






 文章探讨了如何使用diffusionmode生成高精度的合成图像,如FreeMask方法,以增强模型的泛化能力。通过检测合成像素的损失,FreeMask确保只有那些对模型学习有显著贡献的区域被用于训练。同时,DiffuLT关注于让扩散模型在长尾识别任务中发挥效用。
文章探讨了如何使用diffusionmode生成高精度的合成图像,如FreeMask方法,以增强模型的泛化能力。通过检测合成像素的损失,FreeMask确保只有那些对模型学习有显著贡献的区域被用于训练。同时,DiffuLT关注于让扩散模型在长尾识别任务中发挥效用。
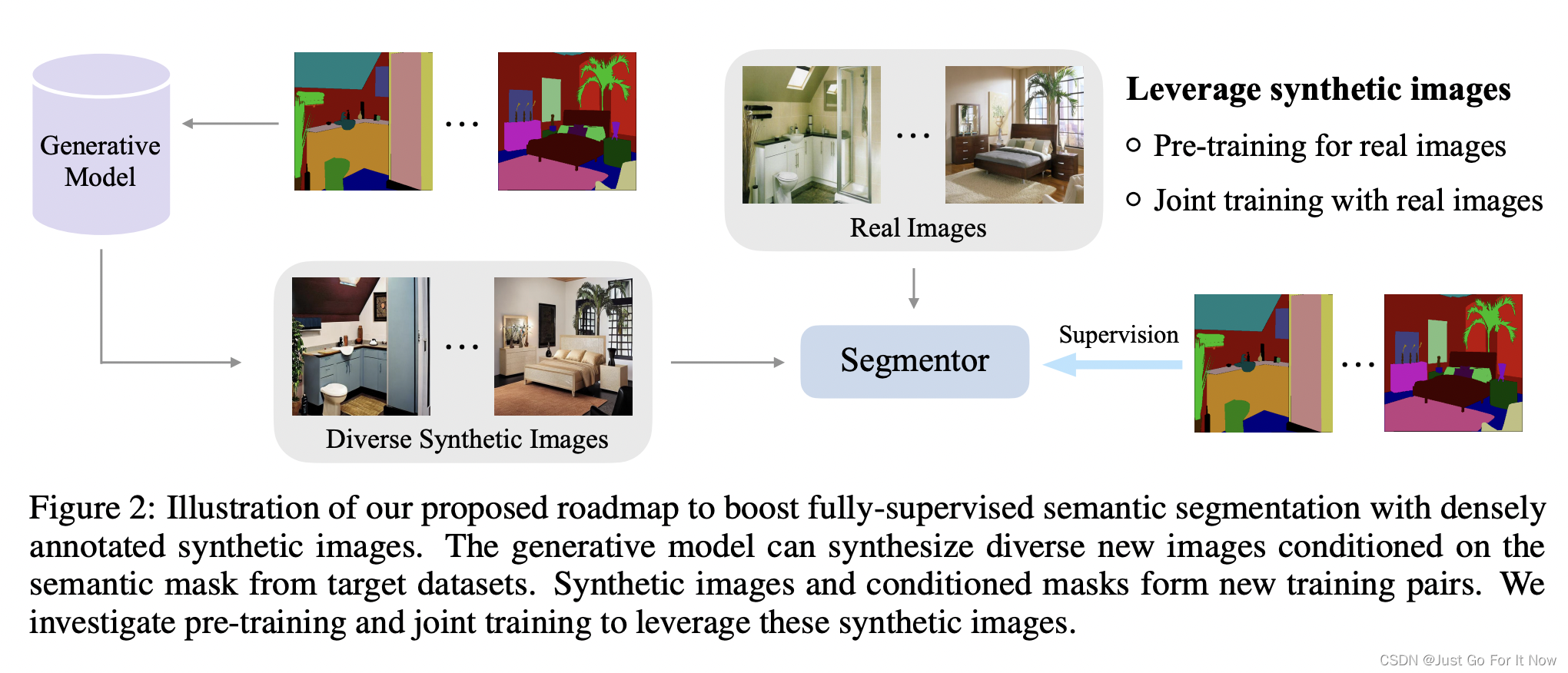
使用diffusion mode生成synthetic images,用于enhance traning data:
1. FreeMask: Synthetic Images with Dense Annotations Make Stronger Segmentation Models (NurIPS 2024)
Challenges:
- Generating in-domain images
- Generating high-quality images
- Generating hard samples to improve model generalization ability
How to solve the challeges:
- FreestyleNet, which can generate high-fedility images conditioned on semantic masks
- Incorrectly synthesized regions or images will exhibit significant losses, if evaluated under a model pre-trained on real images ---- > if the loss of a synthetic pixel surpasses the average loss of its corresponding class by a certain margin, it will be marked as a noisy pixel and ignored during loss computation
- with recorded class-wise average losses, it can calculate the overall loss of a semantic mask, which can represent its global hardness. It will generate more samples for those hard semantic masks and otherwise the opposite
短语:“It is even on par with”


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









