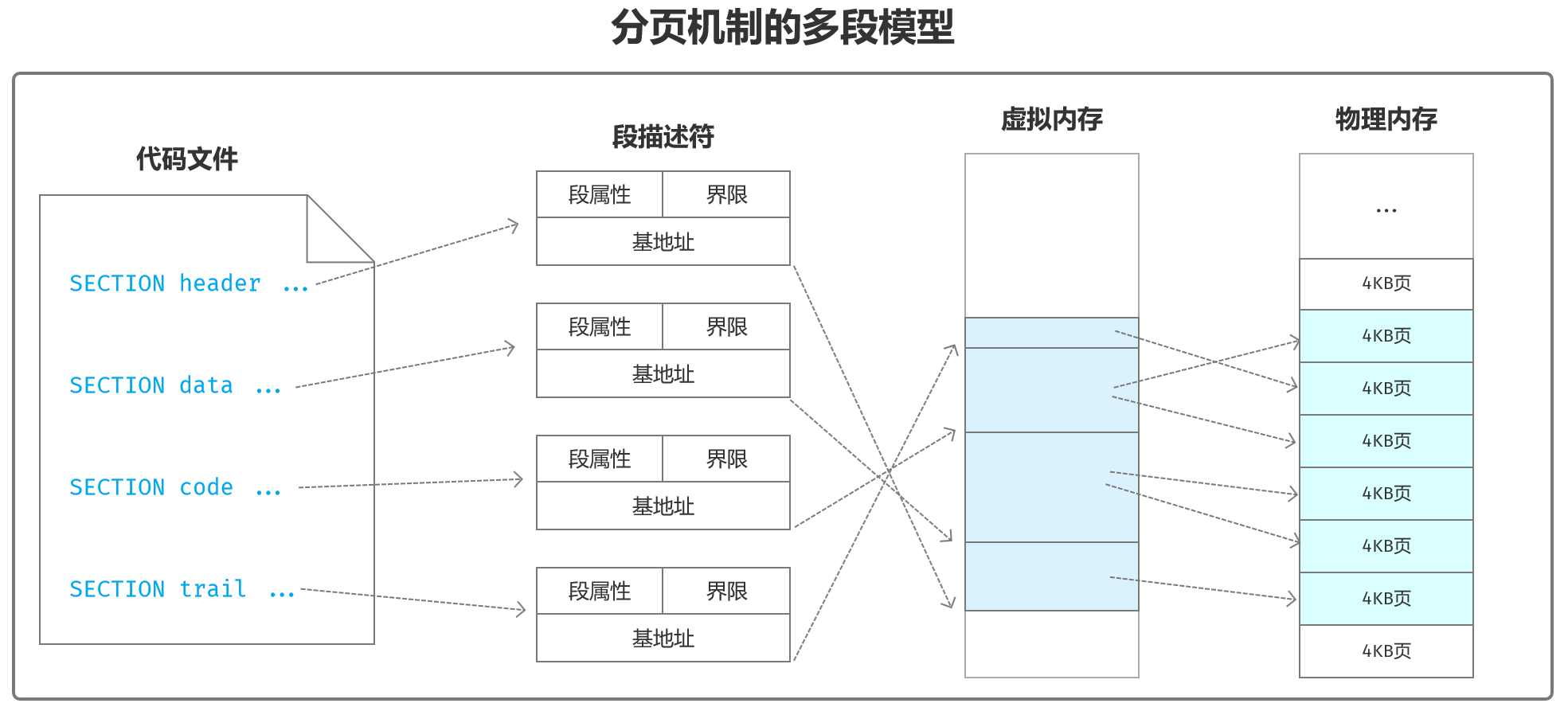
为什么又分段又分页没有必要?
- 32位和64位处理器拥有完整的地址线,不需要分段就可以访问全部内存;
- 分段加重了内存管理的负担;
- 物理页有自己的属性,也可以进行特权级管理并执行换入换出等调度工作。
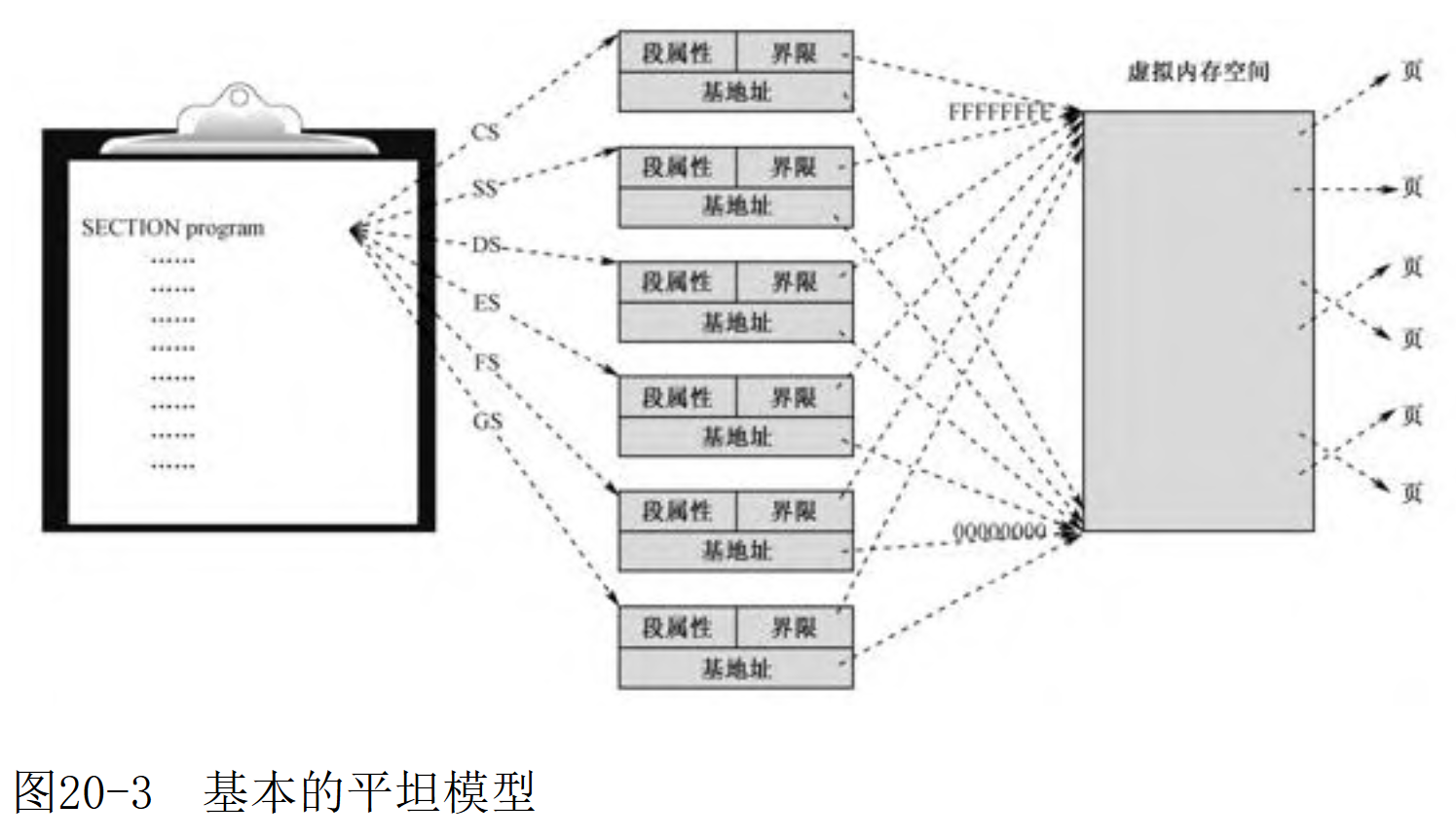
平坦模型
平坦模型(Flat Model):不分段的内存管理模型称为平坦模型(Flat Model)。
所谓的平坦模型,就是将全部4GB内存整体上作为一个大段来处理,而不是分成小的区块。在这种模型下,所有段都是4GB,每个段的描述符都指向4GB的段,段的基地址都是0x00000000,段界限都是0xFFFFF,粒度为4KB。
本章的代码清单
该章节的代码实现的功能和上一章差不多,就是创建内核任务、用户任务1和用户任务2这三个任务,然后在这个三个任务之间进行切换。
初始化系统并加载内核
段初始化:我们将DS和SS设置为0,主引导程序在数据段内的起始偏移量是0x7c00。如此访问段内标号时,可以直接将标号作为段内偏移量来使用。
SECTION mbr vstart=0x00007c00 ;数据段的起始地址是0x7c00
xor ax, ax ;ax <- 0
mov ds, ax
mov ss, ax
mov sp, 0x7c00 ;栈的偏移也从0x7c00开始
定义平坦模型下的段描述符
计算GDT的逻辑段地址:主引导程序执行时是实地址模式,使用逻辑地址,所以需要先将GDT的32位物理地址转换成逻辑地址。
;计算GDT所在的逻辑段地址
mov eax, [pgdt + 0x02] ;GDT的32位物理地址
xor edx, edx
mov ebx, 16 ;除以16,即右移4位
div ebx ;分解成16位逻辑地址,eax保存商、edx保存余数
mov ds,eax ;令DS指向该段以进行操作
mov ebx,edx ;段内起始偏移地址
创建并安装段描述符:创建全局描述符表GDT并安装必要的段描述符。
;跳过0#号描述符的槽位
;创建1#描述符,保护模式下的代码段描述符,特权级为0
mov dword [ebx+0x08], 0x0000ffff ;基地址为0,界限0xFFFFF,DPL=00
mov dword [ebx+0x0c], 0x00cf9800 ;4KB粒度,代码段描述符,向上扩展
;创建2#描述符,保护模式下的数据段和堆栈段描述符,特权级为0
