




 R-CNN是一种目标检测方法,通过SelectiveSearch获取候选区域,使用CNN提取特征并用SVM分类。预训练在ImageNet上的CNN模型进行微调,提升特征表示能力。NMS去除重复检测,边界框回归提高定位准确性。实验表明,微调和全连接层对性能提升显著。
R-CNN是一种目标检测方法,通过SelectiveSearch获取候选区域,使用CNN提取特征并用SVM分类。预训练在ImageNet上的CNN模型进行微调,提升特征表示能力。NMS去除重复检测,边界框回归提高定位准确性。实验表明,微调和全连接层对性能提升显著。
R-CNN论文详解
文章目录
1.创新点
- R-CNN采用Selective Search算法预先提取出可能包含目标的 Region Proposal(候选区域),替代传统算法(DPM等)的滑动窗口法,提高速度。
- 使用CNN提取Region Proposal的特征。从经验驱动特征(SIFT、HOG)到数据驱动特征(CNN feature map),提高特征对样本的表示能力。
- 采用大数据集下(ImageNet ILSVC 2012)有监督的预训练和小数据集下(PASCAL VOC 2007)微调(fine-tuning)的方法解决小样本难以训练甚至过拟合等问题
- 运用CNN网络去产生Region Proposal,进行精准定位和切割。
(ground truth:正确的标签)
2 网络结构
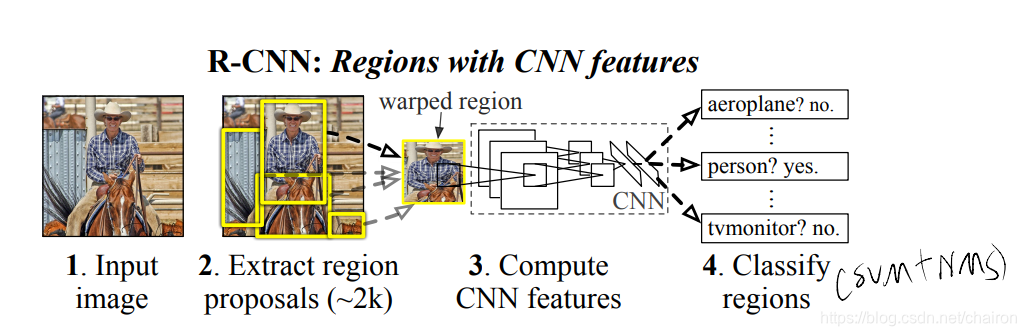
1. 提取Region Proposal:Selective Search的方法提取2000个候选区域
2. 计算CNN特征:对每个Region Proposal进行warped称为227x227,使用CNN网络计算proposal的feature map
3. Classify regions:对每个proposal的feature map进行SVM分类,采用NMS去掉重复的Proposal
4. Bounding box regression:使用回归器产生bbox,精准定位
3 Compute CNN features
3.1 Extract region proposal
使用Selective Search算法从输入图像中提取2000个Region Proposal
Selective Search算法主要步骤:
1. 使用一种过分割手段,将图像分割成小区域 (1k~2k 个)
2. 计算所有邻近区域之间的相似性,包括颜色、纹理、尺度等
3. 将相似度比较高的区域合并到一起
4. 计算合并区域和临近区域的相似度
5.重复3、4过程,直到整个图片变成一个区域
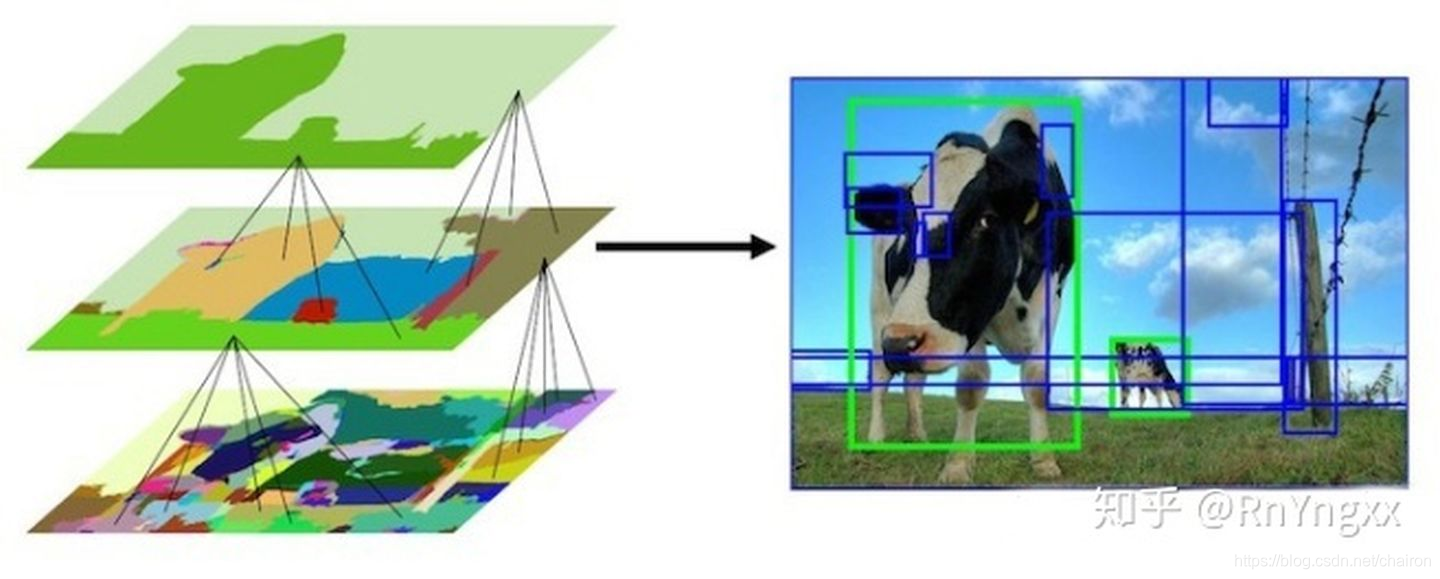
在每次迭代中,形成更大的区域并将其添加到区域提议列表中。这种自下而上的方式可以创建从小到大的不同scale的Region Proposal,如图所示。
3.2 Feature extraction
对每张图片产生2000个Region proposals,从每个Region proposals提取一个4096维的特征向量。
-
