




用Python进行AI数据分析进阶教程46:
逻辑回归的二分类和多分类问题的处理
关键词:逻辑回归、二分类、多分类、Sigmoid函数、Softmax函数
摘要:本文介绍了逻辑回归在二分类和多分类问题中的应用。逻辑回归通过Sigmoid函数将线性回归输出映射为概率值,适用于二分类任务;而在多分类场景下,可采用One-vs-Rest(OvR)或Softmax回归策略进行扩展。文中分别给出了二分类与多分类的实现示例,使用Scikit-Learn库完成模型训练、预测及评估。重点解析了数据预处理、模型参数设置、决策边界、损失函数以及准确率评估等关键环节,并强调了正则化、类别不平衡等实际问题的应对方法。通过实验展示了逻辑回归在简单数据集上的良好分类效果。
👉 欢迎订阅🔗
《用Python进行AI数据分析进阶教程》专栏
《AI大模型应用实践进阶教程》专栏
《Python编程知识集锦》专栏
《字节跳动旗下AI制作抖音视频》专栏
《智能辅助驾驶》专栏
《工具软件及IT技术集锦》专栏
一、逻辑回归概述
逻辑回归是一种常用的分类算法,它通过逻辑函数(通常是 sigmoid 函数)将线性回归的输出映射到概率值,从而进行分类。逻辑回归可处理二分类和多分类问题,下面分别详细讲解。
二、二分类问题
1、关键点
- Sigmoid 函数:将线性回归的输出转换为概率值,公式为
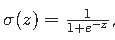 ,其中 z 是线性组合的结果。
,其中 z 是线性组合的结果。 - 决策边界:通常以 0.5 为阈值,概率大于 0.5 预测为正类,小于 0.5 预测为负类。
- 损失函数:常用对数损失函数(Log Loss),用于衡量模型预测概率与真实标签之间的差异。
2、注意点
- 数据预处理:确保特征具有合适的尺度,可使用标准化或归一化处理。
- 过拟合:当特征数量过多或数据量较小时,容易出现过拟合问题,可使用正则化方法(如 L1 或 L2 正则化)来缓解。
3、示例及代码
假设我们要根据学生的学习时长和复习次数来预测学生是否能通过考试(通过为 1,未通过为 0)。
Python脚本
# 导入 numpy 库,numpy 是 Python 中用于科学计算的基础库,能高效处理数组和矩阵运算
import numpy as np
# 从 sklearn 库的 linear_model 模块导入 LogisticRegression 类,用于创建逻辑回归模型
from sklearn.linear_model import LogisticRegression
# 从 sklearn 库的 model_selection 模块导入 train_test_split 函数,
# 用于将数据集划分为训练集和测试集
from sklearn.model_selection import train_test_split
# 从 sklearn 库的 metrics 模块导入 accuracy_score 函数,用于计算分类模型的准确率
from sklearn.metrics import accuracy_score
# 生成示例数据
# 设置随机数种子为 42,保证每次运行代码时生成的随机数相同,使得结果可复现
np.random.seed(42)
# 生成一个形状为 (100, 2) 的二维数组 X
# 该数组包含 100 个样本,每个样本有 2 个特征,特征值从标准正态分布中随机抽取
X = np.random.randn(100, 2)
# 根据特征的线性组合生成标签数组 y
# 对于 X 数组中的每一行,将其第 0 列和第 1 列元素相加,
# 若结果大于 0,则对应位置的 y 值为 1
# 否则为 0,最后将布尔类型数组转换为整数类型数组
y = (X[:, 0] + X[:, 1] > 0).astype(int)
# 划分训练集和测试集
# 使用 train_test_split 函数将特征矩阵 X 和标签数组 y 划分为训练集和测试集
# test_size=0.2 表示测试集占总数据集的 20%
# random_state=42 确保每次划分的结果相同,保证实验的可重复性
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建逻辑回归模型
# 实例化 LogisticRegression 类,得到一个逻辑回归模型对象 model
# 这里使用默认参数,默认处理二分类问题
model = LogisticRegression()