mov dword [ebx+0x10], 0x0000ffff ;基地址为0,界限0xFFFFF,DPL=00
mov dword [ebx+0x14], 0x00cf9200 ;4KB粒度,数据段描述符,向上扩展
;创建3#描述符,保护模式下的代码段描述符,特权级为3
mov dword [ebx+0x18], 0x0000ffff ;基地址为0,界限0xFFFFF,DPL=11
mov dword [ebx+0x1c], 0x00cff800 ;4KB粒度,代码段描述符,向上扩展
;创建4#描述符,保护模式下的数据段和堆栈段描述符,特权级为3
mov dword [ebx+0x20], 0x0000ffff ;基地址为0,界限0xFFFFF,DPL=11
mov dword [ebx+0x24], 0x00cff200 ;4KB粒度,代码段描述符,向上扩展
加载全局描述符表寄存器GDTR:创建和安装描述符之后,我们加载全局描述符表寄存器GDTR,进入保护模式。
;初始化描述符表寄存器GDTR
mov word [cs: pgdt],39 ;描述符表的界限
lgdt [cs: pgdt]
in al,0x92 ;南桥芯片内的端口
or al,0000_0010B
out 0x92,al ;打开A20
cli ;中断机制尚未工作
mov eax,cr0
or eax,1
mov cr0,eax ;设置PE位
;以下进入保护模式... ...
jmp dword 0x0008:flush ;16位的描述符选择子:32位偏移
[bits 32]
flush: ;标号flush处的物理地址是0x7c8c。
......
为什么标号flush处的物理地址是0x7c8c?
因为段的起始地址是0x7c00,flush的汇编地址是0x008c,所以物理地址就是0x7c00+0x008c = 0x7c8c。
创建DS等描述符:用新创建的数据段描述符刷新DS、ES、FS、GS和SS。
flush:
mov eax,0x00010 ;加载数据段(4GB)选择子
mov ds,eax
mov es,eax
mov fs,eax
mov gs,eax
mov ss,eax ;加载堆栈段(4GB)选择子
mov esp,0x7c00 ;堆栈指针
;选择子0x00010含义:
; 二进制为:0000 0000 0000 0001 0000
; 索引为2,对应2号描述符
对应的2#描述符,设置是向上扩展的, 为什么栈段会向下?
