




 本文介绍了在神经网络中,如何使用简单模型的梯度计算和反向传播算法来处理复杂的计算图,特别是通过PyTorch中的Tensor实现前馈过程和反向传播。文章通过实例演示了如何计算梯度并更新权重,以及如何在实际场景中运用这些概念进行模型训练。
本文介绍了在神经网络中,如何使用简单模型的梯度计算和反向传播算法来处理复杂的计算图,特别是通过PyTorch中的Tensor实现前馈过程和反向传播。文章通过实例演示了如何计算梯度并更新权重,以及如何在实际场景中运用这些概念进行模型训练。
目录
回顾
简单模型的梯度计算
最简单的线性模型可以简化为y=wx,x是输入,w是参数,是模型需要计算出来的,y是预测值,*可以看成网络中的计算。

其实这就可以是一个简单的神经元模型。w需要不断更新:计算损失函数loss对w的导数
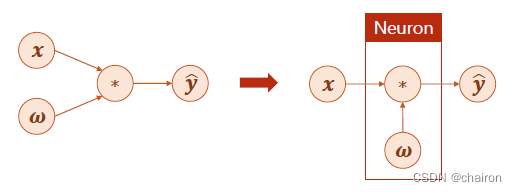

那么对于复杂的神经网络该怎么样进行梯度计算,进行参数的更新呢?
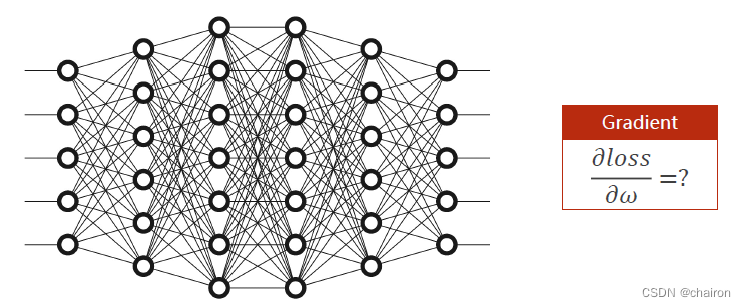
分析:假设输入x1~x5,经过多层神经元最后得到y1-y5。每个神经元都有一个权重w需要计算,如何计算损失函数对每一个输入的微分呢?
如果按照之前的梯度下降,根据链式求导法则,那么需要计算的微分公式非常长,计算非常复杂。
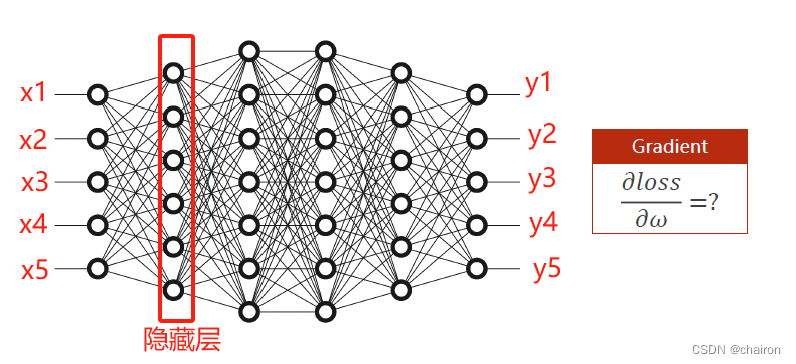
那么有没有一种方式能够比较方便的计算这种复杂的神经网络的梯度呢?
反向传播!
反向传播
计算图