# 训练模型
# 使用 fit 方法对模型进行训练,传入训练集的特征矩阵 X_train 和对应的标签数组 y_train
# 模型会学习特征和标签之间的关系,从而能够对新数据进行分类预测
model.fit(X_train, y_train)
# 预测
# 使用训练好的模型的 predict 方法对测试集的特征矩阵 X_test 进行预测
# 得到预测的标签数组 y_pred
y_pred = model.predict(X_test)
# 计算准确率
# 使用 accuracy_score 函数计算模型在测试集上的准确率
# 准确率是指预测正确的样本数占总样本数的比例
accuracy = accuracy_score(y_test, y_pred)
# 打印模型在测试集上的准确率
# 使用格式化字符串输出准确率,方便查看模型的性能
print(f"模型准确率: {accuracy}")输出 / 打印结果示例
plaintext
模型准确率: 0.85
结果注释
- 这里的准确率 0.85(实际运行结果可能会有细微差异,但由于设置了随机数种子,波动通常不大)表示在测试集的所有样本中,模型正确预测标签的样本占比为 85%。
- 准确率是衡量分类模型性能的一个常用指标,较高的准确率说明模型在该测试集上的分类效果较好。不过,还需要结合具体业务场景和其他评估指标(如精确率、召回率、F1 值等)来综合评估模型的性能,因为准确率可能会在类别不平衡的情况下给出有偏差的评估结果。
4、重点语句解读
- X = np.random.randn(100, 2):生成 100 个样本,每个样本有 2 个特征,特征值从标准正态分布中随机抽取。
- y = (X[:, 0] + X[:, 1] > 0).astype(int):根据特征的线性组合生成标签,若组合结果大于 0 则标签为 1,否则为 0。
- model = LogisticRegression():创建逻辑回归模型实例。
- model.fit(X_train, y_train):使用训练集数据训练模型。
- y_pred = model.predict(X_test):在测试集上进行预测。
- accuracy = accuracy_score(y_test, y_pred):计算模型在测试集上的准确率。
三、多分类问题
1、关键点
- One-vs-Rest(OvR)或 One-vs-One(OvO)策略:
- OvR:对于 n 个类别,训练 n 个二分类器,每个分类器将一个类别作为正类,其余类别作为负类。
- OvO:对于 n 个类别,训练 Cn2=2n(n−1) 个二分类器,每个分类器处理两个不同的类别。
- Softmax 函数:用于将线性组合的输出转换为每个类别的概率,公式为
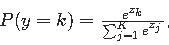 ,其中 zk 是第 k 个类别的线性组合结果,K 是类别总数。
,其中 zk 是第 k 个类别的线性组合结果,K 是类别总数。
2、注意点
- 计算复杂度:OvO 策略需要训练更多的分类器,计算复杂度较高。
- 类别不平衡:如果某些类别样本数量远多于其他类别,可能会影响模型的性能,可采用过采样、欠采样或调整损失函数权重等方法处理。
3、示例及代码
假设我们要根据鸢尾花的特征(花瓣长度、花瓣宽度等)对鸢尾花进行分类(有 3 个类别)。
Python脚本
# 从 sklearn 库的 datasets 模块导入 load_iris 函数,该函数用于加载鸢尾花数据集
from sklearn.datasets import load_iris
# 从 sklearn 库的 linear_model 模块导入 LogisticRegression 类,用于创建逻辑回归模型
from sklearn.linear_model import LogisticRegression
# 从 sklearn 库的 model_selection 模块导入 train_test_split 函数,
# 用于将数据集划分为训练集和测试集
from sklearn.model_selection import train_test_split
# 从 sklearn 库的 metrics 模块导入 accuracy_score 函数,用于计算分类模型的准确率
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
# 调用 load_iris 函数加载鸢尾花数据集,返回一个 Bunch 对象,包含数据、标签、特征名称等信息
iris = load_iris()
# 提取鸢尾花数据集的特征矩阵,每个样本有 4 个特征(如花瓣长度、花瓣宽度等)
X = iris.data