平坦模型下的内核程序
定义段描述符的选择子常量:
;以下常量定义部分。内核的大部分内容都应当固定
flat_core_code_seg_sel equ 0x0008 ;平坦模型下的内核(0特权级)4GB代码段选择子
;二进制为0000 0000 0000 1000,对应1#号描述符,RPL为0
flat_core_data_seg_sel equ 0x0010 ;平坦模型下的内核(0特权级)4GB数据段选择子
;二进制为0000 0000 0001 0000,对应2#号描述符,RPL为0
flat_user_code_seg_sel equ 0x001b ;平坦模型下的用户(3特权级)4GB代码段选择子
;二进制为0000 0000 0001 1011,对应3#号描述符,RPL为3
flat_user_data_seg_sel equ 0x0023 ;平坦模型下的用户(3特权级)4GB数据段选择子
;二进制为0000 0000 0010 0011,对应4#号描述符,RPL为3
定义其他常量:定义中断描述符表的高端起始线性地址、内核地址空间可用于分配的高端起始线性地址,以及内核任务的TCB的高端线性地址。
idt_linear_address equ 0x8001f000 ;中断描述符表的线性地址
core_lin_alloc_at equ 0x80100000 ;内核中可用于分配的起始线性地址
core_lin_tcb_addr equ 0x8001f800 ;内核任务TCB的高端线性地址
只要一个段:内核程序是运行在平坦模型下的,原则上不需要分段,或者只分一个段即可。另外为了通过段组织的方式对代码进行管理,可以通过vfollows这个关键词。
1)定义header段:header段从0x80040000地址开始。
;以下是系统核心的头部,用于加载核心程序
SECTION header vstart=0x80040000 ;header段从0x80040000开始
core_length dd core_end ;核心程序总长度#00
core_entry dd start ;核心代码段入口点#
;内核加载的地址是0x00004000,开启分页后映射到0x80040000。
2)其他段申明从上个段继续:
SECTION sys_routine vfollows=header ;系统公共例程代码段
...
SECTION core_data vfollows=sys_routine ;系统核心的数据段
...
SECTION core_code vfollows=core_data ;系统核心代码段
3)最后一个段不用:最后一个段不用,因为core_end要表示内核程序的总字节数。
SECTION core_tail
core_end:
4)一个段的好处:因为所有段都是4GB的,让段寄存器CS指向4GB的代码段,让DS、ES、FS和SS都指向4GB的数据段,从此之后,再也不用管分段的事情,也不再需要让它们一会儿指向这个段,一会儿指向那个段,所有段寄存器都指向当前任务的全部内存空间。
5)内核的一些改动:由于只分一个段,它们的地址都是连续的,对这些例程的调用不再是直接绝对远调用,而是采用相对近调用,每个例程也不再用retf远返回,而是用ret返回。
例如调用创建描述符的例程:
call make_seg_descriptor ;近调用,不用段前缀了
;之前都是用 call sys_routine_seg_sel:make_seg_descriptor
加载内核程序
加载内核:先读取内核程序头部,判断内核程序的大小,再将它全部读入。
;以下加载系统核心程序
mov edi,core_base_address
mov eax,core_start_sector
mov ebx,edi ;起始地址
call read_hard_disk_0 ;以下读取程序的起始部分(一个扇区)
;以下判断整个程序有多大
mov eax,[edi] ;核心程序尺寸
xor edx,edx
mov ecx,512 ;512字节每扇区
div ecx
or edx,edx
jnz @1 ;未除尽,因此结果比实际扇区数少1
dec eax ;已经读了一个扇区,扇区总数减1
@1:
or eax,eax ;考虑实际长度≤512个字节的情况
jz pge ;EAX=0 ?
;读取剩余的扇区
mov ecx,eax ;32位模式下的LOOP使用ECX
mov eax,core_start_sector
inc eax ;从下一个逻辑扇区接着读
@2:
call read_hard_disk_0
inc eax
loop @2 ;循环读,直到读完整个内核
内核程序头部:
;以下是系统核心的头部,用于加载核心程序
SECTION header vstart=0x80040000
core_length dd core_end ;核心程序总长度#00
core_entry dd start ;核心代码段入口点#04
准备分页:加载内核之后准备分页。
1)创建内核的页目录表:首先,我们创建内核的页目录表,并初始化必要的目录项。页目录表的基址是0x00020000。
;创建系统内核的页目录表PDT
mov ebx,0x00020000 ;页目录表PDT的物理地址
;在页目录内创建指向页目录表自己的目录项,最后一个页目录表项。
mov dword [ebx+4092],0x00020003 ;最后一项4092~4095
mov edx,0x00021003 ;MBR空间有限,后面尽量不使用立即数
;在页目录内创建与线性地址0x00000000对应的目录项,第一个页目录表项。
mov [ebx+0x000],edx ;写入目录项(页表的物理地址和属性)
;此目录项仅用于过渡。
;在页目录内创建于线性地址0x80000000对应的目录项,第513个页目录表项。
mov [ebx+0x800],edx ;写入目录项(页表的物理地址和属性)
2)创建内核的页表:接着创建页表。页表的物理地址是0x00021000,它的前256个页表项必须一一对应于物理内存最低端的256个页,这是内核能正常工作的基本要求。
;创建与上面那个目录项相对应的页表,初始化页表项
mov ebx,0x00021000 ;页表的物理地址
xor eax,eax ;起始页的物理地址,0x0000
xor esi,esi ;记录循环次数,从0开始
.b1:
mov edx,eax ;
or edx,0x00000003 ;页目录表项值初始化,页属性最后两位为11,表示在内存中存在,可读可写
mov [ebx+esi*4],edx ;登记页的物理地址
add eax,0x1000 ;下一个相邻页的物理地址
inc esi
cmp esi,256 ;仅低端1MB内存对应的页才是有效的
jl .b1
3)设置CR3寄存器:将内核页目录表的物理地址传送到控制寄存器CR3,这是在开启页功能之前必须要做的事情。
;令CR3寄存器指向页目录,并正式开启页功能
mov eax,0x00020000 ;PCD=PWT=0
mov cr3,eax
4)GDT映射到虚拟内存的高端:全局描述符表(GDT)映射到虚拟内存的高端。这也是一一映射的,GDT的新地址应当是线性地址0x80000000加上它原先的地址。
;将GDT的线性地址映射到从0x80000000开始的相同位置
sgdt [pgdt]
;mov ebx,[pgdt+2]
add dword [pgdt+2],0x80000000 ;GDTR也用的是线性地址
lgdt [pgdt]
开启分页:正式开启分页功能。
mov eax,cr0
or eax,0x80000000
mov cr0,eax ;开启分页机制,就是CR0寄存器高位置为1
内核栈指针映射到虚拟内存的高端:内核栈,应当将它映射到虚拟内存的高端。
;将堆栈映射到高端,这是非常容易被忽略的一件事。应当把内核的所有东西
;都移到高端,否则,一定会和正在加载的用户任务局部空间里的内容冲突,
