








 超级会员免费看
超级会员免费看

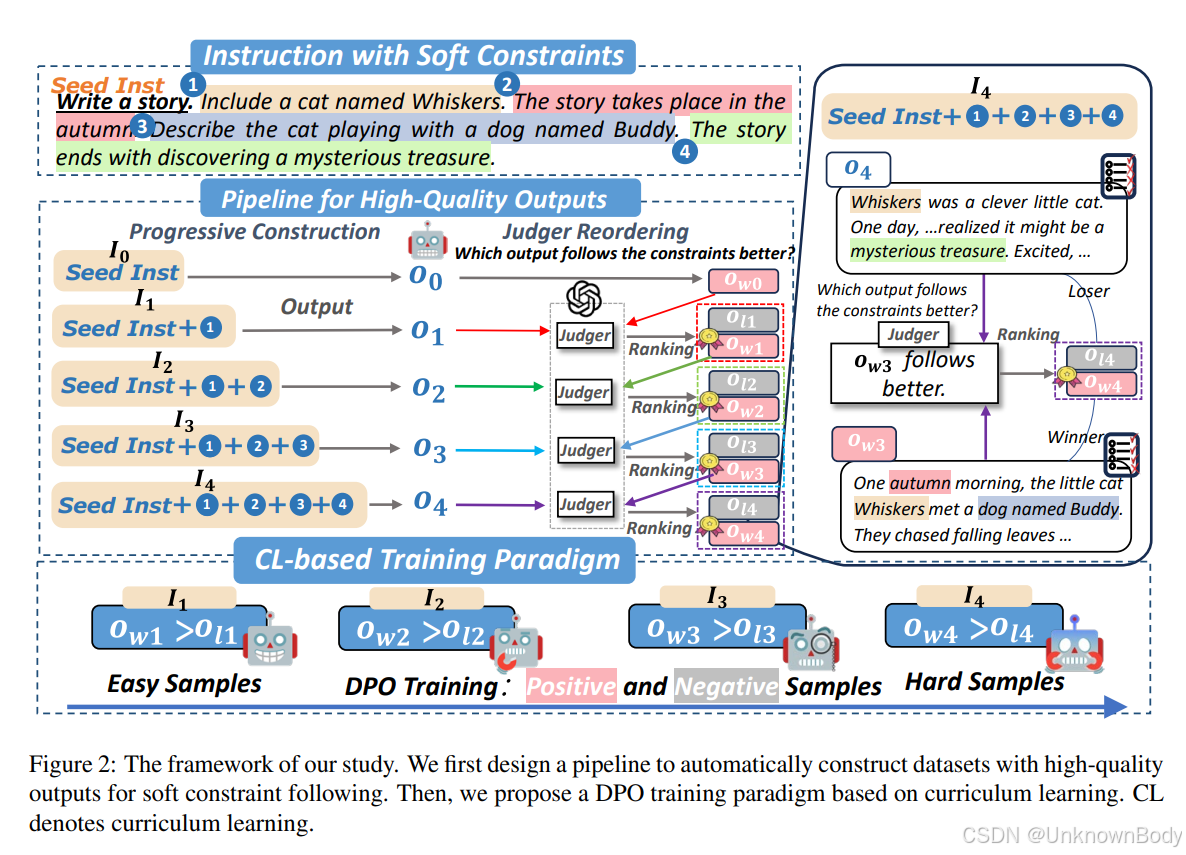
文章主要内容
- 研究背景:大语言模型(LLMs)遵循多约束指令的能力至关重要,尤其是在涉及软约束时,但提升LLMs遵循软约束的能力尚未得到充分探索。现有研究在构建数据集、训练方法和考虑约束难度方面存在局限性。
- 相关工作:介绍了软约束遵循的现有研究,主要集中在评估LLMs的能力;还介绍了课程学习的两种主要范式,而本文基于约束数量组织课程。
- 方法
- 数据集构建:采用渐进式构建和Judger重排序两步法。渐进式构建从三个来源收集种子指令,逐步添加约束生成多约束指令;Judger重排序根据约束遵循程度对输出进行排序,得到高质量的正负样本集。
- 课程学习训练范式:应用直接偏好优化(DPO)作为训练方法,基于指令中的约束数量建立课程学习训练范式,让模型从简单任务逐步学习到复杂任务,并混合ShareGPT示例防止灾难性遗忘。
- 分析与比较:对不同课程进行数据统计,分析约束数量、指令长度和动词频率等;与其他相关工作对比,突出本文数据集规模大、约束类型多样、经Judger重排序和渐进式构建的优势。
- 实验

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 198
198

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











