




 本文科普了Tensorflow的核心概念,包括张量、GPU加速优势以及反向传播在机器学习中的作用。详细介绍了如何快速安装配置Tensorflow环境,并结合CUDA和cuDNN提升性能。适合新手入门学习。
本文科普了Tensorflow的核心概念,包括张量、GPU加速优势以及反向传播在机器学习中的作用。详细介绍了如何快速安装配置Tensorflow环境,并结合CUDA和cuDNN提升性能。适合新手入门学习。
手把手教你配置Linux深度学习服务器-不用本地安装!
1. 杂话
这是一篇科普贴, 具体的安装教程在这里手把手教你配置Tensorflow开发环境(二)-十分钟配置本地Tensorflow, CUDA, cuDNN
Pytorch版本的在这里手把手教你配置Pytorch开发环境-十分钟配置本地Pytorch, CUDA, cuDNN
2. Tensorflow到底是什么东西?
Tensorflow简单来说,其实就是python语言的一个函数库,就和numpy, pandas, matplotlib等等都是一样的,那么这个函数库到底有什么特殊的,可以让它这么出名呢?
答案就是 它是一个专门针对机器学习所涉及的库,所以也被叫做机器学习的框架。也就是说,通过使用Tensorflow这个库,我们可以很轻易的构建一些很复杂的机器学习中的模型,那么关于Tensorflow的优点呢,我来简单举几个例子:
2.1 张量
首先,在Tensorflow中,有一种叫做张量(Tensor)的数据类型。张量,简单来说也就是高维向量,在Tensorflow的函数内部,很多地方都是通过这种叫做张量的东西来进行计算和传递的,这也是Tensorflow名字的由来之一, Tensor~flow (也就是张量流)嘛。
那么,为什么这种叫张量的东西就好呢?这是因为,对于python这种语言来说,向量化的计算要比正常的计算方式要快很多,而很多时候,这种快甚至能达到十几乃至几十倍的速度差距。
想要具体了解的小伙伴可以看这篇帖子:超强Python『向量化』数据处理提速攻略
我在这里简单引用一下其中的图片:
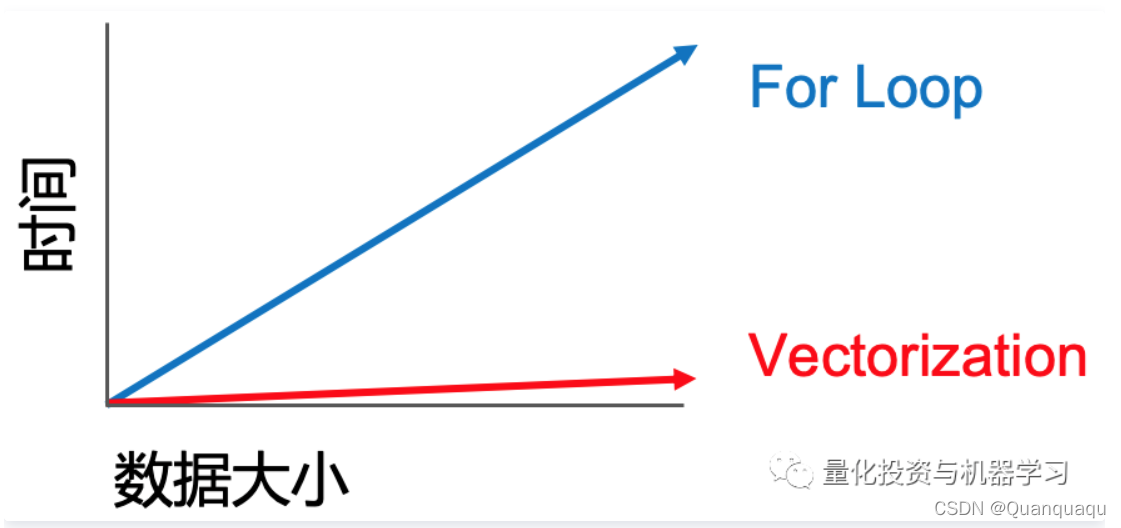
那么,向量化为什么快呢?为什么可以比循环快上这么多呢?
这是一个好问题,简单来说,向量化就是在做一种叫做并行计算的事情
什么意思呢,假设我想要计算两个向量的外积,如果我用循环来写,那么其实我是在一个一个位置的计算结果的数值对吧。
那么,在这种情况下,如果我们可以同时计算这两个数值,甚至于,我们可以同时计算矩阵中所有位置的结果,而不是一个一个的轮流计算,那不就大大的提升了我们的计算速度了吗?
我来举个例子:
这是两个向量的外积,我们可以看到结果矩阵的各个位置的数值之间,完全是可以分开计算的
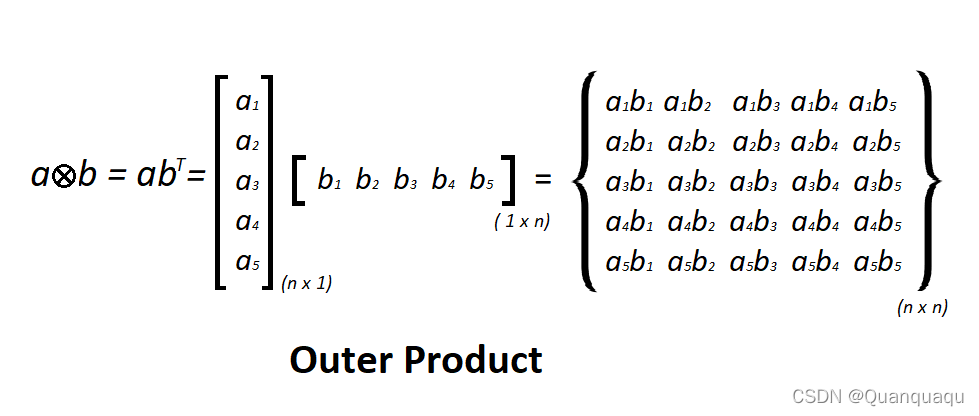
2.2 GPU加速
那么,如果我们已经理解了向量化的优势,我们可以再来说说Tensorflow的另一个特点。
咱们都知道,在咱们的电脑中,有着两个硬件,分别叫做CPU和GPU,也就是中央处理器和图像处理器(也就是咱们常说的显卡)。
那么,这两个东西有什么区别呢,来,请看下面这张图