;而且很难想到问题会出在这里。
add esp,0x80000000
这个应该是可以是放到前面和 GDT映射到虚拟内存的高端 这个步骤一起做。
转移到内核:内核加载后,就可以跳转到内核进行执行了。
jmp [0x80040004] ;就是内核的entry入口点。
这是一个32位间接绝对近转移,而不是远转移(段间转移),在指令中没有使用关键“far”。
这条指令有两个功能:
- 一是转移到内核去执行;
- 二是将处理器的执行流转移到虚拟内存的高端。
内核已经从硬盘上加载了,加载的位置是线性地址0x80040000。内核程序有一个头部,记载了内核的大小和入口点。在内核程序内,偏移为0x00000004的地方,记载着内核要执行的第一条指令的偏移量,但没有段选择子。
当这条jmp指令执行时,处理器要先访问DS所指向的4GB数据段,从线性地址0x80040004处取得一个32位的段内偏移量,传送到寄存器EIP。内核就开始执行了。
内核的初始化
进入内核并初始化中断系统
打印一个信息:说明要开始设置中断系统和系统调用了。
;创建中断描述符表IDT
mov ebx, message_0
call put_string
put_string优化:中断系统初始化完成之前是不能调用例程put_string的。在多任务系统中,为了防止多个任务同时在屏幕上输出文本,进入这个例程时,会用cli指令关闭中断,而在退出这个例程之前再用sti指令开放中断。在内核初始化阶段,由于中断系统尚未准备就绪,开放中断将导致严重问题。
;字符串显示例程(适用于平坦内存模型)
put_string: ;显示0终止的字符串并移动光标
;输入:EBX=字符串的线性地址
push ebx
push ecx
pushfd ;保留原先的标识
cli ;硬件操作期间,关中断
.getc:
mov cl,[ebx]
or cl,cl ;检测串结束标志(0)
jz .exit ;显示完毕,返回
call put_char
inc ebx
jmp .getc
.exit:
popfd ;硬件操作完毕,恢复原先中断状态
pop ecx
pop ebx
ret
优化点:
- 通过pushfd保存原先的EFLAGS的状态;
- 然后cli关闭中断;
- 最后通过popfd再还原,而不是直接开启中断(sti)。
初始化中断系统:初始化中断系统,创建中断描述符表IDT,并安装对应于20个异常和236个普通中断的中断门。中断描述符表的安装位置是物理地址0x1f000,位于低端1MB之内。
1)安装前20个:前20个向量是处理器异常使用的。
;前20个向量是处理器异常使用的
mov eax,general_exception_handler ;门代码在段内偏移地址
mov bx,flat_core_code_seg_sel ;门代码所在段的选择子
mov cx,0x8e00 ;32位中断门,0特权级
call make_gate_descriptor ;平坦模型下使用近调用
mov ebx,idt_linear_address ;中断描述符表的线性地址
xor esi,esi
.idt0:
mov [ebx+esi*8],eax
mov [ebx+esi*8+4],edx
inc esi
cmp esi,19 ;安装前20个异常中断处理过程
jle .idt0
2)安装其余236个:
;其余为保留或硬件使用的中断向量
mov eax,general_interrupt_handler ;门代码在段内偏移地址
mov bx,flat_core_code_seg_sel ;门代码所在段的选择子
mov cx,0x8e00 ;32位中断门,0特权级
call make_gate_descriptor ;edx:eax 保存高低各32位地址
mov ebx,idt_linear_address ;中断描述符表的线性地址
.idt1:
mov [ebx+esi*8],eax
mov [ebx+esi*8+4],edx
inc esi
cmp esi,255 ;安装普通的中断处理过程
jle .idt1
3)设置实时时钟中断处理过程:设置0x70中断,用 rtm_0x70_interrupt_handle 这个例程处理。
;设置实时时钟中断处理过程
mov eax,rtm_0x70_interrupt_handle ;门代码在段内偏移地址
mov bx,flat_core_code_seg_sel ;门代码所在段的选择子
mov cx,0x8e00 ;32位中断门,0特权级
call make_gate_descriptor
mov ebx,idt_linear_address ;中断描述符表的线性地址
mov [ebx+0x70*8],eax ;中断向量:0x70
mov [ebx+0x70*8+4],edx
4)设置系统调用中断的处理过程:设置0x88中断,用int_0x88_handler例程处理
;设置系统调用中断的处理过程
mov eax,int_0x88_handler ;门代码在段内偏移地址
mov bx,flat_core_code_seg_sel ;门代码所在段的选择子
mov cx,0xee00 ;32位中断门,3特权级!!!!!!
call make_gate_descriptor ;edx:eax 保存高低各32位地址
mov ebx,idt_linear_address ;中断描述符表的线性地址
mov [ebx+0x88*8],eax ;中断向量:0x88
mov [ebx+0x88*8+4],edx
设置中断描述符表寄存器IDTR:
;准备开放中断
mov word [pidt],256*8-1 ;IDT的界限
mov dword [pidt+2],idt_linear_address
lidt [pidt] ;加载中断描述符表寄存器IDTR
软中断和系统调用
软中断:所谓软中断,就是用int指令引发的中断。软中断指令包括
int n
into
int3
int1
示例程序:
int 0x88
操作系统通常会提供大量的系统服务,不可能为每个系统服务都使用单独的中断向量。实际上,操作系统只使用一个中断向量号,但是会要求应用程序通过某个寄存器(比如EAX)来指定具体的系统服务功能。
书中测试88号中断:
;测试系统调用
mov ebx,message_1
mov eax, 0 ;通过系统调用的0号功能显示信息
int 0x88 ;尽管TSS尚未准备好,但不会切换栈
88号中断功能:
int_0x88_handler: ;系统调用处理过程
call [eax * 4 + sys_call] ;每个例程的偏移地址占用4个字节
iretd
sys_call功能:
;系统调用功能入口
sys_call dd put_string ;0号功能
dd read_hard_disk_0 ;1号功能
dd put_hex_dword ;2号功能
dd terminate_current_task ;3号功能
dd initiate_task_switch ;4号功能
dd allocate_memory ;5号功能
系统调用的安装及其工作原理
系统调用中断门特权级:硬件中断可以在任何时候发生,并转去执行中断处理过程。换句话说,对硬件中断的处理不受当前特权级的影响。但是,每一个int n、into和int3指令在执行时,如果当前特权级CPL在数值上大于从IDT中选择的那个门描述符的DPL,则将产生一般保护异常#GP。
简单的说,应用程序特权级小于中断门描述符的特权级。中断门描述符特权级设置为3,表示应用程序都可以调用。
代码实现:cx属性为0xee00,表示DPL为3。
;设置系统调用中断的处理过程
mov eax,int_0x88_handler ;门代码在段内偏移地址
mov bx,flat_core_code_seg_sel ;门代码所在段的选择子
mov cx,0xee00 ;32位中断门,3特权级!!!!!!
