



 本文深入解析FastText深度学习模型,介绍了其如何通过引入subword n-gram概念解决低频词和未登录词的问题,以及在文本分类任务上的优势。文章提供了FastText的安装指南和参数说明,展示了如何通过修改参数提升模型性能。
本文深入解析FastText深度学习模型,介绍了其如何通过引入subword n-gram概念解决低频词和未登录词的问题,以及在文本分类任务上的优势。文章提供了FastText的安装指南和参数说明,展示了如何通过修改参数提升模型性能。
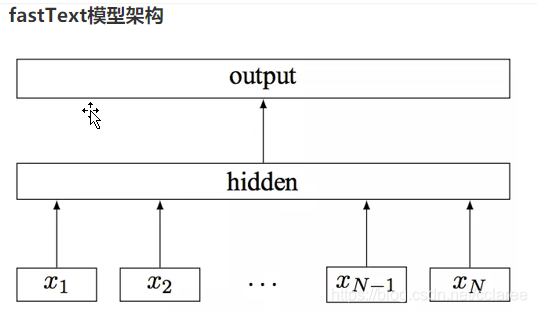
FastText是一种典型的深度学习词向量的表示方法,它非常简单通过Embedding层将单词映射到稠密空间,然后将句子中所有的单词在Embedding空间中进行平均,进而完成分类操作。
所以FastText是一个三层的神经网络,输入层、隐含层和输出层。
在fastText的工作之前,大部分的文本向量化的工作,都是以词汇表中的独立单词作为基本单元来进行训练学习的。这种想法非常自然,但也会带来如下的问题:
· 低频词、罕见词,由于在语料中本身出现的次数就少,得不到足够的训练,效果不佳;
· 未登录词,如果出现了一些在词典中都没有出现过的词,或者带有某些拼写错误的词,传统模型更加无能为力。
fastText引入了subword n-gram的概念来解决词形变化(morphology)的问题。直观上,它将一个单词打散到字符级别,并且利用字符级别的n-gram信息来捕捉字符间的顺序关系,希望能够以此丰富单词内部更细微的语义。
FastText在文本分类任务上,是优于TF-IDF的:
•FastText用单词的Embedding叠加获得的文档向量,将相似的句子分为一类
•FastText学习到的Embedding空间维度比较低,可以快速进行训练
fastText 安装
pip install fasttext
或
git clone https://github.com/facebookresearch/fastText.git
cd fastText
sudo pip install .
import pandas as pd
from sklearn.metrics import f1_score
# 转换为FastText需要的格式
train_df = pd.read_csv('../input/train_set.csv', sep='\t')
train_df['label_ft'] = '__label__' + train_df['label'].astype(str)
train_df[['text','label_ft']].iloc[:-5000].to_csv('train.csv', index=None, header=None, sep='\t')
import fasttext
model = fasttext.train_supervised('train.csv', lr=1.0, wordNgrams=2,
verbose=2, minCount=1, epoch=25, loss="hs")
val_pred = [model.predict(x)[0][0].split('__')[-1] for x in train_df.iloc[-5000:]['text']]
print(f1_score(train_df['label'].values[-5000:].astype(str), val_pred, average='macro'))
# 0.82
label2id = {}
for i in range(total):
label = str(all_labels[i])
if label not in label2id:
label2id[label] = [i]
else:
label2id[label].append(i)
结果:
0.82215
作业:
•阅读FastText的文档,尝试修改参数,得到更好的分数
fasttext参数及含义
- input # training file path (required) 训练文件路径(必须)<br>
- lr # learning rate [0.1] 学习率 default 0.1<br>
- dim # size of word vectors [100] 词向量维度 default 100<br>
- ws # size of the context window [5] 上下文窗口大小 default 5<br>
- epoch # number of epochs [5] epochs 数量 default 5<br>
- minCount # minimal number of word occurences [1] 最低词频 default 5<br>
- minCountLabel # minimal number of label occurences [1] 最少出现标签的次数 default 1<br>
- minn # min length of char ngram [0] 最小字符长度 default 0<br>
- maxn # max length of char ngram [0] 最大字符长度 default 0<br>
- neg # number of negatives sampled [5] 负样本数量 default 5<br>
- wordNgrams # max length of word ngram [1] n-gram设置 default 1<br>
- loss # loss function {ns, hs, softmax, ova} [softmax] 损失函数 {ns,hs,softmax} default softmax<br>
- bucket # number of buckets [2000000] 桶数量 default 2000000<br>
- thread # number of threads [number of cpus] 线程数量<br>
- lrUpdateRate # change the rate of updates for the learning rate [100] 更改学习率的更新率<br>
- t # sampling threshold [0.0001] 采样阈值 default 0.0001<br>
- label # label prefix ['__label__'] 标签前缀 default __label__<br>
- verbose # verbose [2]<br>
- pretrainedVectors # pretrained word vectors (.vec file) for supervised learning [] 指定使用已有的词向量 .vec 文件 default None<br>
•基于验证集的结果调整超参数,使得模型性能更优

















 36万+
36万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