这里面,绿色的小方块,也就是ALU,中文名叫做算数逻辑单元,简单来说就是用来计算的。
那么,根据这张图呢,我们可以这么理解,CPU里面,有好几个高级小学生,可以算很复杂的数学问题,算的速度也很快,但是人很少。GPU里面有很多普通小学生,算的速度会稍微慢一些,虽然它们人多,人特别多,超级多。
那么这也就导致了一个问题,在很多时候,我们知道对于机器学习的模型来讲,比如矩阵相乘,其实并不是很复杂的计算,而更多的是加减乘除这些基础运算。
所以在这个时候,如果我们用这些高级小学生来算的话,很明显就没有用这些普通小学生算的快。打个比方就是,找一个大学生和一百个小学生来写口算题卡,很明显小学生这队会写的比较快。
在我们的电脑内部,比如说是英伟达的显卡,则会有名为CUDA的驱动程序来专门进行这种在GPU上的加速,而Tensorflow本身又很好的提供了对于CUDA的支持,这也就导致了我们在使用Tensorflow的时候,可以极大的利用到我们GPU上这种对于机器学习模型计算加速的优势。
3. 关于反向传播
这一点虽然并不像上面两点那么有代表性,但也值得一说。
简单来说,大家都知道,对于神经网络的优化,BP算法有着很大的作用,而BP算法的一大核心就是 反向传播!
相比很多小伙伴在编程的初期都深受其害,我们到底要怎么实现反向传播这种看上去就超级麻烦的玩意呢??

好消息就是,对于类似Tensorflow这类的机器学习框架来讲,反向传播是自动实现的,只需要简简单单的几行代码就可以了:
# 那肯定不会写在这里呀
# 以后有机会应该会完整的写一下tf的教程吧
# 算了,简单举个例子就是大概这样:
# 。。。。
# 果然还是想不好举什么例子
# 下次,下次Pytorch的一定
那么以上就是Tensorflow的简单介绍了
你
了解了吗?
那么关于具体的安装流程,请参加下一期:
手把手教你配置Tensorflow开发环境(二)-十分钟配置本地Tensorflow, CUDA, cuDNN
照这个教程装不好,你来找我


















 547
547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









