








 超级会员免费看
超级会员免费看

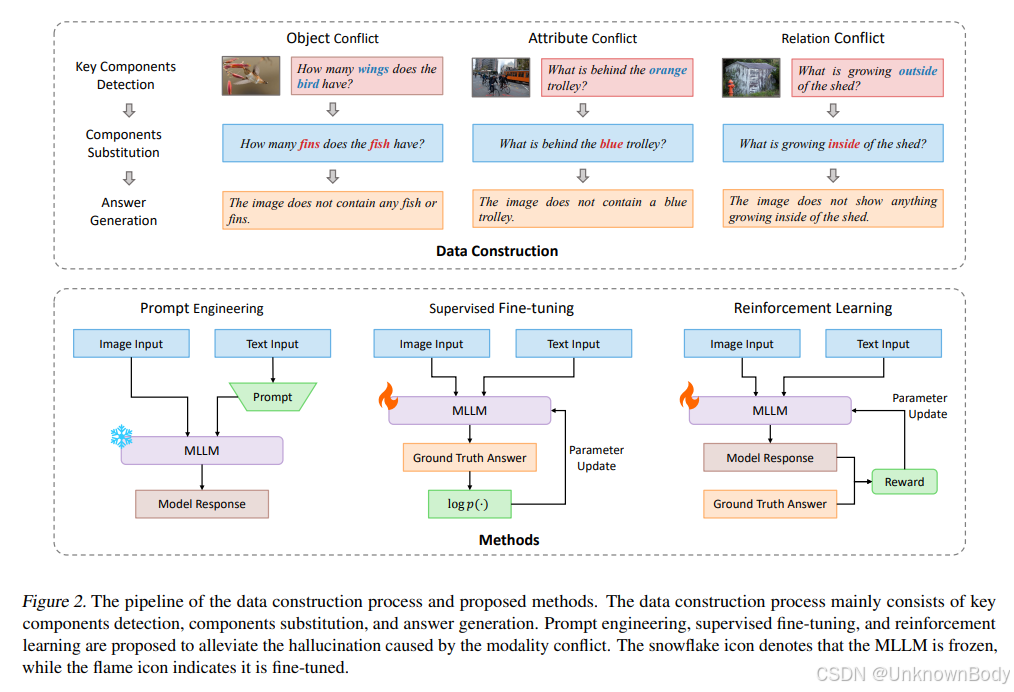
文章主要内容总结
本文聚焦多模态大语言模型(MLLMs)在视觉-语言任务中因模态冲突导致的幻觉问题,主要内容如下:
- 模态冲突的定义:指视觉输入与文本输入在信息上存在不一致,具体分为三类——物体冲突(文本提及的物体不在图像中)、属性冲突(文本与图像对同一物体的属性描述不一致)、关系冲突(文本与图像对同一物体间关系的描述不一致)。
- 数据集构建:构建了Multimodal Modality Conflict(MMMC)数据集,包含20K个图像-问题-答案三元组,用于模拟上述三种模态冲突场景。
- 缓解方法:提出三种缓解模态冲突导致幻觉的方法——
- 提示工程:通过特定提示引导模型先检查输入信息一致性再回答;
- 有监督微调:在MMMC数据集上以语言建模目标微调模型;
- 强化学习:将任务建模为马尔可夫决策过程,基于奖励函数(鼓励与标注答案语义一致的输出)优化模型。
- 实验结果:在MMMC数据集上的实验表明,强化学习在缓解模态冲突导致的幻觉方面表现最佳,有监督微调表现稳定且前景良好;多数现有MLLMs在模态冲突下易产生幻觉,三种方法均能显著提升模型鲁棒性。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 640
640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











