




2025年AI开发范式革命:无需写代码、不租GPU,拖拽节点3小时上线智能应用
一、为什么开发者都在用Dify?
核心能力全景图
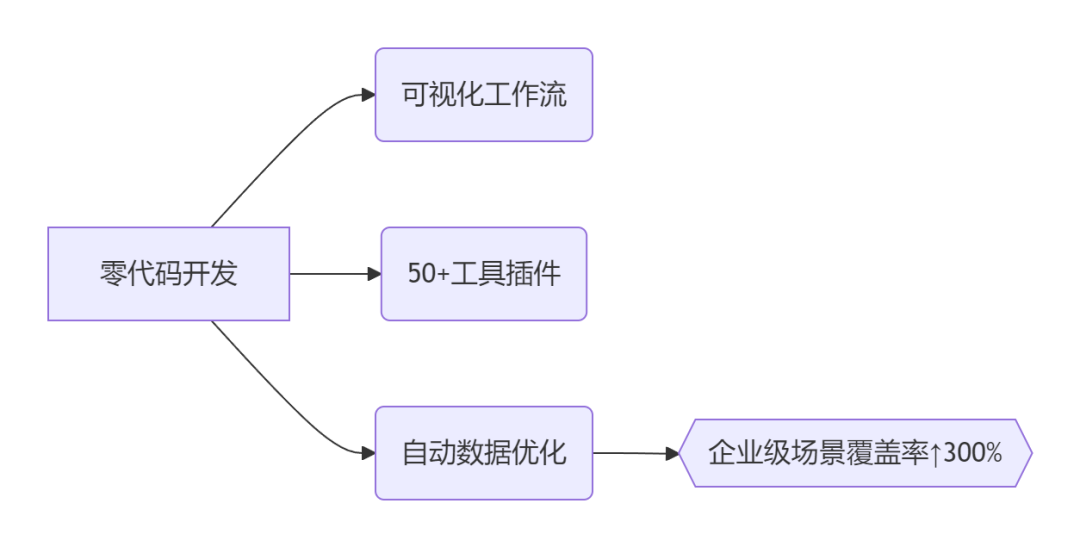
三大颠覆性价值:
-
乐高式搭建:拖拽节点连接AI模型、知识库、API工具,1小时构建客服机器人/数据分析助手
-
模型无界兼容:一键接入OpenAI/DeepSeek/讯飞星火等20+主流模型,快速切换推理引擎
-
生产级监控:自动记录对话日志,像“行车记录仪”般追踪AI表现,持续优化效果
二、四步极速部署(含避坑指南)
步骤1:环境准备
# 官方推荐Docker部署
git clone https://github.com/langgenius/dify
cd dify/docker
cp .env.example .env
docker-compose up -d # 启动9个核心服务
避坑提示:
- Windows用户必看:若遇WSL2安装失败(错误码0x80370102),需:
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart wsl --install -d Ubuntu # 重装内核 - Linux内存优化:编辑
~/.wslconfig添加:[wsl2] memory=6GB # 低于8GB易崩溃
步骤2:模型配置
进入http://localhost:8088 → 设置→模型供应商 → 添加API Key:
- 国产模型示例:
阿里通义千问: API Key:sk-xxxxx Base URL:https://dashscope.aliyuncs.com/compatible-mode/v1 -
本地模型集成:Ollama地址填
http://host.docker.internal:11434
三、企业级实战:从知识库到智能体
场景1:高性能知识库搭建
优化四要素:
|
参数 |
推荐值 |
作用 |
|---|---|---|
|
分段最大长度 |
512 tokens |
避免信息割裂 |
|
分段重叠长度 |
64 tokens |
提升上下文连续性 |
|
检索方式 |
混合检索 |
平衡准确率与召回率 |
|
Rerank模型 |
bge-reranker |
结果排序优化↑40% |
外接专业知识库:
-
知识库→外部API → 名称填
RAGFlow -
Endpoint填
https://[RAGFlow域名]/api/v1/dify -
输入RAGFlow的API Key → 测试连接
!https://example.com/rag_config.png