由于文中使用的CNN中包含有全连接层,这就需要输入神经网络的图片有相同的size:所以需要对每个Region Proposal都缩放到固定的大小(227*227)。.
-
在变形之前,我们扩张紧边界框,以便在变形尺寸下,原始框周围恰好有 p 个像素的变形图像上下文(我们使用 p = 16)。
-
本文提了两种方法:
1. 不考虑图片的长宽比例,不考虑图片是否扭曲,直接缩放到CNN输入的大小227*227
2. 各向同性缩放:先扩张后裁剪: 直接在原始图片中,把bounding box的边界进行扩展p像素延伸成正方形,然后再进行裁剪。如果已经延伸到了原始图片的外边界,那么就用bounding box中的颜色均值填充。如上图(B)(C)所示。 先裁剪后扩展:先把bounding box图片裁剪出来,然后用固定的背景颜色填充成正方形图片(背景颜色也是采用bounding box的像素颜色均值),如上图(D)所示。
一组试点实验表明,使用上下文填充(p = 16 像素)的变形在很大程度上优于替代方案(3-5 个 mAP 点)
- 特征计算:将减去均值的 227 x227 RGB 图像(wrap)通过五个卷积层和两个完全连接层向前传播来计算的。
- 我们wrap的每个proposal通过 CNN 向前传播它以计算特征。
- 然后,对于每个类,我们使用 SVM 对每个提proposal的特征向量进行评分。
- 给定图像中的所有评分区域,我们用NMS(对于每个类别独立地),删除重复的proposal(如果区域具有交叉联合(IoU)与更高评分的选定区域重叠,则拒绝该区域大于学习阈值)
3.3 Train CNN
利用Selective Search提取Region Proposal并resize后,接下来使用CNN(AlexNet、VGG)从每个Region Proposal提取特征。本文训练CNN的方法,主要包括以下两步:
- Pre-training阶段:由于物体标签训练数据少,本文采用的是有监督的预训练,使用一个大的数据集(ImageNet ILSVC 2012)来训练AlexNet,得到一个分类的预训练(Pre-trained)模型。

- Fine-tuning阶段:使用Region Proposal(PASCAL VOC)对Pre-trained模型进行fine-tuning。
- 首先将原来预训练模型最后的1000-way的全连接层(分类层)换成21-way的分类层(20类物体+背景)
- 然后计算每个region proposal和ground truth 的IoU,对于IoU>0.5的region proposal被视为正样本,否则为负样本(即背景)。
- 在每次迭代的过程中,选取32个正样本和96个负样本(128)组成一个mini-batch(128,正负比:1:3)。我们使用0.001的学习率和SGD来进行训练。

CNN网络似乎学习了一种表示,该表示将少量经过类调整的特征与形状、纹理、颜色和材料属性的分布式表示组合在一起(卷积层),随后的全连接层 fc6 能够对这些丰富特征的大量组合进行建模。
(备注: 如果不针对特定任务进行fine-tuning,而是把CNN当做特征提取器,卷积层所学到的特征其实就是基础的共享特征提取层,就类似于SIFT算法一样,可以用于提取各种图片的特征,而f6、f7所学习到的特征是用于针对特定任务的特征。打个比方:对于人脸性别识别来说,一个CNN模型前面的卷积层所学习到的特征就类似于学习人脸共性特征,然后全连接层所学习的特征就是针对性别分类的特征了)
