







 本文介绍了一种新的算法DPO,它跳过奖励模型环节,通过直接利用人类偏好数据来微调语言模型,相比传统RLHF方法更稳定高效。实验显示DPO在保持一致性的同时提升了响应质量和简化实现。
本文介绍了一种新的算法DPO,它跳过奖励模型环节,通过直接利用人类偏好数据来微调语言模型,相比传统RLHF方法更稳定高效。实验显示DPO在保持一致性的同时提升了响应质量和简化实现。
DPO

Paper: https://arxiv.org/abs/2305.18290
Code: https://github.com/eric-mitchell/direct-preference-optimization
基于 人类反馈的强化学习(RLHF) 是一个复杂且不稳定的过程,首先拟合一个反映人类偏好的奖励模型,然后使用强化学习对大语言模型进行微调,以最大限度地提高估计奖励,同时又不能偏离原始模型太远。这涉及训练多个 LM,并在训练循环中从 LM 采样,从而产生大量的计算成本。
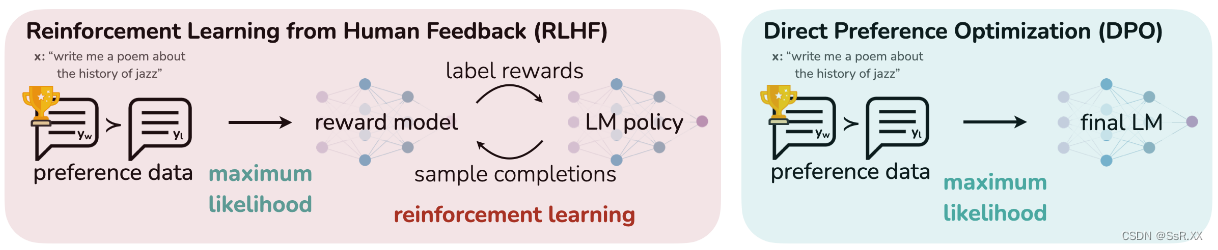
本文作者提出了 直接偏好优化(DPO) 算法,它稳定、高效且计算量轻,无需拟合奖励模型,也无需在微调期间从LM采样或执行显著的超参数调整。实验表明,DPO 可以微调 LMs,使其与人类偏好保持一致,与现有方法一样或更好。值得注意的是,DPO 在情绪控制的能力上超越了 RLHF,提高了总结和单轮对话的响应质量,同时大大简化了实现和训练。
RLHF pipeline
RLHF通常由3个阶段组成:1)监督微调;2)偏好采样和奖励学习;3)强化学习微调;
SFT 阶段
RLHF 通常从一个通用的预训练 LM 开始,该 LM 在高质量数据集上通过监督学习(最大似然)对感兴趣的下游任务(如对话、指令跟随、总结等)进行微调,以获得模型 π S F T \pi^{SFT} πSFT。
Reward 建模阶段
在第二阶段,用 x x x 提示 π S F T \pi^{SFT} πSFT 产生一对答案 ( y 1 , y 2 ) ∼ π S F T ( y ∣ x ) (y_1, y_2) \sim \pi^{SFT}(y\mid x) (y1,y2)∼πSFT(y∣x)。通过人类标注,得到偏好标签 y w ≻ y l ∣ x y_w \succ y_l \mid x yw≻yl∣x,其中 y w y_w yw 表示首选补全, y l y_l yl 表示非首选补全。
通过静态数据集
D
=
{
x
i
,
y
w
i
,
y
l
i
}
i
=
1
N
D=\{x^{i},y^{i}_w,y^{i}_l\}_{i=1}^N
D={xi,ywi,yli}i=1N,我们可以将奖励模型
r
ϕ
(
x
,
y
)
r_{\phi}(x,y)
rϕ(x,y) 参数化,并通过极大似然估计参数。将问题定义为二元分类,我们有负对数似然损失:
L
R
(
r
ϕ
,
D
)
=
−
E
(
x
,
y
w
,
y
l
)
∼
D
[
log
σ
(
r
ϕ
(
x
,
y
w
)
−
r
ϕ
(
x
,
y
l
)
)
]
(1)
\mathcal{L}_{R}\left(r_{\phi}, \mathcal{D}\right)=-\mathbb{E}_{\left(x, y_{w}, y_{l}\right) \sim \mathcal{D}}\left[\log \sigma\left(r_{\phi}\left(x, y_{w}\right)-r_{\phi}\left(x, y_{l}\right)\right)\right] \tag{1}