图:Dify中配置混合检索权重(语义0.7+关键词0.3)
场景2:ChatFlow智能体开发(以天气查询为例)
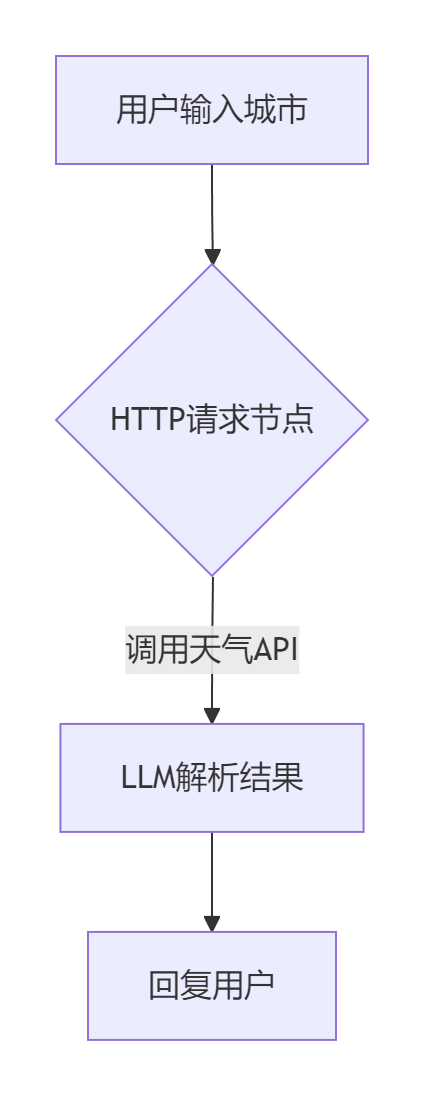
关键配置:
- HTTP节点:
URL = https://wttr.in/{{city}}?format=j1 # 动态绑定变量 - LLM节点:
System Prompt: “请用口语化描述今日天气,包含温度/降水/风力” 输入变量: {{API返回的JSON数据}} -
权限控制:设置成员权限 → 禁止普通用户修改工作流
四、避坑指南:高频问题解决方案
坑1:知识库检索结果不稳定
-
根因:分段策略不当导致信息碎片化
-
解决:
-
开启“替换连续空格/换行符”选项
-
添加规则型预处理节点:删除URL/邮箱等噪声数据
-
坑2:智能体响应超时
-
性能压测数据:
优化策略
单请求耗时
并发能力
基础配置
8.2s
10 QPS
+上下文复用
3.5s
30 QPS
+异步任务队列
1.1s
80 QPS
-
操作指南:
# 在FastAPI服务中添加重试逻辑 from requests.adapters import HTTPAdapter, Retry adapter = HTTPAdapter(max_retries=Retry(total=3)) session.mount('https://', adapter)
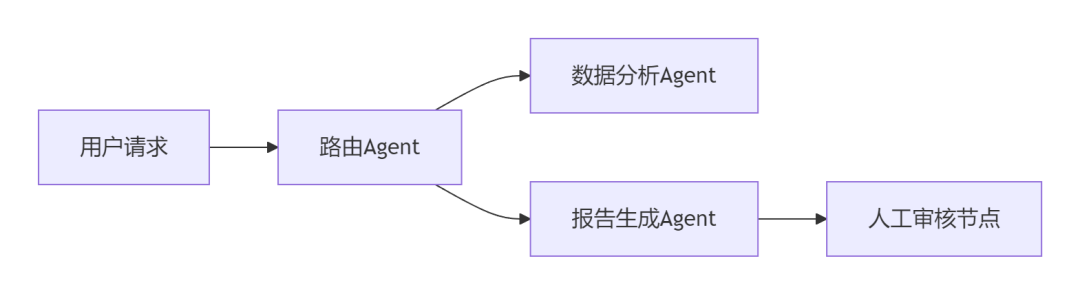
坑3:多Agent协作混乱
黄金法则:
工作流步骤≤10步,超限则拆分子智能体!
-
协作架构:
五、企业级进阶架构设计
部署拓扑
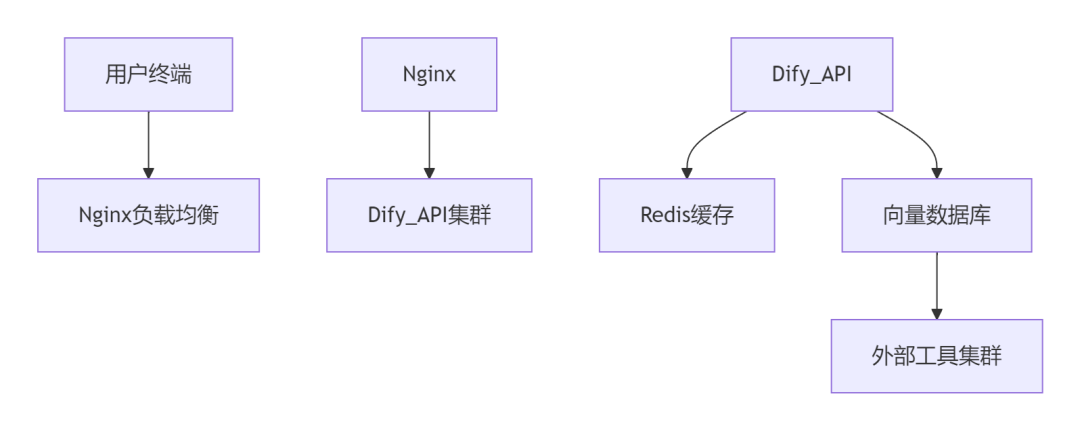
安全加固方案:
-
传输加密:HTTPS + JWT双向认证
-
审计日志:记录所有操作截图及DOM变更
结语:AI开发的“水电煤”时代已来
技术民主化公式:
AI生产力 = (业务需求 × Dify节点) ÷ 编码复杂度
三条行动指南:
1️⃣ 拒绝重复造轮子:优先用Marketplace插件(已上线40+工具)
2️⃣ 状态外置原则:会话ID存Redis,文件存OSS,零状态智能体
3️⃣ 人机协同验证:关键环节插入人工审核节点(如金融风控)
2025新趋势:
Dify将支持实时视频流处理(动态修改生成内容)
边缘部署:工作流编译为WebAssembly,脱离云端运行
下期预告:《Dify+Playwright:自动操作浏览器抓取数据》


















 901
901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