检测效率的提高:
1. CNN参数共享权重:这种共享的结果是计算region proposal和特征所花费的1时间再所有类别中分摊。
2. CNN提取的特征向量是低维的
3. region proposals 提高定位精确度
3.4 Save features
虽然文中训练了CNN网络对region proposal进行分类,但是实际中,这个CNN的作用只是提取每个region proposal的feature。
因此,我们输入region proposal进行前向传播,然后保存AlexNet的FC7层features,以供后续的SVM分类使用。
4 Classify regions
本文使用SVM进行分类对于每一类都会训练一个SVM分类器,所以共有N(21)个分类器,我们来看一下是如何训练和使用SVM分类器的。
4.1 Training
如下图所示,在训练过程中,SVM的输入包括两部分:
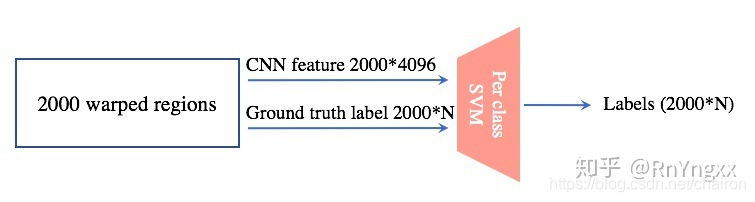
(1) CNN feature:这个便是CNN网络为每个region proposal提取的feature,共2000*4096。
(2) Ground truth labels:在训练时,会为每个region proposal附上一个label(标注好的labels称为Ground truth labels)。
在SVM分类过程中,当IoU<0.3时,为负样本,正样本便是ground truth box。然后SVM分类器也会输出一个预测的labels,然后用labels和ground truth labels计算loss,然后训练SVM。
4.2 Testing
Testing的过程就是输入经过之前的步骤得到test image的Region Proposal的feature,然后输出对2000个proposal的类别预测值。
5 Non-maximum suppression
去掉重复的box
- 经过SVM之后,我们会得到2000个region proposal的class probability,
- 然后我们可以根据‘有无物体’这一类过滤掉一大批region proposal,
- 然后如果某个候选框的最大class probability<阀值,那也可以过滤掉这些region proposal,
- 那剩下的可能如下左图所示,就是有多个box相互重叠,但是我们**目标检测的目标是一个物体有一个box即可,那这个时候就需要用到非极大值抑制(NMS)**了,经过NMS之后,最终的检测结果如下右图所示:

6 Bounding box regression
我们使用一个简单的边界框回归阶段来提高定位性能。
在使用特定于类的检测 SVM 对每个选择性搜索建议进行评分后,我们从 CNN 计算的特征回归,使用特定于类的边界框回归器预测用于检测的新边界框。
6.1 why regression
目标检测问题的衡量标准是重叠面积:许多看似准确的检测结果,往往因为候选框不够准确,重叠面积很小。故需要Bounding box regression步骤。