LR(rϕ,D)=−E(x,yw,yl)∼D[logσ(rϕ(x,yw)−rϕ(x,yl))](1)
其中
σ
\sigma
σ 是
s
i
g
m
o
i
d
sigmoid
sigmoid 函数。奖励模型
r
ϕ
(
x
,
y
)
r_{\phi}(x,y)
rϕ(x,y) 通常由
π
S
F
T
\pi^{SFT}
πSFT 进行初始化,并在最后一个 Transformer 层之后添加线性层,该层为奖励值生成单个标量预测。
RL 微调阶段
在 RL 阶段,我们使用学习到的奖励函数来为语言模型提供反馈。特别是,我们制定了以下优化问题:
max
π
θ
E
x
∼
D
,
y
∼
π
θ
(
y
∣
x
)
[
r
ϕ
(
x
,
y
)
]
−
β
D
K
L
[
π
θ
(
y
∣
x
)
∥
π
r
e
f
(
y
∣
x
)
]
(2)
\max _{\pi_{\theta}} \mathbb{E}_{x \sim \mathcal{D}, y \sim \pi_{\theta}(y \mid x)}\left[r_{\phi}(x, y)\right]-\beta \mathbb{D}_{\mathrm{KL}}\left[\pi_{\theta}(y \mid x) \| \pi_{\mathrm{ref}}(y \mid x)\right] \tag{2}
πθmaxEx∼D,y∼πθ(y∣x)[rϕ(x,y)]−βDKL[πθ(y∣x)∥πref(y∣x)](2)
其中
β
\beta
β 是控制
π
θ
\pi_{\theta}
πθ 偏离基本参考策略
π
r
e
f
\pi_{ref}
πref 的参数。在实践中,语言模型策略
π
θ
\pi_{\theta}
πθ 也被初始化为
π
r
e
f
\pi_{ref}
πref。添加的
β
\beta
β 约束很重要,因为它可以防止模型偏离奖励模型准确的分布太远,以及保持生成多样性和防止模式崩溃为单个高奖励答案。由于语言生成的离散性,这个目标是不可微的,并且通常使用强化学习进行优化。标准方法是构造奖励函数
r
(
x
,
y
)
=
r
ϕ
(
x
,
y
)
−
β
(
log
π
θ
(
y
∣
x
)
−
log
π
r
e
f
(
y
∣
x
)
)
r(x, y) = r_{\phi}(x, y) - \beta(\log π_{\theta} (y \mid x) - \log π_{ref}(y \mid x))
r(x,y)=rϕ(x,y)−β(logπθ(y∣x)−logπref(y∣x)),并利用 PPO 最大化。
直接偏好优化(DPO)
与之前的 RLHF 方法不同,DPO 绕过了奖励建模步骤,并使用偏好数据直接优化语言模型。
DPO 目标函数
类似于奖励建模方法,即等式
(
1
)
(1)
(1),我们的策略目标变为:(推导过程详见原论文)
L
D
P
O
(
π
θ
;
π
r
e
f
)
=
−
E
(
x
,
y
w
,
y
l
)
∼
D
[
log
σ
(
β
log
π
θ
(
y
w
∣
x
)
π
r
e
f
(
y
w
∣
x
)
−
β
log
π
θ
(
y
l
∣
x
)
π
r
e
f
(
