rom operator import index
import torch
import numpy as np
import pickle,argparse,os,math,rdkit
import rdkit.Chem as Chem
from torch.utils.data import Dataset,DataLoader
from PLANET_model import PLANET
import pandas as pd
from sklearn.metrics import roc_auc_score,precision_recall_curve,auc
from chemutils import ProteinPocket,mol_batch_to_graph,tensorize_protein_pocket
class VirtualScreening_Dataset(Dataset):
def __init__(self,smi_file,batch_size=32):
self.batch_size = batch_size
with open(smi_file,'r') as f:
smi_content = [line.strip().split()[0] for line in f]
self.smi_content = [smi_content[i:i+batch_size] for i in range(0,len(smi_content),batch_size)]
def __len__(self):
return len(self.smi_content)
def __getitem__(self,idx):
return self.tensorize(idx)
def tensorize(self,idx):
mol_smi_batch = self.smi_content[idx]
mol_batch = [Chem.AddHs(Chem.MolFromSmiles(smi)) for smi in mol_smi_batch if Chem.MolFromSmiles(smi) is not None]
mol_feature_batch = mol_batch_to_graph(mol_batch,auto_detect=False)
mol_smiles = [smi for smi in mol_smi_batch if Chem.MolFromSmiles(smi) is not None]
return (mol_feature_batch,mol_smiles)
def predict(model:PLANET,protein_pdb,ligand_sdf,dataloader):
#model.eval()
pocket = ProteinPocket(protein_pdb=protein_pdb,ligand_sdf=ligand_sdf)
fresidues = model.cal_res_features_helper(pocket.res_features,pocket.alpha_coordinates)
predicted_affinities,smiles = [],[]
for (mol_feature_batch,mol_smiles) in dataloader:
fresidues_batch,res_scope = model.cal_res_features(fresidues,len(mol_smiles))
predicted_affinity = model.screening(fresidues_batch,res_scope,mol_feature_batch)
predicted_affinities.append(np.array(predicted_affinity.squeeze().detach().cpu().reshape([-1])))
smiles.extend(mol_smiles)
predicted_affinities = np.concatenate(predicted_affinities,axis=0)
return predicted_affinities,smiles
def workflow(model,folder_path,out_folder):
#receptor_name = folder_path.split('/')[-1]
actives_smi = os.path.join(folder_path,'actives_prep.smi')
decoys_smi = os.path.join(folder_path,'decoys_prep.smi')
crystal_ligand = os.path.join(folder_path,'crystal_ligand.sdf')
pdb_path = os.path.join(folder_path,'prepared_receptor.pdb')
active_dataset = VirtualScreening_Dataset(actives_smi)
active_loader = DataLoader(active_dataset,batch_size=1,shuffle=False,num_workers=4,drop_last=False,collate_fn=lambda x:x[0])
decoy_dataset = VirtualScreening_Dataset(decoys_smi)
decoy_loader = DataLoader(decoy_dataset,batch_size=1,shuffle=False,num_workers=4,drop_last=False,collate_fn=lambda x:x[0])
predicted_active_affinities,active_smiles = predict(model,pdb_path,crystal_ligand,active_loader)
predicted_decoy_affinities,decoy_smiles = predict(model,pdb_path,crystal_ligand,decoy_loader)
active_path = os.path.join(out_folder,'active.csv')
decoy_path = os.path.join(out_folder,'decoy.csv')
write_csv(predicted_active_affinities,active_smiles,active_path)
write_csv(predicted_decoy_affinities,decoy_smiles,decoy_path)
return predicted_active_affinities,predicted_decoy_affinities
def write_csv(affinities,smiles,out_path):
csv_frame = pd.DataFrame([
{
'Affinity':affinity,'SMILES':smi,
}
for affinity,smi in zip(affinities,smiles)
])
csv_frame.to_csv(out_path)
def EF_sort(active_pK,decoy_pK):
all_pk = np.concatenate([active_pK,decoy_pK])
cat_array = np.concatenate([np.ones_like(active_pK),np.zeros_like(decoy_pK)])
auc_score = roc_auc_score(cat_array,all_pk)
sorted_index = np.argsort(all_pk*(-1))
sorted_array = np.array([cat_array[index] for index in sorted_index])
return sorted_array,auc_score
def EF_calculate(sorted_array,factor):
all_count = len(sorted_array)
sample_count = math.ceil(all_count*factor)
hits_total = sorted_array.sum()
hits_count = sorted_array[:sample_count].sum()
EF = (hits_count/sample_count) / (hits_total/all_count)
return EF
def _percision_recall_area(active_pK,decoy_pK):
y_pred = np.concatenate([active_pK,decoy_pK])
y_true = np.concatenate([np.ones_like(active_pK),np.zeros_like(decoy_pK)])
precision, recall, thresholds = precision_recall_curve(y_true,y_pred)
area = auc(recall, precision)
return area
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('-f','--PLANET_file',required=True)
parser.add_argument('-d','--DUDE',required=True)
parser.add_argument('-o','--out_dir',required=True)
parser.add_argument('-s','--feature_dims', type=int, default=300)
parser.add_argument('-n','--nheads', type=int, default=8)
parser.add_argument('-k','--key_dims', type=int, default=300)
parser.add_argument('-va','--value_dims', type=int, default=300)
parser.add_argument('-pu','--pro_update_inters', type=int, default=3)
parser.add_argument('-lu','--lig_update_iters',type=int,default=10)
parser.add_argument('-pl','--pro_lig_update_iters',type=int,default=1)
args = parser.parse_args()
feature_dims,nheads,key_dims,value_dims,pro_update_inters,lig_update_iters,pro_lig_update_iters = args.feature_dims,args.nheads,args.key_dims,args.value_dims,\
args.pro_update_inters,args.lig_update_iters,args.pro_lig_update_iters
PLANET = PLANET(feature_dims,nheads,key_dims,value_dims,pro_update_inters,lig_update_iters,pro_lig_update_iters,'cuda').cuda()
PLANET.load_state_dict(torch.load(args.PLANET_file))
out_dir = args.out_dir
os.makedirs(args.out_dir,exist_ok=True)
target_names,active_means,active_medians,decoy_means,decoy_medians,EF_05,EF_1,EF_2,EF_5,auc_scores,auc_prs = [],[],[],[],[],[],[],[],[],[],[]
PLANET.eval()
with torch.no_grad():
for folder in os.listdir(args.DUDE):
work_folder = os.path.join(args.DUDE,folder)
out_folder = os.path.join(out_dir,folder)
os.makedirs(out_folder,exist_ok=True)
predicted_active_affinities,predicted_decoy_affinities = workflow(model=PLANET,folder_path=work_folder,out_folder=out_folder)
sorted_array,auc_score = EF_sort(predicted_active_affinities,predicted_decoy_affinities)
auc_pr = _percision_recall_area(predicted_active_affinities,predicted_decoy_affinities)
target_names.append(str(folder).upper())
active_means.append(predicted_active_affinities.mean())
active_medians.append(np.median(predicted_active_affinities))
decoy_means.append(predicted_decoy_affinities.mean())
decoy_medians.append(np.median(predicted_decoy_affinities))
EF_05.append(EF_calculate(sorted_array,0.005))
EF_1.append(EF_calculate(sorted_array,0.01))
EF_2.append(EF_calculate(sorted_array,0.02))
EF_5.append(EF_calculate(sorted_array,0.05))
auc_scores.append(auc_score)
auc_prs.append(auc_pr)
torch.cuda.empty_cache()
#active_result_path = os.path.join(work_folder,'{}_active.dat'.format(folder))
#decoy_result_path = os.path.join(work_folder,'{}_decoy.dat'.format(folder))
#with open(active_result_path,'w') as active_dat:
#for item in active_affinities.tolist():
# active_dat.write(str(item)+'\n')
#with open(decoy_result_path,'w') as decoy_dat:
# for item in decoy_affinities.tolist():
# decoy_dat.write(str(item)+'\n')
csv_frame = pd.DataFrame([
{
'Target Name':target_name,'Active Mean':active_mean,'Active Median':active_median,
'Decoy Mean':decoy_mean,'Decoy Median':decoy_median,'Delta Mean':active_mean-decoy_mean,'Delta Median':active_mean-decoy_median,
'EF_0.5%':x,'EF_1%':y,'EF_2%':z,'EF_5%':w,'ROC_AUC Score':auc_score,'ROC_PR Score':auc_pr
}
for target_name,active_mean,active_median,decoy_mean,decoy_median,x,y,z,w,auc_score in zip(target_names,active_means,active_medians,decoy_means,decoy_medians,EF_05,EF_1,EF_2,EF_5,auc_scores,auc_prs)
])
csv_frame.to_csv(os.path.join(out_dir,'summary.csv'))这个是什么代码,作用和意义
最新发布











