







2D Proposal Based Sequential Models
该类检测方法主要分为两个阶段:一个是候选框生成阶段(RPN阶段),一个是候选框的精修阶段(RCNN阶段)。
在RPN阶段中,该类方法通常会借用已有的2D检测器在给定的图片上生成相应的候选框。然后再基于一阶段生成的候选框检索得到相应的种子区域,并通过对种子区域的特征提取完成后续阶段的refine.
通常情况下,将2D语义信息与3D几何信息结合的方式有2种:
一种是将2D检测框投影到3D空间,产生相应的frustum,并以frustum为种子区域来进行后续阶段的refine;
另一种方式则是将3D点云投影到2D图片中,将2D图片上相应区域或者像素点的特征附着到点云中来辅助网络产生更高质量的候选框。
基于2D proposal来辅助3D检测的方式有以下几类方法:
- result-level guided methods
该类方法侧重于利用现成的2D检测或者分割框架,获取关于整个场景下的前景点的先验,以进一步缩小整个点云场景的搜索空间。
以2D检测结果作为先验
下面介绍一个典型的代表性工作F-PointNet:
F-PointNet先是通过2D检测器生成相应的proposal,然后将生成的proposal投影到3D空间中得到frustum。对于frustum内部的点,F-PointNet设计了一个特定的实例分割网络,并对每个点进行了二分类(也即判断哪些点是前景点,哪些点是背景点)。最后再基于前景点的特征,通过PointNet来回归每个frustum对应的bbox.。

同期的文章[]也采用了类似的思想:其先是通过2D检测器在2D图像上生成了一系列的proposals,然后再将proposal投影到3D空间中得到对应的sub-region,并通过RANSAC算法以及model fitting算法来进一步生成和筛选3D proposals. 最后再根据预测的proposal内部的点,使用2D CNN来作置信度的预测和检测框的回归。
上述方法存在以下几个方面的不足:
- 很容易受到2D特征提取器的表达能力的限制
- 基于2D图片来获取前景点的方式很容易受到遮挡等因素的影响
- 上述方式假设每个视锥内只存在一个物体,这样的假设使得模型对拥挤场景或者小物体的检测结果不是很好
以2D分割的结果作为先验
与前面提到的基于2D检测器的融合框架不同的是,IPOD[]是直接基于3D点云来生成proposal的。具体而言,其先是通过2D分割网络对整个场景的点云作了二分类,得到了一定数量的种子点,很大程度上减少了网络的搜索空间。接下来模型则基于种子点生成相应数量的proposal,并通过PointNet++来提取proposal内每个点的语义信息。以及最后再基于点的语义信息和位置信息来生成每个proposal的特征,以用于检测框的回归和置信度的预测。
下图为整个网络的pipeline:

下图为proposal feature的生成过程
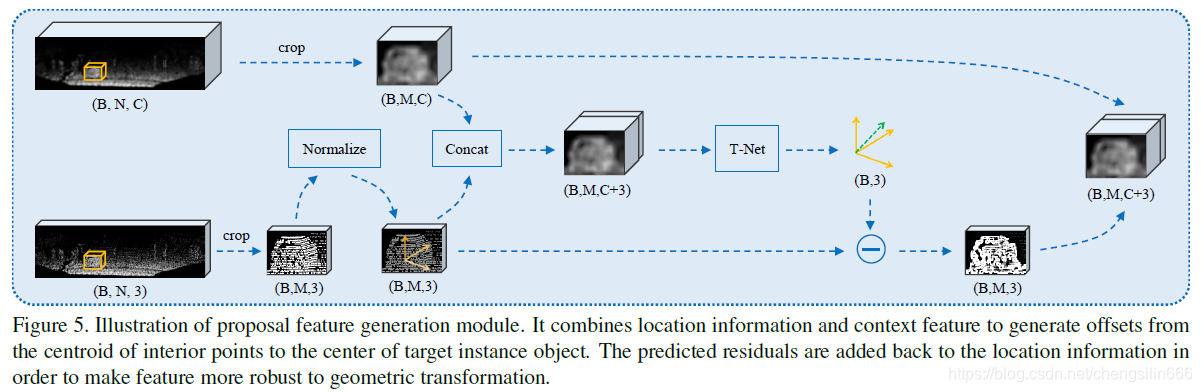
-
Proposal-level based Fusion
一个典型的代表方法就是PointFusion[]。PointFusion先通过2D检测器生成一系列的proposal,然后再基于PointNet和ResNet分别对Proposal对应的点云和图片区域进行特征提取,最后提出了Desne-Fusion以及Global-Fusion两种方式来融合两个不同模态的特征。

