




 探讨了一种新的单目深度估计方法,该方法通过混合不同数据集来实现零样本跨数据集迁移,以增强模型的泛化能力。论文提出了一种深度和偏移不变性的损失函数,解决了数据集中深度表达不一的问题,同时介绍了一种预训练模型,能够直接从单张图像中获取深度信息。
探讨了一种新的单目深度估计方法,该方法通过混合不同数据集来实现零样本跨数据集迁移,以增强模型的泛化能力。论文提出了一种深度和偏移不变性的损失函数,解决了数据集中深度表达不一的问题,同时介绍了一种预训练模型,能够直接从单张图像中获取深度信息。
CVPR 2020 去雾 SOTA 是
Efficient Unpaired Image Dehazing with Cyclic Perceptual-Depth Supervision arxiv链接
更多CVPR 2020论文请参考https://www.cnblogs.com/Kobaayyy/p/13163056.html
其中用到了单张图片的深度信息, 这给我们一个全新的思路.
引入深度是否可以提高下游任务的模型性能?
先上图感受一下深度加入去雾模型的效果:

鲁迅说过:“Depth is among the most useful intermediate representations for action in physical environments” 深度是在物理环境中运动的最有用的特征之一
那么如何用深度网络学习深度呢?
这就是今天要讲的Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer arxiv链接
我们将回答下面四个问题:
- Describe what the authors of the paper aim to accomplish, or perhaps did achieve.
这篇论文作者的目标是什么,或者也许已经实现了什么。 - If a new approach/technique/method was introduced in a paper, what are the key elements of the newly proposed approach?
如果文中引入了一种新方法/技术,那么这一新提出的方法/技术的关键要素是什么? - What content within the paper is useful to you?
论文中,有哪些内容对你有用。 - What other references do you want to follow?
你还想关注哪些参考资料/文献?
这篇论文作者的目标是什么,或者也许已经实现了什么?
如果文中引入了一种新方法/技术,那么这一新提出的方法/技术的关键要素是什么?
- 数据集 : 现有的深度数据集的场景不够丰富, 不能训练出一个在任意场景下都健壮的模型. 因此作者选择结合这些数据集
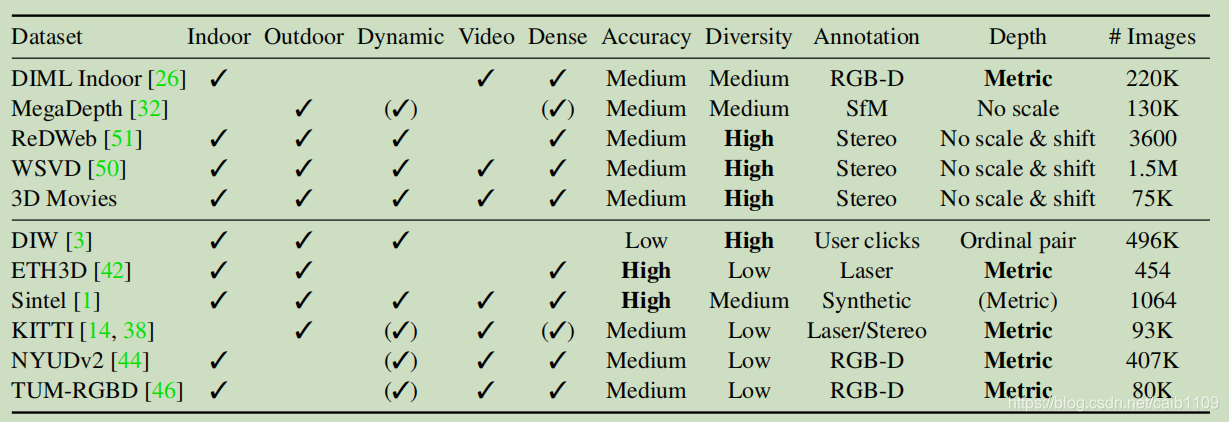 但是组合这些数据集有三个挑战:
但是组合这些数据集有三个挑战:
- 深度表达不同, 有的是0表示最近, 有的是0表示最远
- 部分数据集没有提供缩放信息
- 部分数据集提供了单张图像的相对深度(disparity), 但是跨数据集的相对深度无法直接转换
- 提出具有深度和偏移不变性的损失函数
统一用Monocular relative depth perception with web stereo data supervision中提出的方法, 得到每张图像的相对深度(disparity map), 然后以disparity map作为输入训练模型, 避免的上面提到的3个问题
令d为模型预测的disparity , d为groud truth disparity,
先进行一个线性变换得到d_hat和d_hat, 这个一步是为了校准不同数据集的disparity map
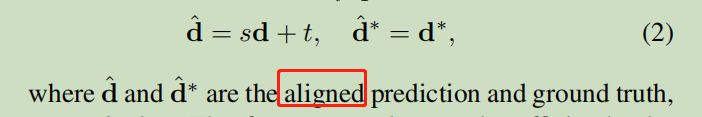
具体的校准参数定义如下:
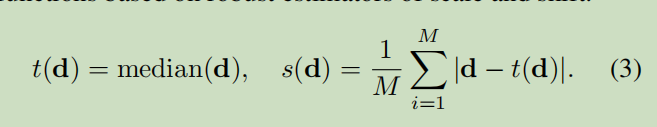
标准化一下:
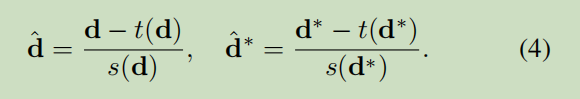
现在可以定义一个具有深度和偏移不变性的损失函数的通用形式:

为了增加泛化能力, 去掉d-d*距离最大的20%的像素

再加上一个正则项, 惩罚x方向和y方向上的导数过大
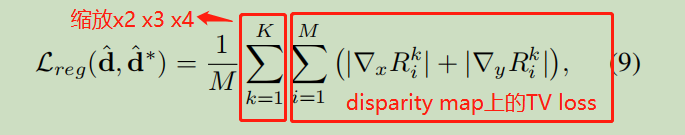
论文中,有哪些内容对你有用?
- 问题的转化
为了解决数据本身存在深度不一致的问题, 转化成设计一个对深度不敏感的loss - 预训练模型
可以直接得到任意单张图像的深度信息, 用于下游任务的训练, 就像开头说的今年的去雾SOTA一样
补充: 很遗憾, 迁移到其他方法中效果可能有限. 去雾任务中, 之所以和深度强相关, 是因为雾的数据都是人工合成的, 过去合成的效果不好, 现在引入了深度信息, 可以合成更真实的雾(深度越深, 雾越厚), 因此模型效果有了显著提升
你还想关注哪些参考资料/文献?
本质: 雾的合成–深度信息
那么超分辨的本质是什么?

















 665
665







 到【灌水乐园】发言
到【灌水乐园】发言







