








 超级会员免费看
超级会员免费看

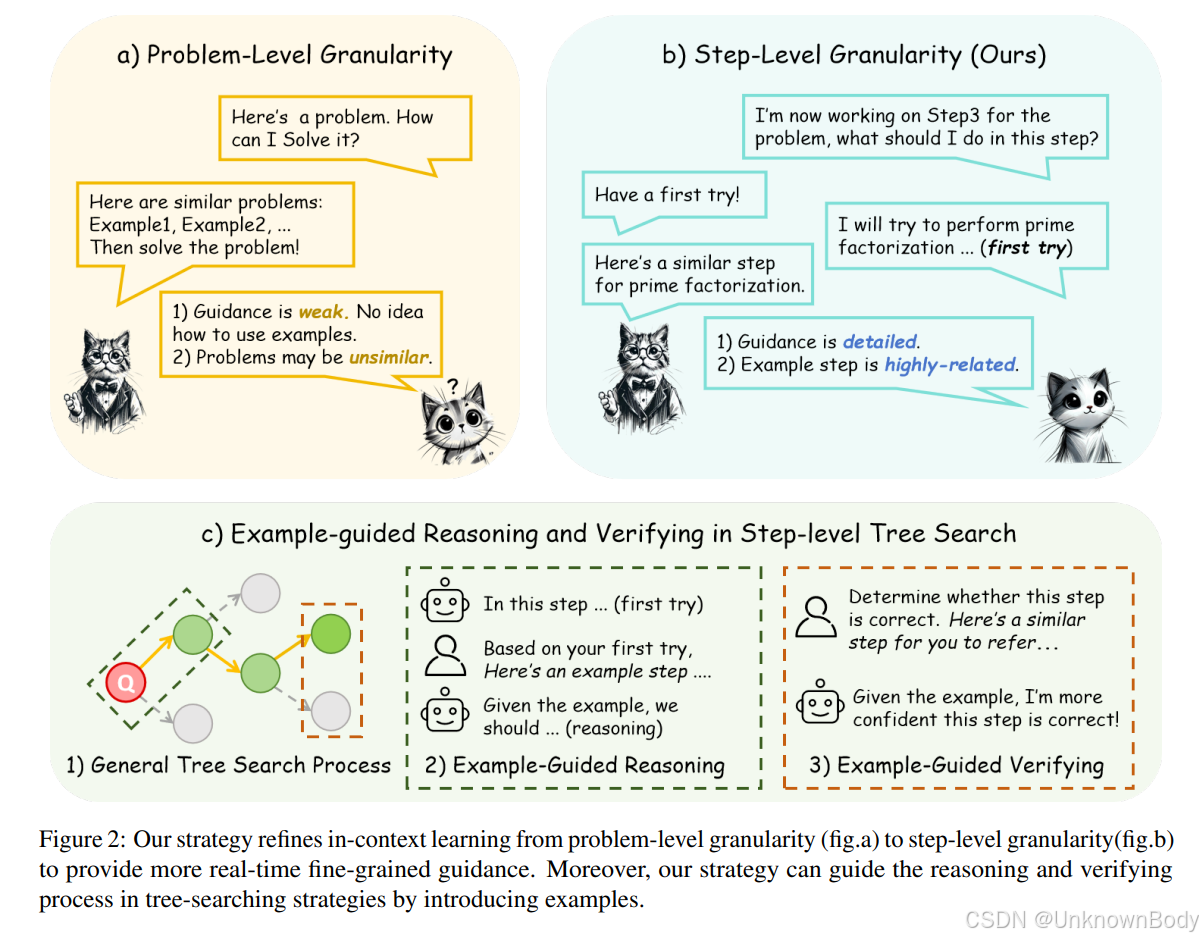
主要内容
- 研究背景:数学推理是人工智能发展中的关键任务,大语言模型(LLMs)在解决复杂数学问题时采用多步推理策略,但单步推理错误是其推理能力的瓶颈。上下文学习(ICL)可通过提供相似示例指导模型,但传统问题级ICL存在粒度不匹配和信息无关等问题。
- 相关工作:介绍数学推理领域的研究进展,包括早期基于规则的方法和当代利用大语言模型的方法;阐述步级数学推理和数学推理中上下文学习的研究现状及存在的不足。
- 步级上下文学习
- 从条件概率重新审视上下文学习:分析当前模型训练和推理中基于条件概率的原理,指出问题级检索示例在步级推理中的不足,提出步对齐上下文学习和首次尝试策略。
- 步级示例题库:强调现有开源数学数据在步级分解上的不足,建议由推理模型自主分解示例问题,构建基于推理内容的步级题库,以实现更有效的步级检索和指导。
- 带有首次尝试策略的步级ICL:提出首次尝试策略,让模型先尝试推理下一步,再根据尝试结果检索相似步骤,同时引入参考拒绝策略,提高检索相关性和推理有效性。
- 树搜索中的步级指导:步级上下文学习可增强模型单步推理能力,能集成到常见的

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