如下图,绿色的框表示Ground Truth Box, 红色的框为我们预测得到的region proposal 。那么即便红色的框被分类器识别为飞机,但是由于红色的框定位不准(IoU<0.5), 那么这张图相当于没有正确的检测出飞机。所以需要对红色的框进行微调,使得经过微调后的窗口跟Ground Truth Box更接近,这样就可以更准确的定位。Bounding box regression算法参考这里。

6.2 具体实现
6.2.1输入: 一组 N 个训练对: {(Pi , Gi )} i=1,…,N
- 其中 Pi = (Pi x, Pi y, Pi w, Pi h) 指定 proposal Pi 的边界框中心的像素坐标以及 Pi 的宽度和高度(以像素为单位) 。(因此,除非需要,否则我们删除上标 i。)
- 每个真实边界框 G 都以相同的方式指定:G = (Gx, Gy, Gw, Gh)。
- 目标:学习一种将proposal的框 P 映射到真实框 G 的转换
- 过程:
-
我们根据四个函数 dx(.P)、dy(.P)、dw(.P) 和 dh(.P) 来参数化转换。
- dx(.P)、dy(.P):指定 P 边界框中心的尺度不变平移
- dw(.P) 和 dh(.P) :指定 P 边界框宽度和高度的对数空间平移。
-
学习这些函数后,我们可以通过 以下公式将输入proposal P 转换为预测的真q实框 Gˆ
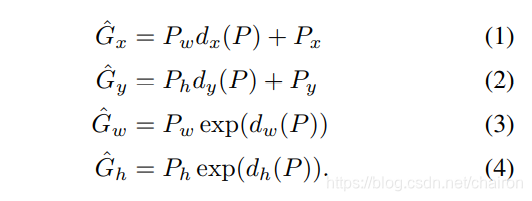
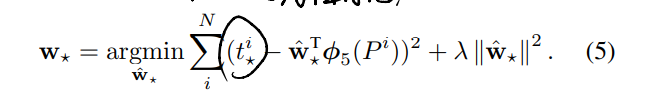
d⋆(.P):为proposal P 的 pool5 特征的线性函数,⽤ φ5 (P ) 表示。 (φ5 (P ) 对图像数据的依赖是隐式假设的。) 因此我们有 d⋆(P) = wT⋆φ5(.P),其中 w⋆ 是可学习模型参数的向量。我们通过优化正则化最⼩⼆乘⽬标(岭回归)来学习 w⋆
-
6.2.2 实现:
回归目标 t对于训练对 (P, G) 被定义为:
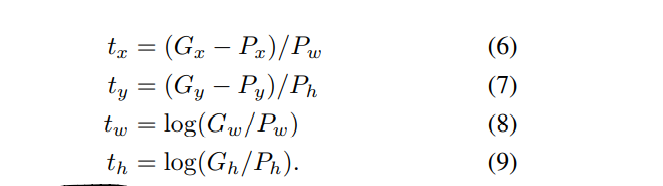
6.3 两个问题:
- 第一:归一化(正则化)很重要:在验证集上设置 【入】为1000
- 第二:在选择要使用的训练对 (P, G) 时必须小心。
- 直觉上,如果 P 远离所有真实框,那么将 P 转换为真实框 G 的任务没有意义。
- 因此,我们只从靠近至少一个真实值框G的proposal P 中学习。
- 靠近:拥有最大IOU,并且当IOU大于阈值(我们使用验证集)的P和G组成一对。所有未分配的提案都将被丢弃。
- 我们对每个对象类都这样做一次,以学习一组特定于类的边界框回归器
在测试时,我们对每个proposal进行评分并仅预测其新的检测窗口一次
一旦提取了特征并应用了训练标签,我们就对每个类优化一个线性 SVM。
由于训练数据太大而无法放入内存,我们采用标准的硬负挖掘方法[17, 37]。
Hard Negative 挖掘快速收敛,并且在实践中 mAP 仅在一次遍历所有图像后停止增加
7 消融实验(微调?fc6、fc7?数据集?)
7.1 微调?fc6、fc7?