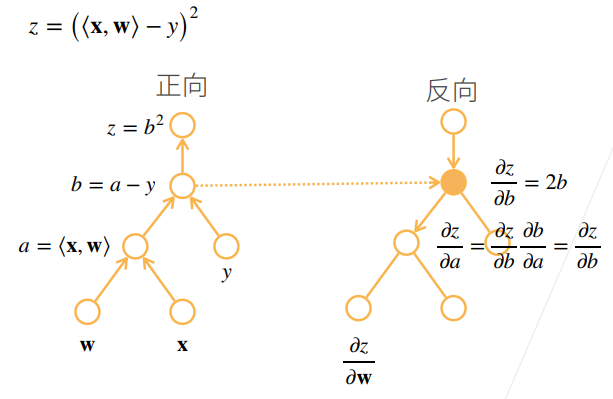
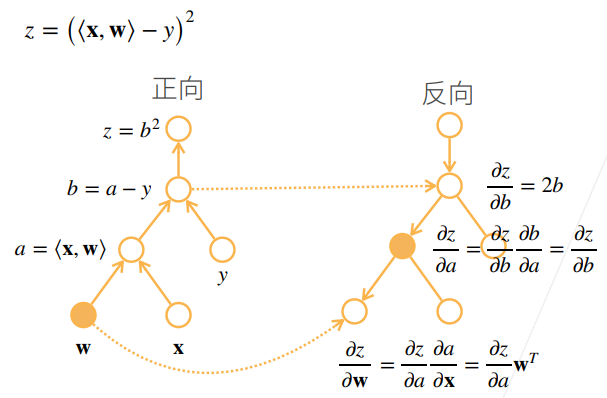
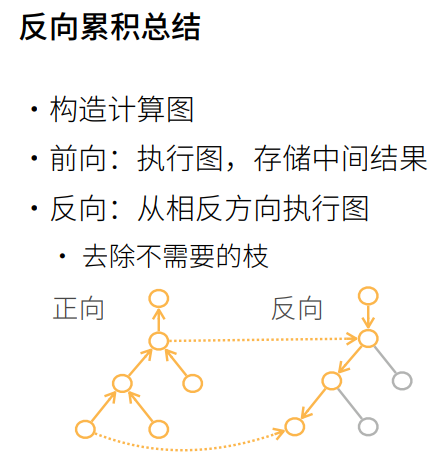





















 163
163

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