y
l
∣
x
)
)
]
(3)
\mathcal{L}_{\mathrm{DPO}}\left(\pi_{\theta} ; \pi_{\mathrm{ref}}\right)=-\mathbb{E}_{\left(x, y_{w}, y_{l}\right) \sim \mathcal{D}}\left[\log \sigma\left(\beta \log \frac{\pi_{\theta}\left(y_{w} \mid x\right)}{\pi_{\mathrm{ref}}\left(y_{w} \mid x\right)}-\beta \log \frac{\pi_{\theta}\left(y_{l} \mid x\right)}{\pi_{\mathrm{ref}}\left(y_{l} \mid x\right)}\right)\right] \tag{3}
LDPO(πθ;πref)=−E(x,yw,yl)∼D[logσ(βlogπref(yw∣x)πθ(yw∣x)−βlogπref(yl∣x)πθ(yl∣x))](3)
通过这种方式,我们绕过了显式奖励建模步骤,同时也避免了执行强化学习优化的需要。
逐步分析这个优化目标:首先, σ \sigma σ 函数里面的值越大, L D P O L_{DPO} LDPO 越小。
即最大化 y w y_w yw 和 y l y_l yl 的奖励函数:
r w = log π θ ( y w ∣ x ) π r e f ( y w ∣ x ) r l = log π r e f ( y l ∣ x ) π θ ( y l ∣ x ) r_w = \log\frac{\pi_{\theta}\left(y_{w} \mid x\right)}{\pi_{\mathrm{ref}}\left(y_{w} \mid x\right)} \\ r_l = \log\frac{\pi_{\mathrm{ref}}\left(y_{l} \mid x\right)}{\pi_{\theta}\left(y_{l} \mid x\right)} rw=logπref(yw∣x)πθ(yw∣x)rl=logπθ(yl∣x)πref(yl∣x)
对于人类偏好响应 y w y_w yw,我们期望 π θ ( y w ∣ x ) \pi_{\theta}(y_w \mid x) πθ(yw∣x) 越大越好;对于人类非偏好响应 y l y_l yl,我们期望 π θ ( y l ∣ x ) \pi_{\theta}(y_l\mid x) πθ(yl∣x) 越小越好。
如果 π r e f ( y w ∣ x ) \pi_{\mathrm{ref}}\left(y_w \mid x\right) πref(yw∣x) 比较小,说明参考模型 π r e f \pi^{\mathrm{ref}} πref 没有正确分类该偏好响应 y w y_w yw,此时 r w r_w rw 的奖励系数很大。
如果 π r e f ( y l ∣ x ) \pi_{\mathrm{ref}}\left(y_l \mid x\right) πref(yl∣x) 比较大,说明参考模型 π r e f \pi^{\mathrm{ref}} πref 没有正确分类该非偏好响应 y l y_l yl,此时 r l r_l rl 的奖励系数很大。
DPO outline