call make_gate_descriptor ;edx:eax 保存高低各32位地址
mov ebx,idt_linear_address ;中断描述符表的线性地址
mov [ebx+0x88*8],eax ;中断向量:0x88
mov [ebx+0x88*8+4],edx
;0xee00分析
; 二进制位:1110 1110 0000 0000
; 对应下图的红色框的位置,容易看出DPL为3

加载中断描述符表寄存器IDTR:
;准备开放中断
mov word [pidt],256*8-1 ;IDT的界限
mov dword [pidt+2],idt_linear_address
lidt [pidt] ;加载中断描述符表寄存器IDTR
测试系统调用:
;测试系统调用
mov ebx,message_1
mov eax, 0 ;通过系统调用的0号功能显示信息
int 0x88 ;尽管TSS尚未准备好,但不会切换栈
系统调用是通过向量号为0x88的软中断进入的,我们知道,中断处理时,要离开当前正在执行的程序,转入中断处理程序执行。在这个过程中,如果改变了当前特权级,则必须切换栈,毕竟栈的特权级在任何时候都必须和当前特权级保持一致,这是一个硬性规定。栈切换时,是从任务状态段TSS中选取一个对应的栈段选择子和栈指针,但我们现在并没有初始化TSS。不过没有关系,现在我们正在内核中执行,当前特权级为0,目标代码段的DPL也是0,不会切换栈。
int_0x88_handler: ;系统调用处理过程
call [eax * 4 + sys_call]
iretd
把这些例程的入口地址组织起来,形成一个表格,再用功能号作为索引来找到它对应的例程的入口地址。
;系统调用功能入口
sys_call dd put_string
dd read_hard_disk_0
dd put_hex_dword
dd terminate_current_task
dd initiate_task_switch
dd allocate_memory
在平坦模型下,它们的汇编地址实际上也是它们的线性地址,可直接作为4GB段内的偏移量来用。
相关例程的改动:因为采用了平坦模型,段的基地址始终都为0,所以只需要传入在4GB中的线性地址即可。又因为开启了分页,低端1MB物理内存被映射到了高端,所以相关的线性地址需要转换为高端线性地址。
例如:显存的物理地址是0x000b80000,实际传入的线性地址就是 0x800b8000。
任务状态段TSS的新用法
TSS的功能:TSS的功能主要包括以下几个方面。
- 任务在任务切换时,保存当前任务的状态(寄存器的内容),从新任务的TSS中恢复新任务的状态及LDT;
- 在当前任务内实施特权级之间的转移(从用户态进入内核态)时,需要切换栈。处理器从当前任务的TSS中选取对应的栈段选择子和栈指针,完成栈切换;
- 处理器用TSS的I/O许可位图控制当前任务的I/O访问权限。
只用一个TSS:只使用一个TSS,第一,节省空间;第二,任务切换时不需要重新加载任务寄存器TR,节省时间。因为是使用软件切换,可以使用TCB来存储任务切换时的信息,切换时将旧任务的状态保存到它自己的TCB中,并从新任务的TCB中恢复它的状态。
下图为TCB的结构:

切换方式:每个任务在执行时,都可能会因中断或者通过调用门实施特权级之间的控制转移,从用户态进入内核态,而且必须切换栈。
由于在整个系统中只有一个TSS,在从旧任务切换到新任务时,
- TSS中的SS0、SS1、SS2、ESP0、ESP1和ESP2都应当由新任务负责替换和更新;
- TSS中的LDT选择子也应当由新任务负责替换和更新;
- TSS中的I/O许可位图部分也应当在任务切换时由新任务加以修改。
TSS格式参考下图:
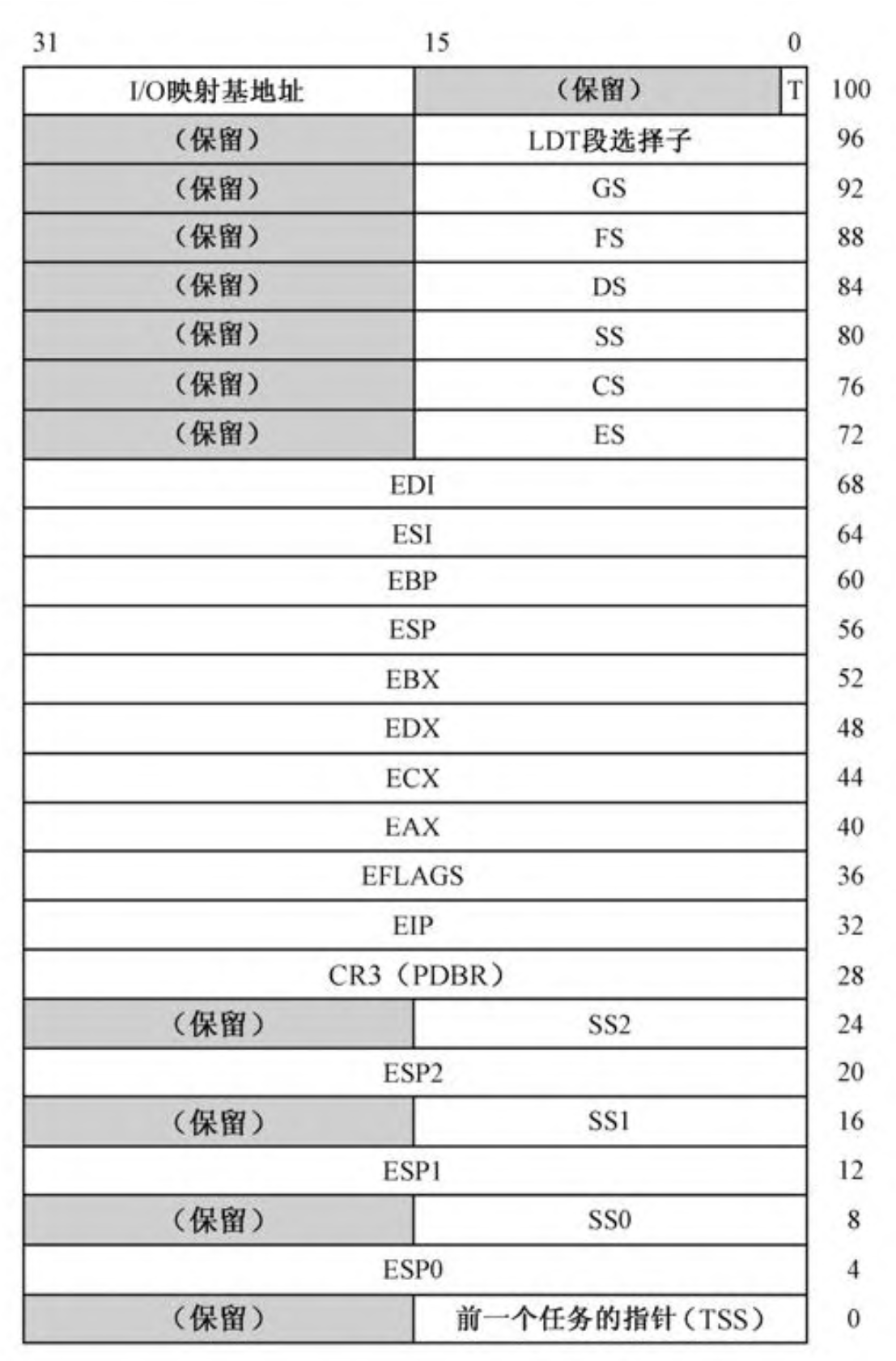
TSS实现:只使用一个TSS,也就不需要动态分配内存,而是直接在标号tss这里开辟了一段空间。
tss times 128 db 0 ;任务状态段
创建任务状态段TSS的描述符,并清空:
;创建任务状态段TSS的描述符。整个系统实际上只需要一个TSS即可。
mov ecx, 32
xor ebx, ebx
.clear:
mov dword [tss + ebx], 0 ;TSS的多数字段已经不用,全部清空。
add ebx, 4
loop .clear
因为系统只用0和3特权级,所以只需要将SS0设置成一个固定的、RPL字段为0的、指向4GB数据段的选择子即可。
;因特权级之间的转移而发生栈切换时,本系统只会发生3到0的切换。因此,
;只需要TSS中设置SS0,且必须是0特权级的栈段选择子。
mov word [tss + 8], flat_core_data_seg_sel
设置TSS的界限:设置TSS的界限为103,该字单元的内容大于或者等于TSS的段界限,表明没有IO许可位图。
mov word [tss + 102], 103 ;没有I/O许可位图部分
创建TSS描述符并安装在GDT中:
;创建TSS描述符,并安装到GDT中
mov eax,tss ;TSS的起始线性地址
mov ebx,103 ;段长度(界限)
mov ecx,0x00008900 ;TSS描述符,特权级0
call make_seg_descriptor
call set_up_gdt_descriptor
寄存器TR指向TSS:
;令任务寄存器TR指向唯一的TSS并不再改变。
ltr cx
显示一条信息,表示TSS已经创建完成:
mov ebx,message_2
call put_string
;message_2定义
; message_2 db 'TSS is created.', 0x0d, 0x0a, 0
创建内核任务:内核任务虽然是一个独立的任务,但与内核是绑定在一起的,占据着所有其他任务的全局部分。
;开始创建和确立内核任务
mov ecx, core_lin_tcb_addr ;移至高端之后的内核任务TCB线性地址
