





 超级会员免费看
超级会员免费看


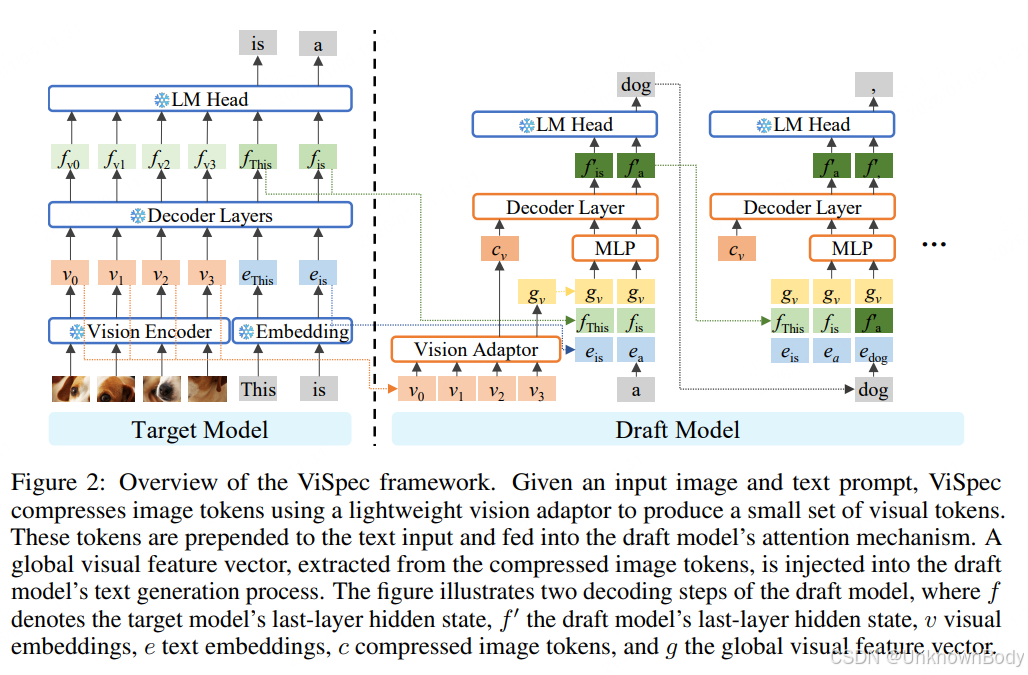
一、文章主要内容总结
该研究聚焦于视觉语言模型(VLMs)推理加速问题,针对现有推测解码技术在VLMs中仅能实现有限加速(<1.5倍)的痛点,提出了专为VLMs设计的视觉感知推测解码框架(ViSpec)。
核心思路是解决视觉数据冗余与模态一致性难题:通过轻量级视觉适配模块压缩图像令牌,提取全局视觉特征并注入文本生成过程,同时构建含长响应的合成训练数据集,让小型草稿模型能有效利用视觉上下文进行预测。
实验验证显示,ViSpec在LLaVA-1.6(7B/13B)、Qwen2.5-VL(3B/7B)四款主流VLMs上,在8个多模态基准任务(含视觉问答、图像描述等)中实现1.37-3.22倍的显著加速,且不损失生成质量,首次实现了VLMs推测解码的实质性提速。
二、文章创新点
- 视觉感知推测解码框架:提出ViSpec,专为VLMs设计双集成机制——注意力集成(将压缩图像令牌融入草稿模型注意力层)和特征增强(全局视觉特征注入文本令牌),解决小型草稿模型难以处理视觉信息的问题。
- 图像令牌压缩与全局特征提取:设计轻量级视觉适配模块,将大量冗余图像令牌压缩为紧凑表示(保留空间位置信息);提取全局视觉特征向量,持续注入文本生成过程,缓解“中间遗忘”效应,增强模态一致性。
- 长响应数据集生成策

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 2008
2008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