- 对于每个提示 x x x,从参考策略中采样补全 ( y 1 , y 2 ) ∼ π r e f ( ⋅ ∣ x ) (y_1, y_2) \sim \pi_{\mathrm{ref}}(\cdot \mid x) (y1,y2)∼πref(⋅∣x),用人类偏好进行标记以构建离线偏好数据集 D = { x i , y w i , y l i } i = 1 N D=\{x^{i},y^{i}_w,y^{i}_l\}_{i=1}^N D={xi,ywi,yli}i=1N。
- 对于给定的 π r e f \pi_{\mathrm{ref}} πref、 D D D 和 β \beta β,优化语言模型 π θ \pi_{\theta} πθ 以最小化 L D P O L_{\mathrm{DPO}} LDPO。
由于偏好数据集使用
π
S
F
T
\pi^{SFT}
πSFT 进行采样,因此只要可用,我们就会初始化
π
r
e
f
=
π
S
F
T
\pi_{\mathrm{ref}} = \pi^{SFT}
πref=πSFT。在实践中,人们更愿意重用公开的偏好数据集,而不是生成样本并收集人类偏好。这时我们通过最大化首选补全
(
x
,
y
w
)
(x,y_w)
(x,yw) 的似然来初始化
π
r
e
f
\pi_{\mathrm{ref}}
πref,即
π
r
e
f
=
arg
m
a
x
π
E
x
,
y
w
∼
D
[
log
π
(
y
w
∣
x
)
]
\pi_{\mathrm{ref}} = \arg \mathrm{max}_{\pi}\mathbb{E}_{x,y_w\sim\mathcal{D}}\left[\log\pi\left(y_w\mid x\right) \right]
πref=argmaxπEx,yw∼D[logπ(yw∣x)]
该过程有助于缓解真实
π
r
e
f
\pi_{\mathrm{ref}}
πref 与 DPO 使用的
π
r
e
f
\pi_{\mathrm{ref}}
πref 之间的分布偏移。
实验
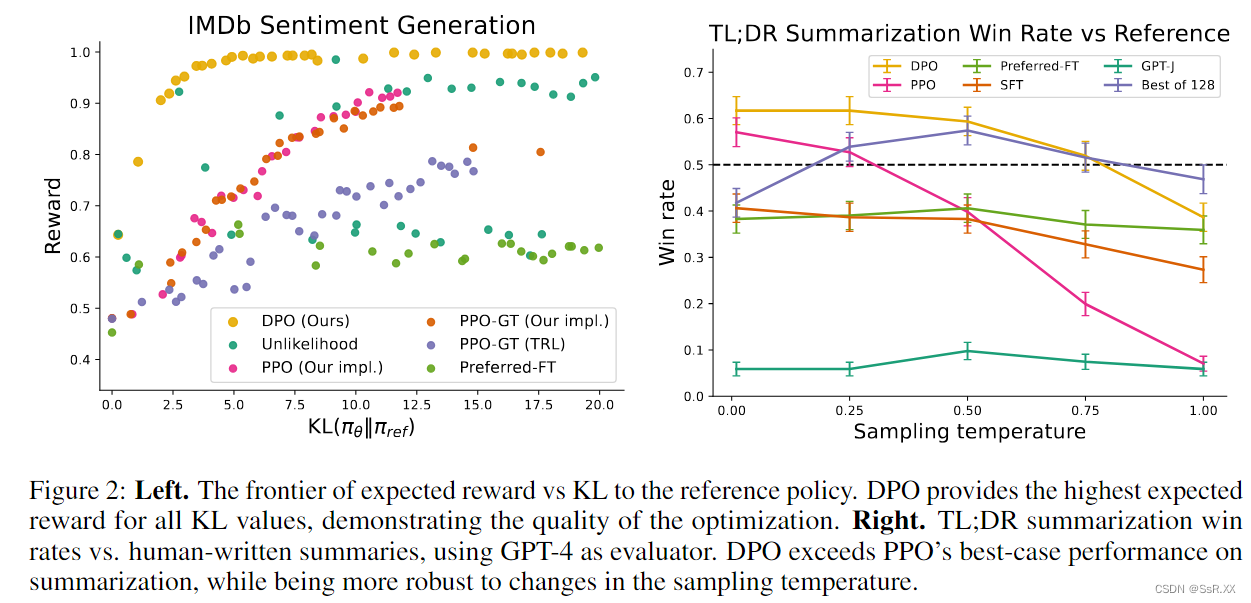
- 最大化奖励的同时最小化 KL 散度。可以看到 DPO 在保持较小 KL 散度时,也能够达到最大奖励。而 PPO 随着奖励的增大,KL 散度也在增大。
- 对不同采样温度的鲁棒性。DPO 在不同的采样温度下全面优于 PPO,同时在 Best of N 基线的最佳温度下也更胜一筹。
结论
基于人类反馈的强化学习(RLHF)是一个复杂且不稳定的过程,首先拟合一个反映人类偏好的奖励模型,然后使用强化学习对大语言模型进行微调,以最大限度地提高估计奖励,同时又不能偏离原始模型太远。这涉及训练多个 LM,并在训练循环中从 LM 采样,从而产生大量的计算成本。本文作者提出了直接偏好优化(DPO)算法,它稳定、高效且计算量轻,无需拟合奖励模型,也无需在微调期间从LM采样或执行显著的超参数调整。实验表明,DPO 可以微调 LMs,使其与人类偏好保持一致,与现有方法一样或更好。值得注意的是,DPO 在情绪控制的能力上超越了 RLHF,提高了总结和单轮对话的响应质量,同时大大简化了实现和训练。

















 1563
1563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