mov word [ecx + 4], 0xffff ;任务的状态为“忙”
mov dword [ecx + 6], core_lin_alloc_at ;登记内核中可用于分配的起始线性地址
call append_to_tcb_link ;将内核任务的TCB添加到TCB链中
;现在可认为“程序管理器”任务正执行中
mov ebx,core_msg1
call put_string
用户任务的创建
创建用户任务TCB:
;以下开始创建用户任务
mov ecx, 128 ;为TCB分配内存
call allocate_memory ;任务控制块TCB是由内核使
用的,所以它必须在全局空间分配。
mov word [ecx+0x04],0 ;任务状态:就绪
mov dword [ecx+0x06],0 ;任务内可用于分配的初始线性地址
因为采用了平坦模型,其中的allocate_memory及其调用的几个例程都得到简化:
- 例程allocate_memory本身是使用4GB的段来访问链表的节点的,所以不需要切换或者加载段寄存器,例程得以简化;
- 这个例程调用了task_alloc_memory,例程task_alloc_memory也不需要切换和加载段寄存器,也得到了简化;
- 这个例程调用了alloc_inst_a_page,例程alloc_inst_a_page又调用了allocate_a_4k_page,它们都不需要切换或者加载段寄存器,也得到了简化,
载入用户任务:
push dword 50 ;用户程序位于逻辑50扇区
push ecx ;压入任务控制块起始线性地址
call load_relocate_program
call append_to_tcb_link ;将此TCB添加到TCB链中
用户任务的创建工作依然是用例程load_relocate_program来完成的,但是这个例程在平坦模型下已经大幅度简化。
平坦模型下的用户程序结构
用户程序是通过例程load_relocate_program进行加载。
push dword 50 ;用户程序位于逻辑50扇区
push ecx ;压入任务控制块起始线性地址
call load_relocate_program
call append_to_tcb_link ;将此TCB添加到TCB链中
用户程序组成:从代码文件中可以看出是分段的,但只是形式上的,起到代码分隔和组织的作用。
头部段:头部段从0开始,表示从自己的虚拟内存空间分配内存,线性地址从0开始。
SECTION header vstart=0 ;从自己的虚拟内存空间分配内存,线性地址从0开始
代码段:段内使用了vfollows属性表示延续上一个段。
SECTION code vfollows=data
尾部段:最后一个段的定义中没有任何子句,那么,段内标号program_end的汇编地址是它相对于程序开头的偏移量。
;-------------------------------------------------------------------------------
SECTION trail
;-------------------------------------------------------------------------------
program_end:
因为在本章中采用系统调用而不是调用门,所以取消了符号地址检索表。
用户任务的创建过程
不用创建TSS:前面已经分析过为什么只用一个TSS了。
不用创建LDT:平坦模型下不再为程序分段,不用再为每个任务创建独立的段描述符,所以就不用LDT了。
创建用户任务栈:由于我们的系统只支持两个特权级别:0和3,用户任务至少需要两个栈空间,一是它固有的栈,即,3特权级的栈;另一个是0特权级的栈,因中断或者调用门从3特权级的用户态进入0特权级的内核态时,切换到这个栈。
用户任务的栈不是在程序编写时指定的(在用户程序中没有定义栈段),所以,这个栈需要动态创建。
;为用户任务分配栈空间
mov ebx,esi ;TCB的线性地址
mov ecx,4096 ;4KB的空间
call task_alloc_memory
mov ecx, [esi + 6] ;下一次分配的起始线性地址就是栈顶指针
mov dword [esi + 70], ecx
图示如下:

创建中断门和调用门的0特权级栈空间:再用相同的方法创建用于中断和调用门的0特权级栈空间。
;创建用于中断和调用门的0特权级栈空间
mov ebx,esi
mov ecx,4096 ;4KB的空间
call task_alloc_memory
mov ecx, [esi + 6] ;下一次分配的起始线性地址就是栈顶指针
mov dword [esi + 10], ecx ;TCB的ESP0域
创建用户任务页目录:例程create_copy_cur_pdir返回为用户任务分配的页目录表的物理地址,这个地址需要保存到用户任务的TCB中,即,TCB中偏移为22的CR3域。
;创建用户任务的页目录
;注意!页的分配和使用是由页位图决定的,可以不占用线性地址空间
call create_copy_cur_pdir
mov [esi + 22], eax ;填写TCB的CR3(PDBR)域
补充填写TCB其余部分:最后,补充填写TCB中的相关部分。
mov word [esi + 30], flat_user_code_seg_sel ;TCB的CS域
mov word [esi + 32], flat_user_data_seg_sel ;TCB的SS域
mov word [esi + 34], flat_user_data_seg_sel ;TCB的DS域
mov word [esi + 36], flat_user_data_seg_sel ;TCB的ES域
mov word [esi + 38], flat_user_data_seg_sel ;TCB的FS域