-
Performance layer-by-layer, without fine-tuning
不微调,只用预训练的CNN参数进行训练:fc6、fc7可以去掉。说明CNN的能力来自于卷积层,而非全连接层。 -
Performance layer-by-layer, with fine-tuning
进行微调,结果比不微调好,而且:fc6 和 fc7 的微调提升比 pool5 大得多。这表明:从ImageNet(预训练集)上学到的pool5的特征是一般性的,而大多数的提升来自于他们顶部的特域的非线性分类器(全连接层)
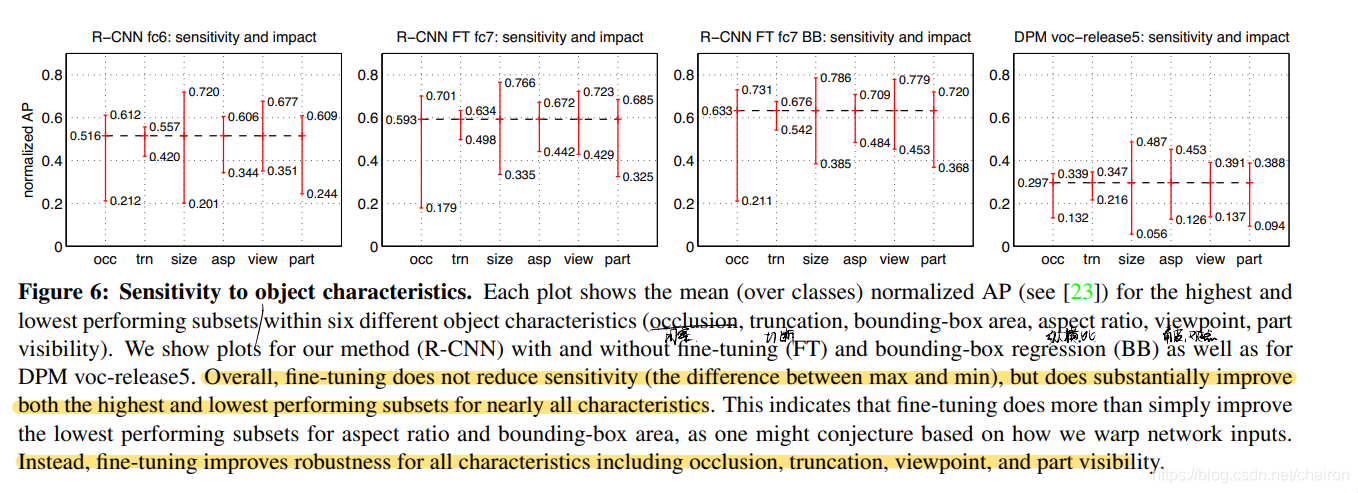
结论:进行微调,需要fc6,fc7
7.2 数据集?
7.2.1 数据集
-
训练集可能有标注可能没有(不彻底);验证集和测试集都有标注。
-
除了这些训练图像集,每个类都有一组额外的负样本图像。
-
训练图像不能用于硬负挖掘,因为注释并不详尽。
-
我们的一般策略是负样本依赖 val 集并使用一些 train images作为正例样本的辅助来源。
-
为了将 val 用于训练和验证,我们将其分成大小大致相同的“val1”和“val2”集。
问: “val1”和“val2”怎么分? 答:有些类别图片可能很少,为了平衡,通过使⽤类别计数作为特征对 val 图像进⾏聚类,然后进⾏随机局部搜索,这可能会改善分割平衡。
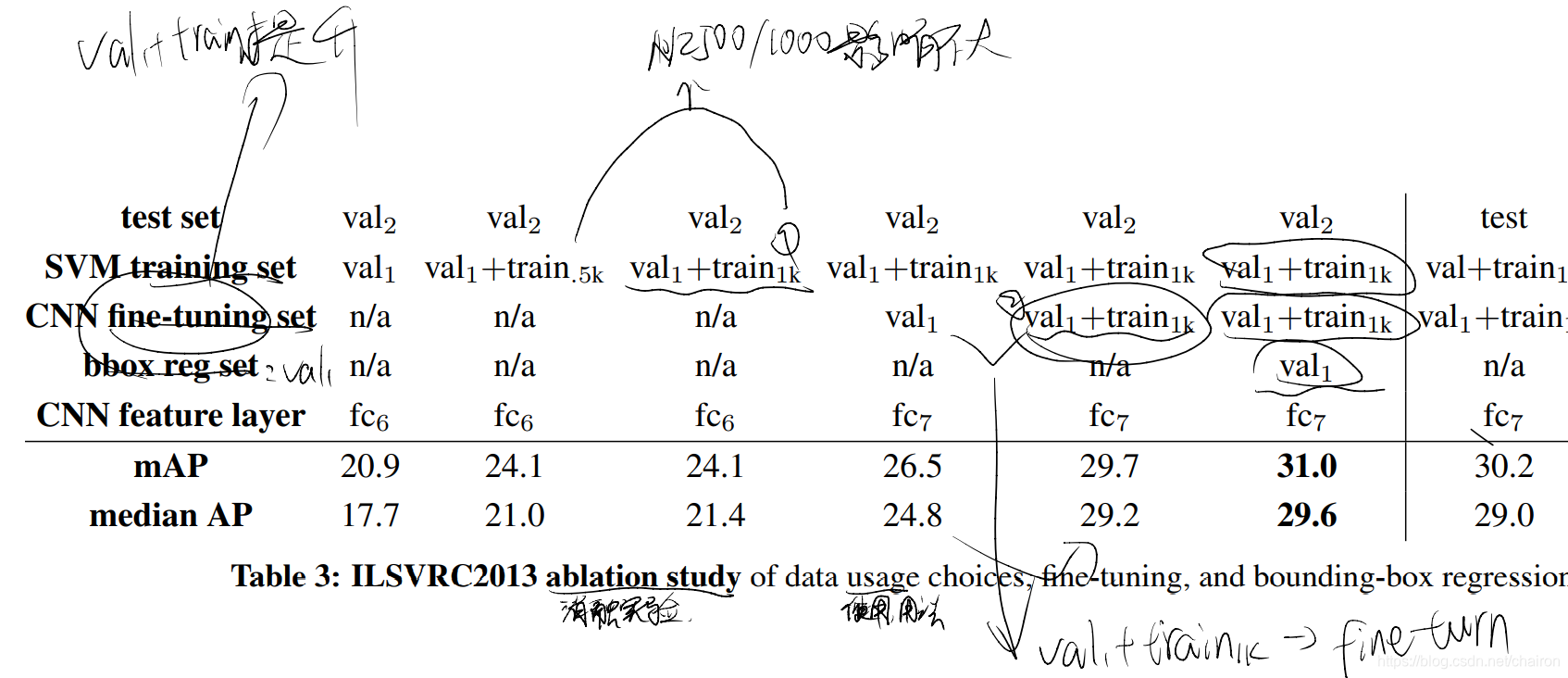
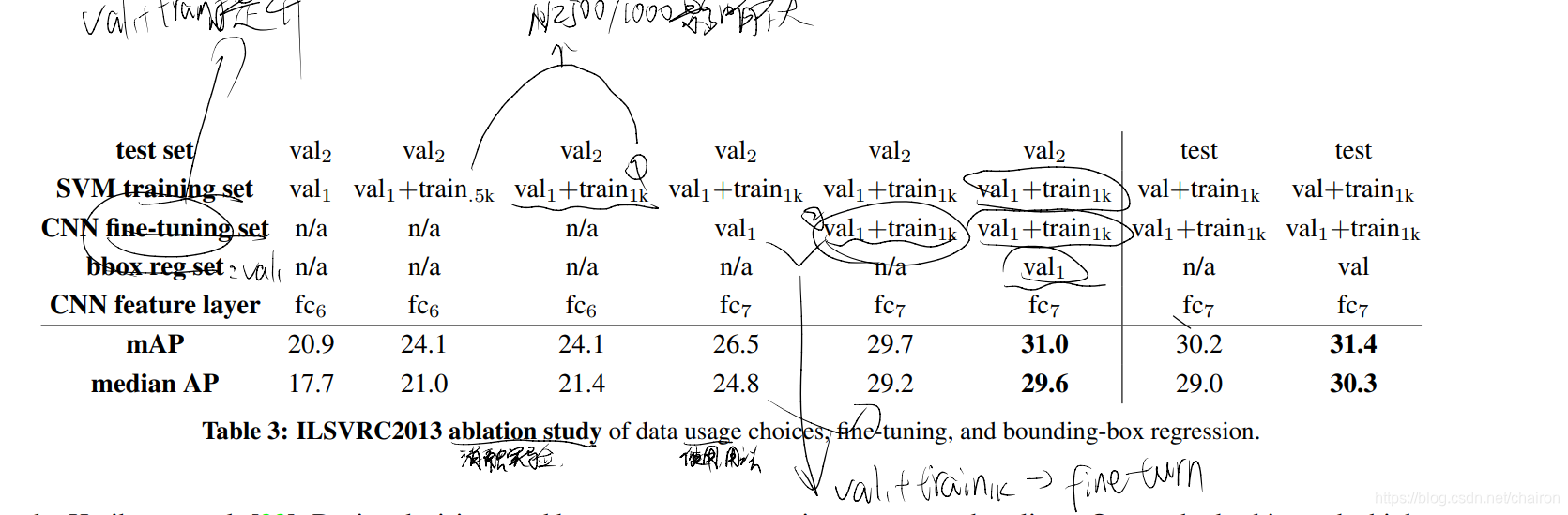