一个神经元:输入X和权重W先进行矩阵乘法,再进行矩阵加法。(所有输入、输出、参数都是向量或者矩阵)
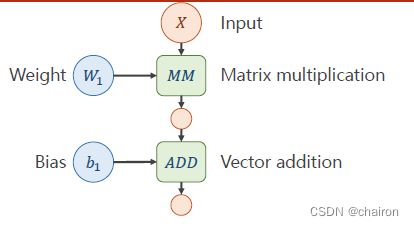
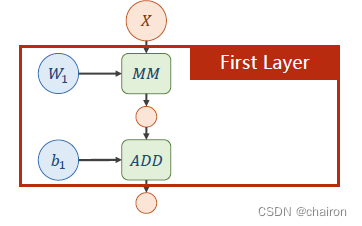
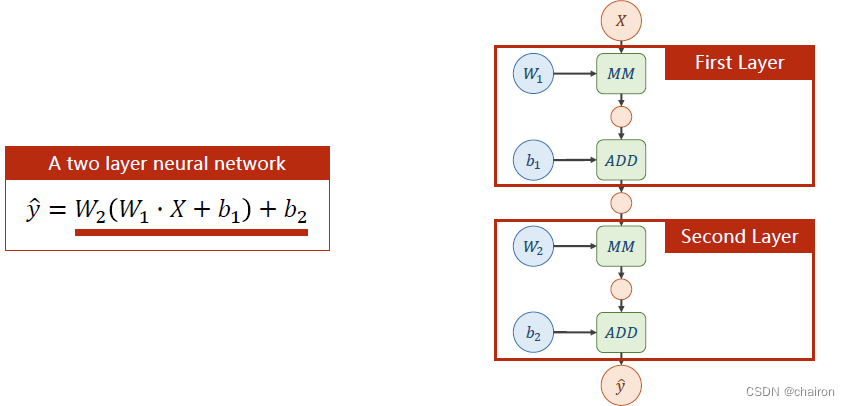
图中绿色部分表示运算:
MM:矩阵乘法,ADD:加法。
两种运算的求导方法不一样哟!
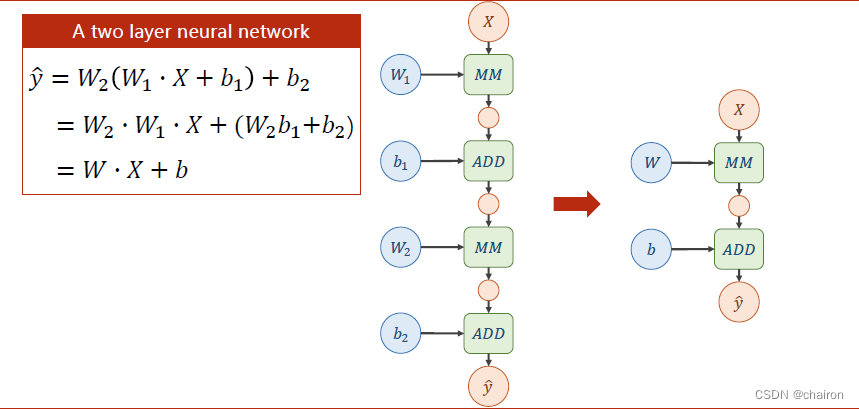
对这两层神经元计算公式进行展开,我们会发现:不管有多少层神经元,最终都可以表示成一个形式: W X + B WX+B WX+B。这个计算式是可以展开的,这样计算量是完全没有变化的!
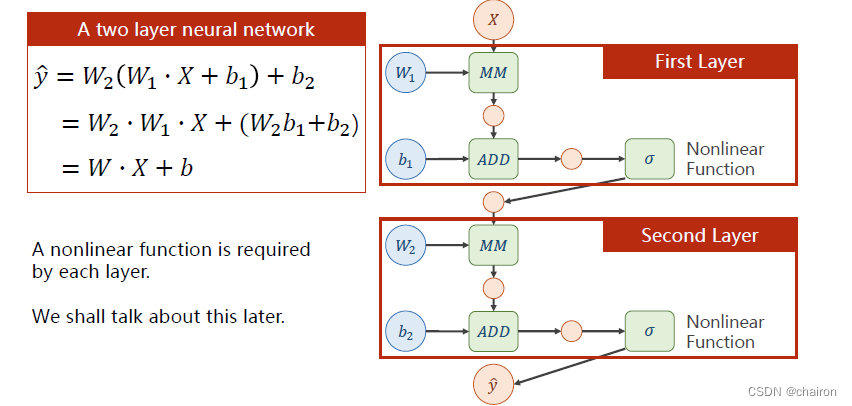
于是!我们可以在每层神经元之后加一个非线性激活函数!比如说Sigmoid函数,这样函数就没法再展开了。
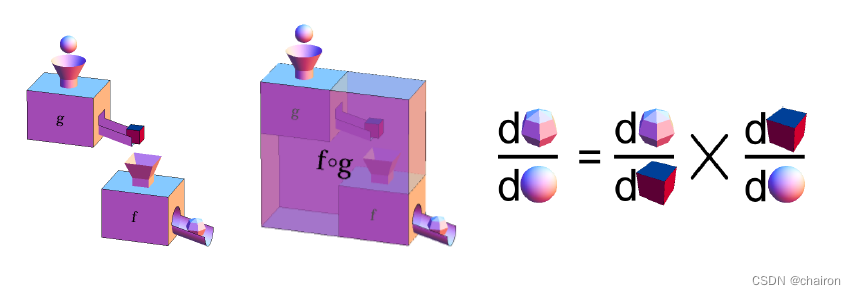
链式求导
链式法则定理:
假如 y = f (u)是一个u的可微函数,u = g (x)是一个x 的可微函数,则 y = f (g(x)) 是一个x 的可微函数,并且:
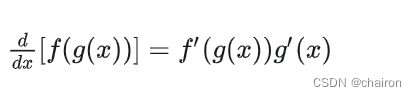
即y 对x 的导数,等于y 对u 的导数,乘以u 对x 的导数。
或者,写成等价形式:
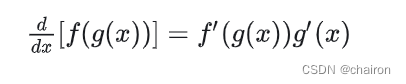
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2346
2346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