mov word [esi + 40], flat_user_data_seg_sel ;TCB的GS域
mov eax, [0x04] ;从任务的4GB地址空间获取入口点
mov [esi + 26], eax ;填写TCB的EIP域
pushfd ;采用出入栈的方式填写TCB的EFLAGS域
pop dword [esi + 74] ;填写TCB的EFLAGS域
mov word [esi + 4], 0 ;任务状态:就绪
软件任务切换
用户任务加入到TCB链:从例程load_relocate_program返回之后,第一个任务就创建完成了,不过它还不能参与任务切换,毕竟它的TCB还未添加到TCB链表中。调用例程append_to_tcb_link将任务控制块TCB加入TCB链表中。此时,任务链表中已经有两个任务了,任务切换随时会发生。
call append_to_tcb_link ;将此TCB添加到TCB链中
任务切换:任务切换是实时时钟中断处理过程的一部分,每秒一次的更新周期结束中断发生时,将执行例程rtm_0x70_interrupt_handle。
rtm_0x70_interrupt_handle: ;实时时钟中断处理过程
push eax
mov al, 0x20 ;中断结束命令EOI
out 0xa0, al ;向8259A从片发送
out 0x20, al ;向8259A主片发送
mov al, 0x0c ;寄存器C的索引。且开放NMI
out 0x70, al
in al, 0x71 ;读一下RTC的寄存器C,否则只发生一次中断
;此处不考虑闹钟和周期性中断的情况
call initiate_task_switch ;发起任务切换
pop eax
iretd
initiate_task_switch:例程initiate_task_switch用来主动发起任务切换。
保存当前任务的状态
保存当前任务的状态到其TCB中:
;保存旧任务的状态
mov eax, cr3
mov [esi + 22], eax ;保存CR3
;EAX/EBX/ESI/EDI不用保存,在任务恢复执行时将自动从栈中弹出并恢复
mov [esi + 50], ecx
mov [esi + 54], edx
mov [esi + 66], ebp
mov [esi + 70], esp
mov dword [esi + 26], .return ;恢复执行时的EIP
mov [esi + 30], cs
mov [esi + 32], ss
mov [esi + 34], ds
mov [esi + 36], es
mov [esi + 38], fs
mov [esi + 40], gs
pushfd
pop dword [esi + 74]
指令指针寄存器EIP未保存。原因很简单,任务切换是在中断处理过程内进行的,将来这个任务恢复执行时,还原点依然在这个中断处理过程内,并通过“中断返回”回到中断前的地方。为此,第581行,TCB中的EIP域实际上保存的是标号.return的汇编地址。
jmp resume_task_execute ;转去恢复并执行新任务
.return: ;返回后从这里开始执行
pop edi
pop esi
pop ebx
pop eax
ret
书中提到一个问题:在这里,标号.return代表的汇编地址实际上也是一个线性地址,为什么?
因为整个内核程序是一个段,并且段开始的地址就是从线性地址0x80040000开始的。
;以下是系统核心的头部,用于加载核心程序
SECTION header vstart=0x80040000
不光是.return标号,像start标号都是类似的。
恢复并执行新任务
resume_task_execute:在保存了当前任务的状态后,通过例程resume_task_execute恢复并执行新任务。
jmp resume_task_execute ;转去恢复并执行新任务
;例程的输入:EDI=新任务的TCB的线性地址
设置TSS的ESP0域:从新任务的TCB中取出0特级栈指针,并写入TSS的ESP0域。
mov eax, [edi + 10]
mov [tss + 4], eax ;用新任务的ESP0设置TSS的ESP0域
恢复新任务的CR3:从新任务的TCB中取出页目录表指针,传送到CR3,如此一来就恢复并切换到新任务的地址空间了。
mov eax, [edi + 22]
mov cr3, eax ;恢复新任务的CR3
恢复段寄存器和通用寄存器:从新任务的TCB中恢复除CS、SS、EIP、EDI和ESP外的段寄存器和通用寄存器:
mov ds, [edi + 34]
mov es, [edi + 36]
mov fs, [edi + 38]
mov gs, [edi + 40]
mov eax, [edi + 42]
mov ebx, [edi + 46]
mov ecx, [edi + 50]
mov edx, [edi + 54]
mov esi, [edi + 58]
mov ebp, [edi + 66]
- 没有恢复EDI的原因是它正在用于内存访问,需要延后恢复;
- 没有恢复SS和ESP的原因是这样做有可能导致异常:栈段的特权级必须与当前特权级CPL一致,这是硬性要求。任务切换是在内核中进行的,此时此刻特权级为0,但是从TCB中取出的栈段选择子的RPL字段可能为3,与当前特权级不符,不能贸然向段寄存器SS加载。
- 没有恢复CS和EIP:它们是不能或者无法直接修改的,只能用jmp、call、iret、ret等指令间接修改。
没有恢复SS和ESP详解:但是问题来了,既然任务切换在内核中进行,当前特权级CPL必然为0,栈段的特权级必须和当前特权级一致,也必然为0。这就是说,任务切换时,保存在TCB中的栈段选择子的RPL必然为0;反过来说,从TCB中恢复的栈段选择子的RPL当然也为0——怎么可能与当前特权级不符呢?
