








 超级会员免费看
超级会员免费看

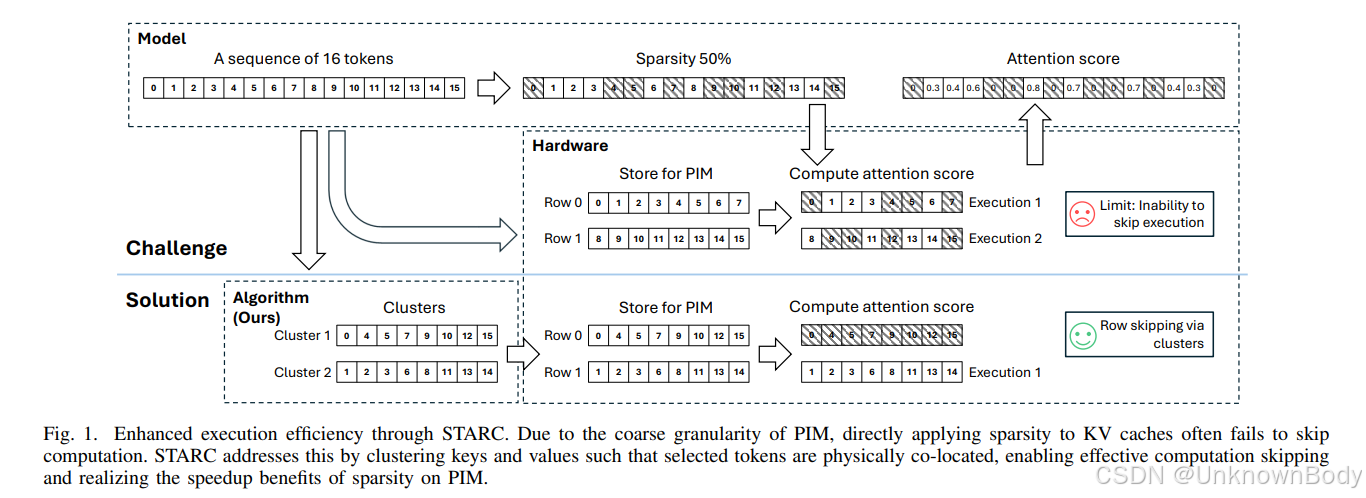
1. 核心问题
- 内存带宽瓶颈:传统GPU架构在处理长上下文LLM的注意力计算时,由于内存访问频繁且计算与带宽不匹配,导致性能受限。
- PIM架构的局限性:现有PIM设计主要针对密集注意力优化,难以应对动态、不规则的KV缓存稀疏访问模式,导致工作负载不平衡,降低吞吐量和资源利用率。
- 稀疏注意力的挑战:
- Token级稀疏性:细粒度访问与PIM的行级内存粒度不匹配,导致大量无效数据读取。
- 页级稀疏性:基于位置的分页策略虽对齐硬件,但包含大量无关Token,影响模型精度。
2. STARC方案设计
- 语义聚类与内存重映射:
- 基于余弦相似度对KV对进行K-means聚类,将语义相似的Token物理存储在连续内存区域,对齐PIM的存储Bank结构。
- 解码时通过查询与预计算的簇质心匹配,以簇为粒度检索相关Token,避免频繁重聚类和数据移动开销。
- 在线增量聚类

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1612
1612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











