





 超级会员免费看
超级会员免费看

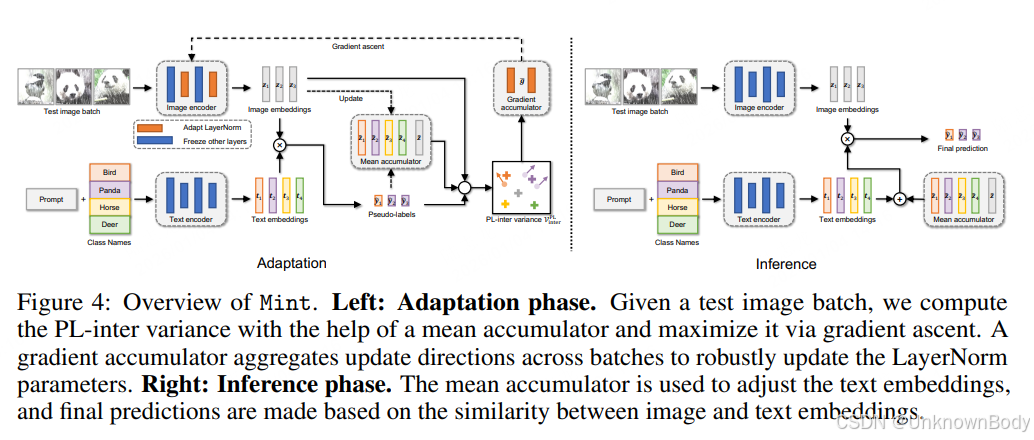
文章核心总结与翻译
一、主要内容
文章聚焦视觉语言模型(如CLIP)在输入损坏场景下的性能退化问题,提出“嵌入方差坍缩”现象——随着损坏程度增加,图像嵌入的类内和类间方差均会缩小,导致类别区分度下降。通过理论分析,揭示该现象源于视觉编码器会编码损坏相关信号,稀释类别判别特征。基于此,设计了测试时自适应方法Mint,通过均值累加器和梯度累加器实时最大化伪标签类间方差,在极小批量场景下仍能有效工作,显著提升模型在多种损坏基准上的鲁棒性和效率。
二、创新点
- 首次发现CLIP图像嵌入中的“方差坍缩”现象,证实类间方差与分类准确率高度相关(相关系数达0.98)。
- 提供理论分析,阐明损坏如何改变嵌入空间结构,且证明即使使用伪标签,最大化类间方差也能提升嵌入质量。
- 提出Mint方法,通过双累加器结构解决小批量场景下的方差估计噪声问题,无需全量测试数据即可实现高效自适应。
- 在多个损坏基准和CLIP架构上验证,Mint在准确率和效率上均优于现有测试时自适应方法,且对超参数不敏感。
三、核心部分翻译(Markdown格式)
Abstract
预训练视觉语言模型(如CLI

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 4406
4406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