任务切换时,如果从TCB中恢复的内容来自上次任务切换时所保存的内容,那当然是一致的。但是,如果新任务从来没有执行过,这是新任务的第一次执行,即,从TCB中恢复的内容来自该任务创建时指定的内容,当前特权级CPL就和TCB中的栈段选择子的RPL不一致了。
载入用户任务时设置的SS,从load_relocate_program例程中可以看到:
mov word [esi + 32], flat_user_data_seg_sel ;TCB的SS域
;flat_user_data_seg_sel的定义DPL是3。
flat_user_data_seg_sel equ 0x0023 ;平坦模型下的用户(3特权级)4GB数据段选择子
切换时保存的旧(当前)任务的SS,从initiate_task_switch例程中可以看到:
mov [esi + 32], ss ;保存的时候当前的栈段,当前是在内核运行,栈段的DPL一定是0
没有恢复CS和EIP详解:它们是不能或者无法直接修改的,只能用jmp、call、iret、ret等指令间接修改。
书中例子通过iretd进行返回,需要在栈中构造一个iretd指令需要的栈帧,从而模拟一个中断返回。
处理器执行iretd指令时,将用栈中的CS的RPL字段与当前特权级CPL比较:
- 如果一致,说明当初未切换栈,只从栈中弹出并恢复EIP、CS和EFLAGS即可。SS和ESP就要自己恢复。
- 如果不一致,则说明当初切换了栈,除了要从栈中弹出并恢复EIP、CS和EFLAGS,还要从栈中弹出并恢复原先的栈段选择子(这当然会重新加载段描述符到SS的描述符高速缓存器)和栈指针。
1)检测TCB中的SS域:对于即将恢复执行的新任务,要检测其TCB中的SS域,主要是测试其最低两个比特(RPL部分)是否同时为1,所以test指令的源操作数是立即数3。
- 特权级为3:如果有特权级有变化,需要压入要恢复的任务的栈段和栈指针,后续执行iretd指令的时候,处理器会从依次栈中弹出并恢复EIP、CS和EFLAGS、栈段选择子和栈指针;
- 特权级位0:没有变化,那么直接恢复esp和ss即可。
test word [edi + 32], 3 ;SS.RPL=3?
jnz .to_r3 ;是的。转.to_r3
mov esp, [edi + 70] ;特权级也为0,新任务的栈指针和栈段选择子
mov ss, [edi + 32]
jmp .do_sw
.to_r3: ;特权级有变化,需要模拟切换过程压入栈段和栈指针
push dword [edi + 32] ;SS,压入原先的栈段选择子和栈指针
push dword [edi + 70] ;ESP
2)压入EFLAGS、CS和IP:
.do_sw:
push dword [edi + 74] ;EFLAGS
push dword [edi + 30] ;CS
push dword [edi + 26] ;EIP
3)修改任务的状态为忙:
not word [edi + 0x04] ;将就绪状态的节点改为忙状态的节点
mov edi, [edi + 62]
4)返回:
iretd
内核任务的执行
创建更多用户任务:一旦将第一个用户任务的TCB加入TCB链表,任务链表中就有了两个任务,任务切换随时就会发生了。一会切换到用户任务,一会切换到内核任务,切换到内核任务时,内核都会接着往下执行,内核接着是创建更多的任务。
;可以创建更多的任务,例如:
mov ecx,128 ;为TCB分配内存
call allocate_memory
mov word [ecx+0x04],0 ;任务状态:空闲
mov dword [ecx+0x06],0 ;任务内可用于分配的初始线性地址
push dword 100 ;用户程序位于逻辑100扇区
push ecx ;压入任务控制块起始线性地址
call load_relocate_program
call append_to_tcb_link ;将此TCB添加到TCB链中
第二个用户任务创建完成后,将有三个任务在切换和执行。
用户任务的执行
用户程序结构:代码形式上有分段,但是加载后实际上是只有一个段。
SECTION header vstart=0 ;线性地址从0开始
SECTION data vfollows=header ;从header结尾线性地址继续
SECTION code vfollows=data ;从data结尾线性地址继续
SECTION trail ;结尾不加vfollows,program_end表示程序长度
program_end:
演示分页:用户程序很短小,通过保留20KB的空白区域演示分页。
reserved times 4096*5 db 0 ;保留一个空白区,以演示分页
开始执行:用户程序第一次执行时,从入口点start进入。
申请内存:首先申请128个字节的内存,使用88号中断的5号功能。
;在当前任务内的虚拟地址空间里分配内存
mov eax, 5
mov ecx, 128 ;请求分配128个字节
int 0x88 ;执行系统调用
mov ebx, ecx ;ecx分配的内存起始线性地址,为后面打印字符串准备参数
复制字符串:复制字符串到分配的内存中。
;复制字符串到分配的内存中
mov esi, message_1 ;esi字符串的起始地址
mov edi, ecx ;edi字符串要复制到的目标地址,此处为上面申请的内存空间起始线性地址
mov ecx, reserved-message_1 ;ecx要复制的次数
cld ;调整方向,从低地址到高地址
repe movsb ;批量复制
打印字符串:使用88号中断打印复制后的字符串。
.show:
mov eax, 0 ;0号功能是打印字符串,参数ebx是起始的字符串线性地址。
int 0x88
jmp .show
第二个用户任务执行:直接调用88号中断打印一个消息,没有申请内存了。前面第一个用户程序只是为了演示内存申请使用的调用。
start:
mov eax, 0
mov ebx, message_1
int 0x88
jmp start
用户任务的终止:前面的两个用户任务因为使用了循环,自身是无法终止的。可以使用系统调用的3号功能terminate_current_task进行终止。
terminate_current_task: ;终止当前任务
;注意,执行此例程时,当前任务仍在
;运行中。此例程其实也是当前任务的
;一部分
mov edi, [tcb_chain]
;EAX=首节点的线性地址
;搜索状态为忙(当前任务)的节点
.s0:
cmp word [edi + 4], 0xffff
jz .s1 ;找到忙的节点,EAX=节点的线性地址
mov edi, [edi]
jmp .s0
;将状态为忙的节点改成终止状态
.s1:
mov word [edi + 4], 0x3333
;搜索就绪状态的任务
mov edi, [tcb_chain] ;EBX=链表首节点线性地址
.s2:
cmp word [edi + 4], 0x0000
jz .s3 ;已找到就绪节点,EBX=节点的线性地址
mov edi, [edi]
jmp .s2
;就绪任务的节点已经找到,准备切换到该任务
.s3:
jmp resume_task_execute ;转去恢复并执行新任务
完。



















 1196
1196

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











