







 超级会员免费看
超级会员免费看
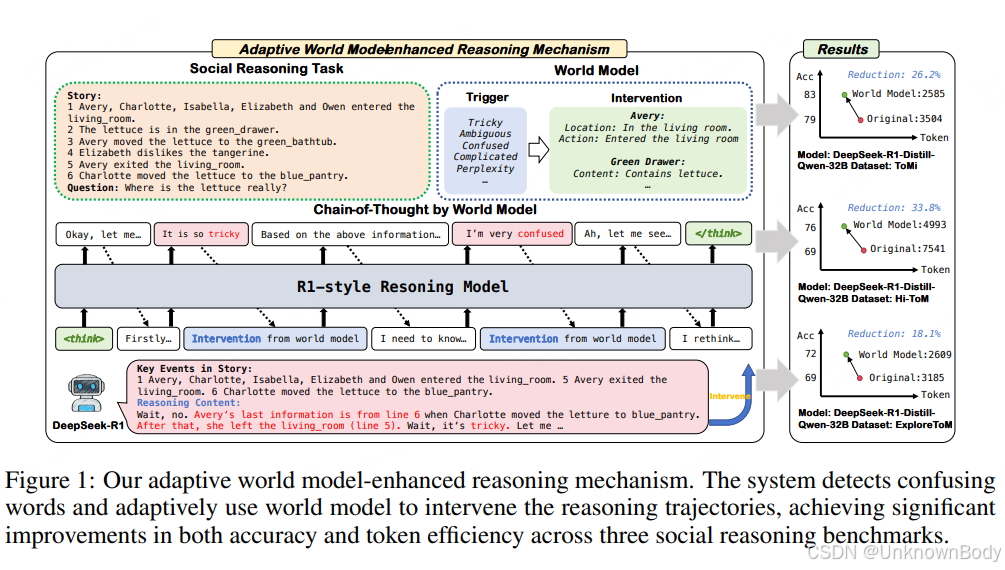
这篇文章对LLMs社交推理能力的研究很有针对性,精准指出了模型在区分客观状态与主观信念上的核心痛点,并提出了切实可行的解决方案。文章核心是通过构建自适应世界模型,解决LLMs在社交推理中的认知混乱问题,同时提升准确率与降低计算成本。
一、文章主要内容总结
- 研究背景与问题
- LLMs在数学、代码推理上表现优异,但在社交推理任务中存在明显缺陷,包括认知混乱(如处理多时间线时)、逻辑不一致(分析复杂人物关系时),以及混淆客观世界状态(如物体移动、人物离开)与主观信念状态(如人物对事件的认知)。
- 通过分析DeepSeek-R1的推理轨迹发现,模型在处理多参与者、多时间线场景时,常输出“tricky”“confused”等矛盾词汇,陷入推理僵局或无限循环,核心原因是无法区分客观现实与主体主观信念。
- 提出的解决方案:自适应世界模型增强推理机制
- 触发机制:实时监测模型推理轨迹中的混乱词汇(如“ambiguous”“perplexed”等),一旦检测到则激活世界状态干预。
- 干预过程:干预触发后,模型暂停当前混乱推理,从动态构建的文本世界模型中提取实体状态(如物体位置)、人物状态(如所在场景)和时间线信息,插入推理

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











