








 超级会员免费看
超级会员免费看

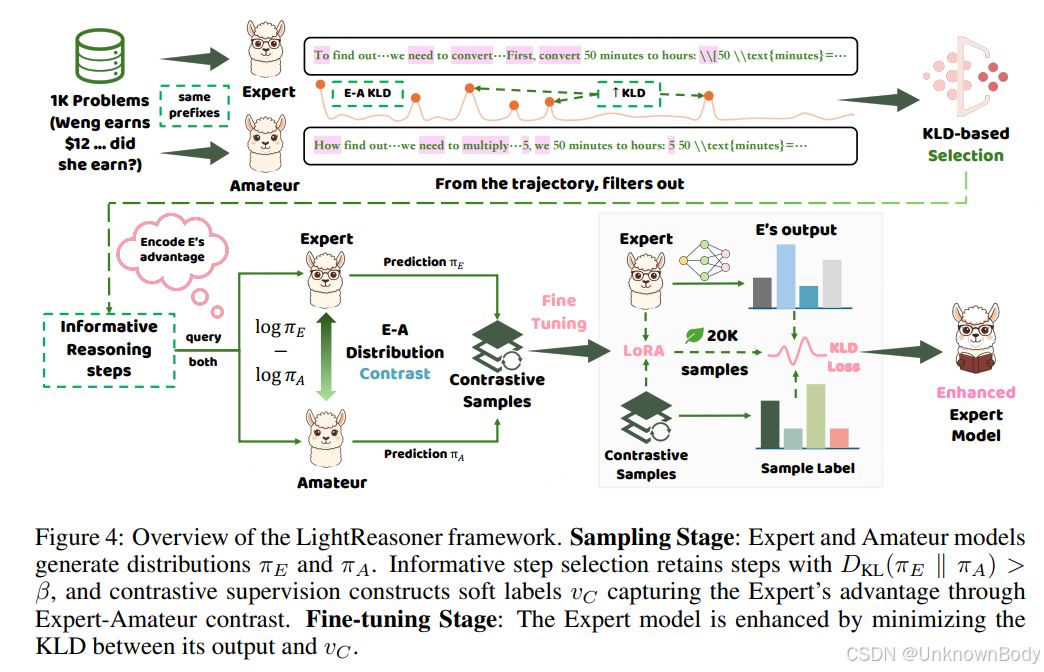
一、文章主要内容总结
LightReasoner是一个利用小型语言模型(SLM,扮演“ Amateur 模型”)指导大型语言模型(LLM,扮演“ Expert 模型”)提升推理能力的框架,核心是通过捕捉两模型的行为差异,定位高价值推理时刻,实现高效微调。
- 研究背景:传统监督微调(SFT)提升LLM推理能力时,依赖大规模人工标注数据、拒绝采样演示,且对所有token均匀优化,资源消耗大,而仅少数token具有实际学习价值。
- 核心思路:LLM与SLM在推理过程中存在行为差异,这些差异对应的时刻往往是关键推理步骤。通过量化这种差异(用KL散度),筛选出高价值推理步骤,构建对比监督信号,再用这些信号微调LLM,强化其推理优势。
- 框架流程
- 采样阶段:让Expert和Amateur在相同前缀下生成下一个token的预测分布,筛选出KL散度超过阈值的步骤,构建包含Expert优势的监督样本。
- 微调阶段:用筛选出的监督样本微调Expert模型,提高其在优势token上的概率,避免Amateur式的错误倾向。
- 实验结果:在7个数学推理基准测试中,LightRe

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 642
642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











