 DisTime框架助力视频大语言模型时间表示
DisTime框架助力视频大语言模型时间表示









 超级会员免费看
超级会员免费看

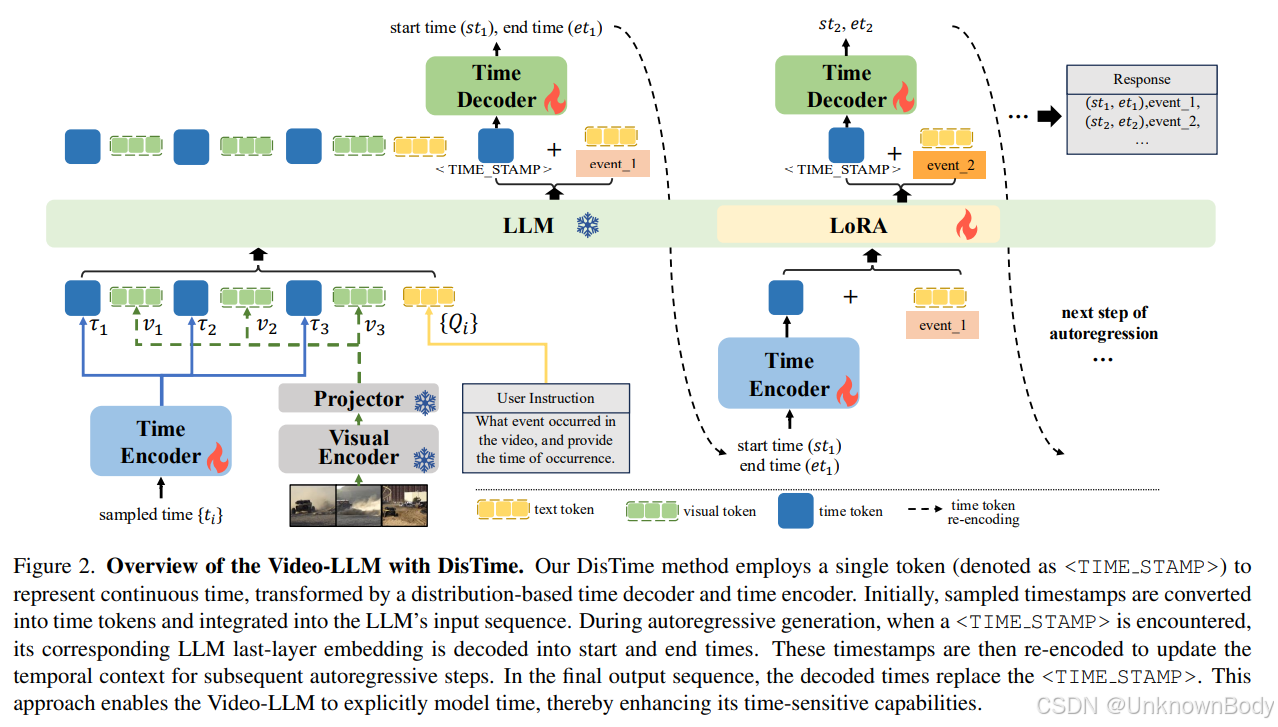
文章主要内容和创新点总结
主要内容
- 研究背景
- 视频大语言模型(Video-LLMs)在时间敏感任务(如时刻检索、密集视频字幕、接地视频问答)中面临离散时间表示和时间感知数据集有限的挑战。
- 现有方法存在三大问题:
- 文本-数字混合表示(如GroundingGPT)导致分类混淆;
- 专用时间标记(如Momentor)受长尾分布和时间不连续性影响;
- 重型时间模块(如InternVideo2.5)增加计算成本且依赖视觉信息重输入。
- DisTime框架
- 核心设计:引入可学习时间标记
<TIME_STAMP>,通过**基于分布的时间解码器(Distribution-based Time Decoder)将标记转换为连续时间概率分布,解决边界模糊问题;利用时间编码器(Time
- 核心设计:引入可学习时间标记

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 793
793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











