







 本文介绍了如何在PyTorch中创建带有滑动步长的训练集和测试集,特别适用于LSTM等需要序列输入的模型。通过示例代码展示了不同滑动步长下批处理的生成过程,解决训练数据的连续性问题。
本文介绍了如何在PyTorch中创建带有滑动步长的训练集和测试集,特别适用于LSTM等需要序列输入的模型。通过示例代码展示了不同滑动步长下批处理的生成过程,解决训练数据的连续性问题。
话不多说,先上代码
Example1
from torch.utils import data
import torch
batch_size = 3
t1 = np.arange(0,20)
t2 = np.arange(0,20)+100
生成序列0~19和100~190,分别模拟x_train和y_train
tensor1 = torch.from_numpy(t1)
tensor2 = torch.from_numpy(t2)
上一步很关键,否则报错
data_set = data.TensorDataset(tensor1,tensor2)
data_iter = data.DataLoader(data_set,batch_size=3,shuffle=False)
for x_batch, y_batch in data_iter:
print('-----------------')
dsp(x_batch)
dsp(y_batch)
print('-----------------')
部分输出结果:

不过上面的例子有个问题,如果使用类似LSTM这种模型,需要滑动输入比如
原始如下:
tensor([0, 1, 2])
tensor([100, 101, 102])
tensor([3, 4, 5])
tensor([103, 104, 105])
那么带滑动步长的时候呢slide=1的时候
mini_batch01:
tensor([0,1,2])
tensor([100, 101, 102])
mini_batch02:
tensor([1, 2, 3])
tensor([101,102,103])
那么带滑动步长的时候呢slide=2的时候
mini_batch01:
tensor([0, 1, 2])
tensor([100, 101, 102])
mini_batch02:
tensor([2, 3, 4])
tensor([102,103,104])
怎么办呢?
可以仿照TensorDataset写一个类似的类
class Mydataset(data.TensorDataset):
def __init__(self, data, window):
self.data = data
self.window = window
def __getitem__(self, index):
x = self.data[index:index+self.window]
return x
def __len__(self):
return len(self.data) - self.window
承接example1
data_set = data.TensorDataset(tensor1,tensor2)
d2 = Mydataset(data_set,3)
data_iter = data.DataLoader(d2,batch_size=3,shuffle=False)
for x_batch, y_batch in data_iter:
print('-----------------')
dsp(x_batch)
dsp(y_batch)
print('-----------------')
部分输出结果为:

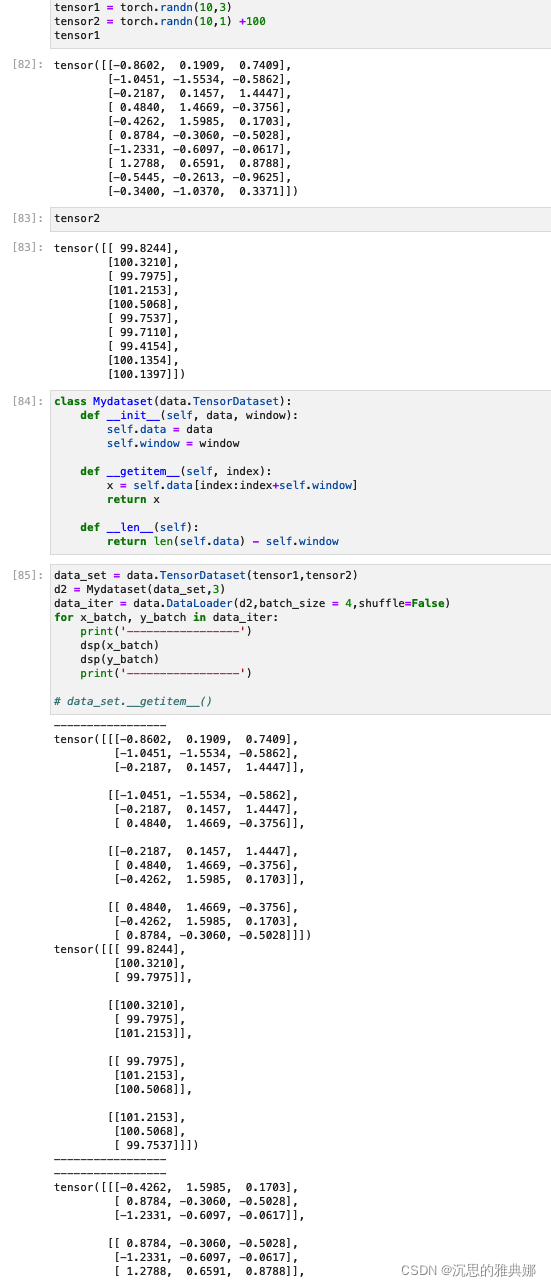
Example3:
直接上图吧


















 4434
4434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