对于训练数据,我们形成了一组图像和框,其中包括来自 val1 的所有selective search and ground-truth boxes以及来自训练集的每个类最多 N 个ground-truth boxes(如果一个类的ground-truth box少于 N,我们把它们全部拿走)。我们称之为图像和框 val1+trainN 的数据集。
在消融研究中,我们在 val2 上显示了 N 2 {0, 500, 1000} 的 mAP(第 4.5 节)。
7.2.2 训练数据
R-CNN 中的三个过程需要训练数据:
-
CNN 微调: val1+trainN
- 正样本:≥ 0.5 IoU 重叠的region-proposal(
- 其余视为负例
-
检测器 SVM 训练 :
- 正样本:val1+trainN 的grount-truth box
- 负样本:val1 5000张中IOU<0.3 的region-proposal
-
边界框回归器训练:val1
7.2.3 疑问
-
为什么在微调 CNN 和训练对象检测 SVM 时正例和反例的定义不同?
答:正例和反例怎样定义的影响不大,主要是进行CNN 微调的数据集太少了 假设是,在定义正面和负面的方式上的这种差异从根本上来说并不重要,而是由于微调数据有限这一事实引起的。 我们当前的方案引入了许多“抖动”示例(那些重叠在 0.5 和 1 之间的提案,但不是ground-truth),这将正面示例的数量增加了大约 30 倍。 但是这可能导致结果不是最优的,因为没有针对精确的定位进行微调 如果训练数据足够多,就可以把CNN fine-tuning 的样本定义为和SVM train 一样 -