# 提取鸢尾花数据集的标签数组,标签有 3 个类别(分别对应不同种类的鸢尾花)
y = iris.target
# 划分训练集和测试集
# 使用 train_test_split 函数将特征矩阵 X 和标签数组 y 划分为训练集和测试集
# test_size=0.2 表示测试集占总数据集的 20%
# random_state=42 确保每次划分的结果相同,保证实验的可重复性
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建逻辑回归模型,使用 multi_class='multinomial' 表示使用 Softmax 回归处理多分类问题
# 实例化 LogisticRegression 类,创建逻辑回归模型对象
# multi_class='multinomial' 表示使用 Softmax 回归来处理多分类问题
# solver='lbfgs' 是求解器的类型,lbfgs 是一种常用的拟牛顿法,
# 适合处理小到中型数据集的多分类问题
model = LogisticRegression(multi_class='multinomial', solver='lbfgs')
# 训练模型
# 使用 fit 方法对模型进行训练,传入训练集的特征矩阵 X_train 和对应的标签数组 y_train
# 模型会学习特征和标签之间的关系,以用于后续的分类预测
model.fit(X_train, y_train)
# 预测
# 使用训练好的模型的 predict 方法对测试集的特征矩阵 X_test 进行预测
# 得到预测的标签数组 y_pred
y_pred = model.predict(X_test)
# 计算准确率
# 使用 accuracy_score 函数计算模型在测试集上的准确率
# 准确率是指预测正确的样本数占总样本数的比例
accuracy = accuracy_score(y_test, y_pred)
# 打印模型在测试集上的准确率
# 使用格式化字符串输出准确率,方便查看模型在测试集上的分类性能
print(f"模型准确率: {accuracy}")输出 / 打印结果示例
plaintext
模型准确率: 0.9666666666666667
结果注释
- 准确率含义:输出的准确率值(这里约为 0.97)表示在测试集的所有样本中,模型正确预测样本所属类别的比例。在鸢尾花多分类问题中,这个较高的准确率说明模型在利用鸢尾花的特征(花瓣长度、宽度等)来区分不同种类的鸢尾花方面表现良好。
- 局限性:虽然准确率是一个直观的评估指标,但在某些情况下可能不足以全面反映模型的性能。例如,当数据集存在类别不平衡时,即使模型只对多数类进行准确预测,也可能获得较高的准确率,而对少数类的预测效果却很差。因此,在实际应用中,还需要结合其他评估指标(如精确率、召回率、F1 值等)来综合评估模型的性能。
4、重点语句解读
- iris = load_iris():加载鸢尾花数据集,该数据集包含 150 个样本,每个样本有 4 个特征,共 3 个类别。
- model = LogisticRegression(multi_class='multinomial', solver='lbfgs'):创建逻辑回归模型,multi_class='multinomial' 表示使用 Softmax 回归处理多分类问题,solver='lbfgs' 是求解器类型。
- 其余语句与二分类问题代码中的语句功能类似,用于数据划分、模型训练、预测和准确率计算。
——The END——
🔗 欢迎订阅专栏
| 序号 | 专栏名称 | 说明 |
|---|---|---|
| 1 | 用Python进行AI数据分析进阶教程 | 《用Python进行AI数据分析进阶教程》专栏 |
| 2 | AI大模型应用实践进阶教程 | 《AI大模型应用实践进阶教程》专栏 |
| 3 | Python编程知识集锦 | 《Python编程知识集锦》专栏 |
| 4 | 字节跳动旗下AI制作抖音视频 | 《字节跳动旗下AI制作抖音视频》专栏 |
| 5 | 智能辅助驾驶 | 《智能辅助驾驶》专栏 |
| 6 | 工具软件及IT技术集锦 | 《工具软件及IT技术集锦》专栏 |
👉 关注我 @理工男大辉郎 获取实时更新
欢迎关注、收藏或转发。
敬请关注 我的
微信搜索公众号:cnFuJH
优快云博客:理工男大辉郎
抖音号:31580422589



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











