







 超级会员免费看
超级会员免费看
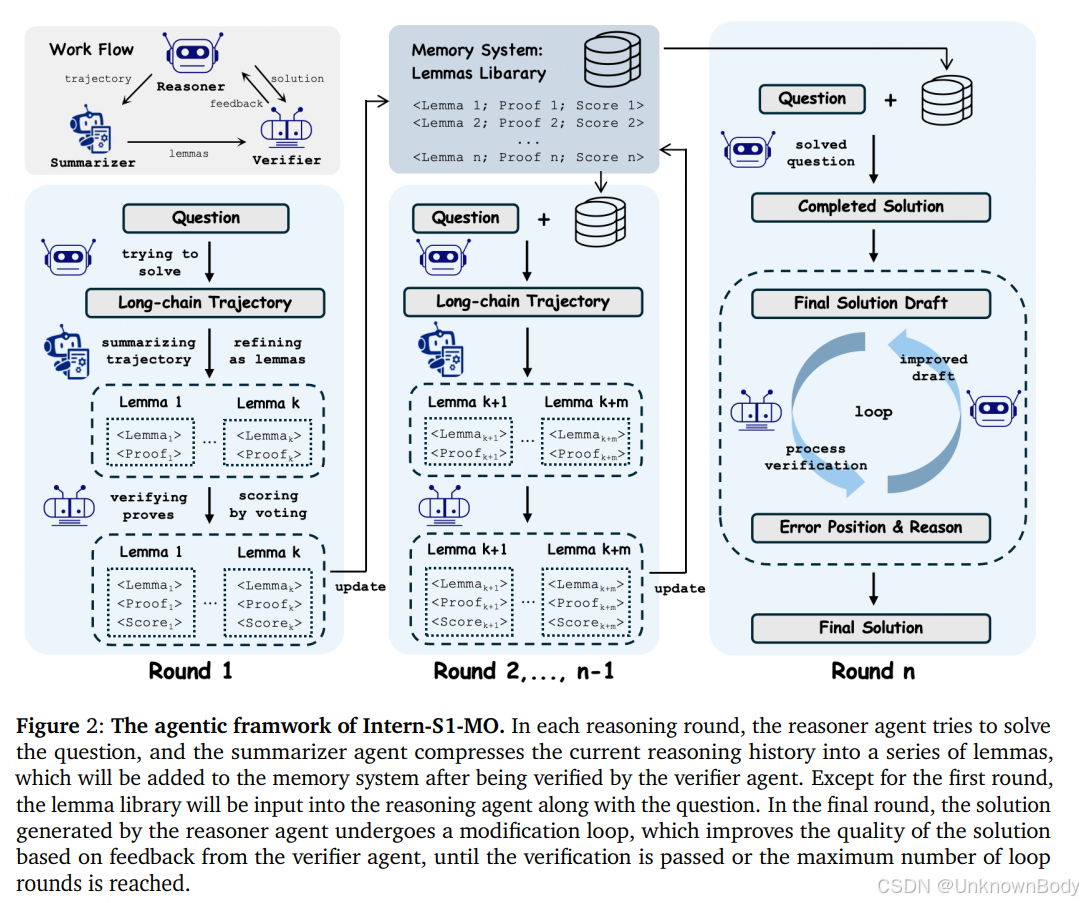
文章核心总结与翻译
一、主要内容
本文针对大型推理模型(LRMs)在解决国际数学奥林匹克(IMO)等超难题时受限于上下文长度的核心瓶颈,提出了多智能体系统Intern-S1-MO和强化学习框架OREAL-H,主要内容如下:
- 问题背景:现有LRMs虽能通过CoT、RLVR等技术解决AIME级问题,但上下文长度(通常64k/128k tokens)无法满足IMO级问题的复杂推理需求,且现有方法多基于提示工程或专有模型,缺乏系统结构和训练流程。
- 核心方案:
- Intern-S1-MO系统:由推理、总结、验证三大智能体组成,通过"引理记忆管理"实现多轮分层推理。每轮推理后将历史推理压缩为结构化引理存入记忆库,突破上下文限制,仅对难题启动多轮探索以优化资源分配。
- OREAL-H训练框架:基于分层马尔可夫决策过程(MDP),利用在线探索轨迹训练LRM,通过引理依赖图实现进度条件优势估计,结合共轭奖励模型处理验证噪声,提升推理精度和系统性能。
- 实验成果:
- 在AIME2025、HMMT2025等基准测试中,pass@1分数分别达96.

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