为什么有必要训练SVM而不是简单地使用来自微调 CNN 的最后一层 (fc8) 的输出。(fc8: a 21-way softmax regression classifier)
答:实验表明fc8让精度下降了,这种性能下降可能源于微调中使用的正例的定义,它不强调精确定位。
8 Validation and evaluation
数据集:
- 验证:val2 无 bounding-box regression
- 评估:ILSVRC2013 evaluation server 有bounding-box regression
模型: - CNN:使用在val+train 1k上微调好的CNN,避免重复计算
- SVM train: val + train 1k
- bbox regression: val
(SVM 和 bbox regression 数据集被扩展了)
9 总结
效果:本文提出了一种简单且可扩展的对象检测算法,与 PASCAL VOC 2012 上的最佳先前结果相比,相对提高了 30%。
我们通过两个方法实现了这一性能。
- 首先是将大容量卷积神经网络应用于自下而上的region proposal,以定位和分割对象。
- 第二个是在标记训练数据稀缺时训练大型 CNN 的范例。
- 我们表明,对于具有丰富数据的辅助任务(图像分类),在有监督的情况下对网络进行预训练,
- 然后针对数据稀缺的目标任务(检测)对网络进行微调是非常有效的。
我们推测“有监督的预训练/特定领域的微调”范式对于各种数据稀缺的视觉问题将非常有效


















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