该方法的一个创新之处就在于该方法引入了proposal级别的特征融合方式,但该方法很容易受到2D检测器性能的限制。 -
Point-level based Fusion
下面介绍两个相关工作,一个是PI-RCNN,另一个则是PointPainting。
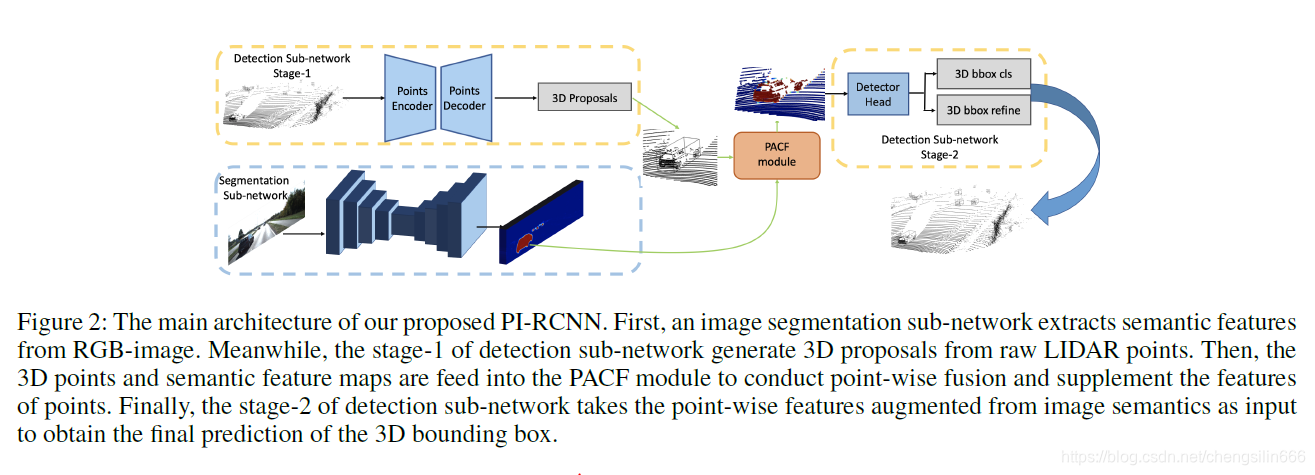
PI-RCNN引入了2个子网络来进行3D检测。其中一个子网络为基于点云的两阶段检测器PointRCNN,另外一个子网络则是2D语义分割网络。作者先是利用2D语义分割网络得到每个pixel的feature,与此同时PointRCNN一阶段也会输出一系列的proposal。接下来,我们将进一步融合proposal内每个点和对应图片像素之间的特征,作为每个proposal的特征,输入到PointRCNN的第二阶段用于refine。
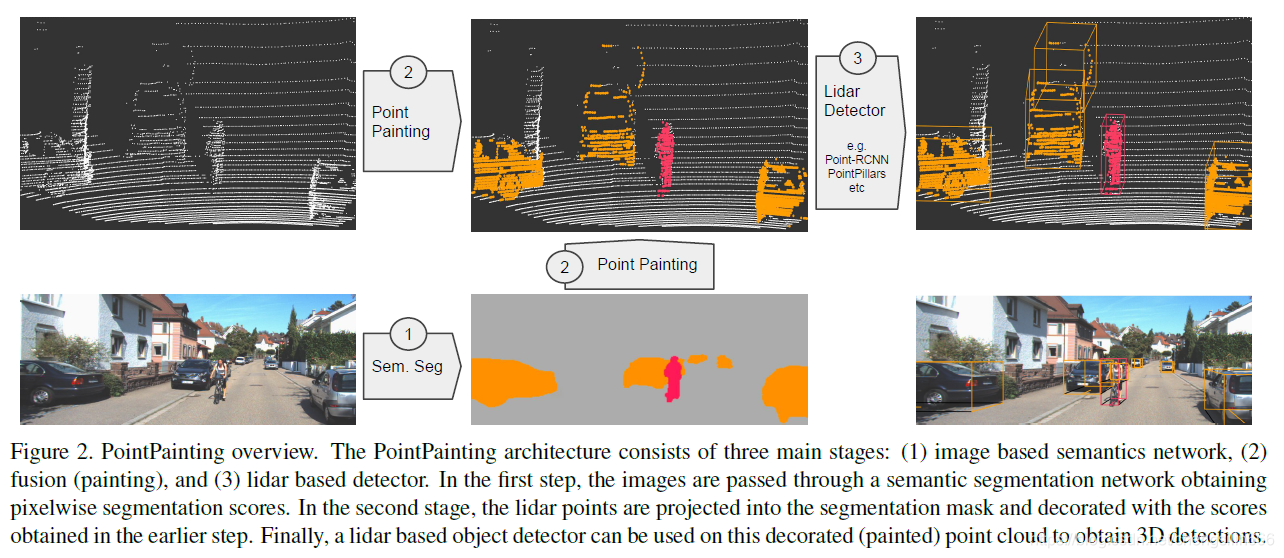
PointPainting则更为简洁——其直接将图片语义分割得到的特征和点云特征拼接起来作为3D检测器的输入,其Pipeline如下图。

















 2171
2171

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









